Архитектура Е2К
Подход, близкий к IA-64, уже был реализован в России - в произведенном в единственном экземпляре суперкомпьютере Эльбрус-3, выпущенном в 1991 году.
В E2K используются команды переменной длины. Общий формат команд E2K представлен в таблице 12.1.
| Заголовок | Слог 1 | ... | Слог N |
Команда E2K состоит из слогов длиной 32 разряда каждый. Число этих слогов может меняться от 2 до 16, причем данную архитектуру можно еще расширить - до 32 слогов.
Любая команда всегда включает 1 слог заголовка и еще от 1 до 15 слогов, указывающих на операции, которые могут выполняться параллельно. Слог заголовка содержит информацию о структуре команды и ее длине, что облегчает дешифрацию команды переменной длины. Применение заголовка позволяет не проводить предварительного декодирования команд перед их помещением в кэш команд.
В архитектуре E2K представлен сверхбольшой файл регистров. Все регистры E2K являются универсальными и могут содержать как целочисленные данные, так и числа с плавающей запятой. Всего имеется 256 регистров длиной по 64 разряда каждый.
В E2K есть два почти симметричных кластера, каждый из которых содержит по 256 регистров. Всего в этом процессоре имеется 30 регистровых портов: 20 портов чтения (по 10 портов на кластер) и 10 портов записи.
В Alpha 21264 применяется реализованное во многих суперскалярных процессорах динамическое переименование регистров. Этого механизма в E2K нет, так как в нем подобные задачи возлагаются на компилятор. Однако в циклах с постоянным шагом используется аналогичная схема циклической замены используемых регистров.
Еще одна особенность E2K - регистровое окно для процедуры. Это решение стало традиционным для машин серии "Эльбрус", однако особенно важным оно является для E2K, поскольку он содержит сверхбольшое количество регистров - 256.
Затраты на сохранение/восстановление регистров в данной ситуации становятся весьма значительными. Поэтому реализация в E2K аппаратного механизма переключения окон представляется актуальной.
Окно регистров в E2K имеет переменную длину (до 192 регистров). Адресация регистров внутри контекста происходит относительно текущей базы, и при вызове другой процедуры достаточно сменить значение базы.
Кэш данных первого уровня в E2K имеет емкость всего 8 Кбайт и продублирован в каждом из кластеров. Этот кэш является прямоадресуемым, использует алгоритм сквозной записи данных.
Кэш данных второго уровня в E2K имеет емкость 256 Кбайт при времени доступа в 8 тактов. Он является двухканальным частично-ассоциативным и имеет 4 банка, то есть обеспечивает 4-кратное расслоение кэш-памяти. В кэше данных второго уровня применяется алгоритм обратной записи. Он также является неблокирующим.
Кроме этого, в E2K представлен специализированный кэш предварительной выборки, который разработчики назвали буфером предварительной подкачки. Он является частью устройства доступа к массивам и задействуется только при работе с массивами в циклах. Его емкость составляет всего 4 Кбайт, и он состоит из 2 банков с 2 портами в каждом из них. За один такт в буфер можно считать, следовательно, до 4 слов длиной 8 байт. Буфер организован как очередь FIFO и имеет до 64 зон предварительной выборки.
В Е2К предусматриваются два варианта подключения третьего уровня кэш: непосредственно к процессору Е2К, что позволяет разгрузить "системную шину" - коммутатор, или через набор коммутаторных микросхем.
Функциональные устройства (ФУ) E2K разнесены по двум кластерам. Эти кластеры содержат по 3 одинаковых целочисленных конвейера - АЛУ (правда, один из кластеров имеет также ФУ деления - целочисленного и с плавающей запятой).
В каждом кластере представлены также адресные сумматоры, которые имеются для 2 из 3 путей ("каналов") данных. В результате каждый кластер может одновременно выполнять до 2 операций загрузки регистров или 1 операцию записи в оперативную память. Возможен и смешанный случай: 2 загрузки плюс одна запись.
Кроме того, имеется 4 канала для данных с плавающей запятой, по 2 на кластер.
В каждом канале может выполняться команда типа MADD - "умножить-и-сложить", что дает темп 8 результатов с плавающей запятой за такт.
Сам набор команд E2K "богаче", чем у традиционных RISC-процессоров: в нем представлены четырехадресные команды, например, типа d = a + b + c. Такого нет и в IA-64. Что касается команд с плавающей запятой, то кроме полной поддержки IEEE754 в E2K реализована работа с 80-разрядным представлением Intel x86. При этом операнды хранятся в парах 64-разрядных регистров E2K. Правда, сложение/умножение таких чисел не полностью конвейеризовано. Кроме того, для приближения системы команд E2K к x86 в E2K реализованы также команды расширения ММХ.
В E2K целочисленный конвейер имеет длину 8 тактов (собственно выполнение идет на седьмом такте, а обратная запись - на восьмом) против 7 тактов в Alpha 21264.
Е2К обеспечивает очень высокий уровень одновременно выполняемых операций: в команде их кодируется до 23 (сюда, кроме арифметико-логических операций, входят также доступ в оперативную память, приращение индекса массива и т.п.). Эффективные показатели параллельной работы ФУ у E2K выше, чем у всех суперскалярных процессоров.
В архитектуре E2K, как и в IA-64, делается все, чтобы по возможности исключить обычные операции перехода. Для этого в E2K имеется 32 одноразрядных регистра-предиката, причем команда способна сформировать до 7 предикатов: 4 в операциях сравнения в АЛУ и еще 3 - в операциях логики.
Хотя в IA-64 предикатных регистров формально в 2 раза больше, чем в E2K, реально их столько же, так как в IA-64 хранятся пары - предикат и его отрицание. В IA-64 поля предикатов всегда представлены в команде, а в E2K - могут отсутствовать. Предикаты могут использоваться в канале АЛУ или в канале доступа к массивам; для указания на это применяются условные слоги, содержащие маски предикатов и ФУ. Всего в этих слогах может кодироваться до 6 предикатов, указывающих на то, нужно ли выполнять соответствующие операции из "широкой" команды.
Компилятор E2K порождает коды для обеих ветвей программы, возникающих при условном переходе, и, пользуясь большим числом ФУ и регистров, заставляет процессоры выполнять обе ветви программы. Та же процедура применяется и в IA-64. До тех пор, пока условие перехода остается неизвестным, обе ветви выполняются спекулятивно. Когда, наконец, условие найдено, выбираются нужные результаты. Признак спекулятивного выполнения взводится при этом в специальном бите в коде операции в соответствующем слоге. При возникновении ситуации исключения (exception) результат снабжается тегом недействительного значения.
В файле предикатов E2K, как и в регистровом файле, используются окна.
Еще некоторые особенности архитектуры E2K:
тегирование данных, поддерживаемое во всей линейке процессоров ЭВМ "Эльбрус"; сегментно-страничная организация памяти; поддержка мультипрограммирования в стиле x86. В сочетании с разработанными средствами двоичной компиляции и специальными аппаратными средствами ее поддержки, это позволяет выполнять x86-коды на E2K.
Поддерживается также двоичная компиляция для SPARC-архитектуры.
два нововведения по сравнению
В IA- 64 два нововведения по сравнению с RISC-процессорами:
Применение технологии явного параллелизма на уровне команд (EPIC - Explicitly Parallel Instruction Computing).Применение предикатных вычислений. Предикаты - способ обработки ветвлений (условных переходов).
В сочетании с новым уровнем спекулятивных вычислений это значительно уменьшает количество условных переходов и, соответственно, ошибочных предсказаний направления переходов. В свою очередь, применение EPIC однозначно диктует появление в архитектуре большого числа ФУ и сверхбольших файлов регистров.
Особенности EPIC:
Большое количество регистров.Масштабируемость архитектуры до большого количества функциональных устройств. Это свойство представители фирмы Intel и HP называют "наследственно масштабируемый набор команд".Явный параллелизм в машинном коде. Поиск зависимостей между командами производит не процессор, а компилятор.Предикация. Команды из разных ветвей условного ветвления снабжаются предикатными полями (полями условий) и запускаются параллельно.Загрузка по предположению. Данные из медленной основной памяти загружаются заранее.
особые поля для вещественной
Регистры IA-64: 128 64-разрядных регистров общего назначения;128 80-разрядных регистров вещественной арифметики;64 1-разрядных предикатных регистров. Формат команды IA-64: идентификатор команды;три 7-разрядных поля операндов - 1 приемник и 2 источника; особые поля для вещественной и целой арифметики;6-разрядное предикатное поле (64=2^6).Предикация.Загрузка по предположению.
VLIW архитектура
Предложенные в IA-64 архитектурные идеи близки к концепции VLIW (Very Large Instruction Word - сверхбольшое командное слово).
VLIW - это набор команд, реализующий горизонтальный микрокод. Несколько (4-8) простых команд упаковываются компилятором в длинное слово. Такое слово соответствует набору функциональных устройств. VLIW-архитектуру можно рассматривать как статическую суперскалярную архитектуру, поскольку распараллеливание кода производится на этапе компиляции, а не динамически во время исполнения. То есть в машинном коде VLIW присутствует явный параллелизм.
Хотя идеи VLIW сформулированы уже давно, до настоящего времени они были известны в основном специалистам в области компьютерных архитектур. Имеющиеся реализации, например, VLIW Multiflow, не получили широкого распространения. Пожалуй, единственными популярными процессорами, архитектура которых близка к VLIW, была линия AP-120B/FPS-164/FPS-264 компании Floating Point Systems. Эти процессоры в 1980-е годы активно применялись при проведении научно-технических расчетов.
Команда в этих системах содержала ряд полей, каждое из которых управляло работой отдельного блока процессора, так что все командное слово определяло поведение всех блоков процессора. Однако длина команды в FPS-х64 была равна всего 64 разрядам, что по современным меркам никак нельзя отнести к сверхбольшим.
Выделение в архитектуре VLIW компонентов командного слова, управляющих отдельными блоками МП, вводит явный параллелизм на уровне команд. Задача обеспечения эффективного распараллеливания работы отдельных блоков возлагается при этом на компилятор, который должен сгенерировать машинные команды, содержащие явные указания на одновременное исполнение операций в разных блоках. Таким образом, достижение параллелизма, обеспечиваемое в современных суперскалярных RISC-процессоров их аппаратурой, в VLIW возлагается на компилятор. Очевидно, что это вызывает сложные проблемы разработки соответствующих компиляторов. При этом распараллеливание работы между ФУ в EPIC происходит статически при компиляции, в то время как современные суперскалярные RISC-процессоры осуществляют это динамически.
Что представляют собой команды переменной
Каковы основные особенности VLIW-архитектуры?Что нового появилось в архитектуре IA - 64 по сравнению с RISC процессорами?Каковы архитектурные особенности EPIC? Что представляют собой команды переменной длины? Где они используются?Перечислите особенности архитектуры E2K.
Обработка прерываний на основе контроллера 8259A
Контроллер прерываний 8259A представляет собой устройство, реализующее до восьми уровней запросов на прерывания, с возможностью программного маскирования и изменения порядка обслуживания прерываний.
Контроллер прерываний (рис. 13.3) состоит из следующих блоков:
RGI - регистр запретов прерываний; хранит все уровни, на которые поступают запросы IRQx.PRB - схема принятия решений по приоритетам; схема идентифицирует приоритет запросов и выбирает запрос с наивысшим приоритетом.ISR - регистр обслуживаемых прерываний; сохраняет уровни запросов прерываний, находящиеся на обслуживании контроллера прерываний.RGM - регистр маскирования прерываний; обеспечивает запрещение одной или нескольких линий запросов прерывания.BD - буфер данных; предназначен для сопряжения с системной шиной данных.RWCU - блок управления записью/чтением; принимает управляющие сигналы от микропроцессора и задает режим функционирования контроллера прерываний.CMP - схема каскадного буфера-компаратора; используется для включения в систему нескольких контроллеров.CU - схема управления; вырабатывает сигналы прерывания и формирует трехбайтовую команду CALL для выдачи на шину данных.

увеличить изображение
Рис. 13.3. Структура контроллера прерываний 8259А
Один контроллер 8259A способен обслуживать прерывания от 8 источников. Для обслуживания большего количества устройств используется каскадное включение контроллеров (рис. 13.4). В системах IBM PC AT каскадное включение позволяет до 15 устройствам сигнализировать о прерывании (табл. 13.1).

увеличить изображение
Рис. 13.4. Каскадное включение контроллеров прерываний
| NMI | Ошибка памяти или другая неисправимая ошибка в системе | 02h | |
| IRQ0 | Системный таймер | 1 | 08h |
| IRQ1 | Клавиатура | 2 | 09h |
| IRQ8 | Часы реального времени | 3 | 70h |
| IRQ9 | Устройство на шине ISA | 4 | 71h |
| IRQ10 | Устройство на шине ISA | 5 | 72h |
| IRQ11 | Устройство на шине ISA | 6 | 73h |
| IRQ12 | Устройство на шине ISA | 7 | 74h |
| IRQ13 | Ошибка сопроцессора | 9 | 75h |
| IRQ14 | IDE контроллер | 9 | 76h |
| IRQ15 | Устройство на шине ISA | 10 | 77h |
| IRQ3 | Последовательный порт (COM2 или COM4) | 11 | 0Bh |
| IRQ4 | Последовательный порт (COM1 или COM3) | 12 | 0Ch |
| IRQ5 | Параллельный порт (LPT2) или IDE контроллер (вторичный) | 13 | 0Dh |
| IRQ6 | Контроллер дисковода | 14 | 0Eh |
| IRQ7 | Параллельный порт (LPT1) | 15 | 0Fh |
Поскольку в каждый момент времени может поступить более чем один запрос на прерывание, контроллер прерываний имеет схему приоритетов. В основном режиме - режиме полного вложения, - до тех пор, пока установлен разряд в регистре ISR, соответствующий запрашиваемому прерыванию, все последующие запросы с таким же или более низким приоритетом игнорируются, подтверждаются лишь запросы с более высоким приоритетом.
В циклическом режиме используется круговой порядок использования приоритетов. Последнему обслуженному запросу присваивается низший приоритет, следующему по кругу - наивысший, что гарантирует обслуживание остальных устройств до очередного обслуживания данного устройства.
Контроллер допускает маскирование отдельных запросов прерываний, что позволяет устройствам с более низким приоритетом получить возможность генерировать прерывания. Режим специального маскирования разрешает прерывания всех уровней, кроме уровней, обслуживаемых в данный момент.
Кроме того, для каскадного включения возможен специальный режим полного вложения. Этот режим программируется любым ведущим контроллером при инициализации. В данном режиме игнорируются запросы с приоритетом более низким, чем приоритет обрабатываемого в данный момент запроса, и обслуживаются все запросы с равным или более высоким приоритетом.
Подсистема прямого доступа к памяти
Прямой доступ к памяти (ПДП) - Direct Memory Access (DMA) - используется для высокоскоростной передачи данных между устройствами ввода-вывода и оперативной памятью без вмешательства ЦП. Типичным примером использования DMA являются контроллеры дисководов и винчестера. В системах IBM PC XT/AT используется контроллер DMA Intel 8237A (рис. 13.5), обеспечивающий четыре 8-битных канала DMA. В IBM PC AT применяется каскадное включение двух контроллеров DMA (рис. 13.6): 8237A, обеспечивающего четыре 8-битных канала, и 8237A-5, обеспечивающего четыре 16-битных канала (см. табл. 13.2).
| 0 | Устройство на шине ISA | 8 |
| 1 | Контроллер интерфейса SDLC | 8 |
| 2 | Контроллер дисковода | 8 |
| 3 | Контроллер винчестера | 8 |
| 4 | Используется для каскадирования | 16 |
| 5 | Устройство на шине ISA | 16 |
| 6 | Устройство на шине ISA | 16 |
| 7 | Устройство на шине ISA | 16 |

увеличить изображение
Рис. 13.5. Структура контроллера DMA Intel 8237A

увеличить изображение
Рис. 13.6. Каскадное включение контроллеров в IBM PC AT
В активном цикле обслуживание подсистемы DMA возможно в одном из четырех режимов:
режим одиночной передачи (Single Transfer Mode);режим передачи блока (Block Transfer Mode);режим передачи по требованию (Demand Transfer Mode);каскадный режим (Cascade Mode).
Для формирования 24-разрядного адреса используется регистр страницы, который определяет старшие биты адреса. Младшие 16 бит задаются регистром базы соответствующего канала контроллера. Такая схема обеспечивает передачу данных в пределах адресного пространства 16 Мбайт.
Для 8-битных каналов DMA регистр страницы определяет биты 16-23 физического адреса, а регистр базы - биты 0-15:
| 2 16 3 | 8 7 0 5 |
Для 16-битных каналов DMA используется только 7 бит регистра страницы, определяющих биты 17-23 физического адреса. При этом регистр базы канала задает биты 1-16. Бит A0 всегда выставляется в 0, чтобы гарантировать выровненную передачу слова памяти:
| 23 17 | 16 15 8 7 1 | 0 |
Подсистема DMA предназначена для работы в двух основных циклах: холостом и активном. Каждый цикл - это совокупность некоторого количества ее состояний. Подсистема DMA может иметь семь состояний, каждое из которых соответствует одному периоду синхронизации:
SI - неактивное состояние;S0 - первое состояние обслуживания подсистемы DMA, возникающее по действительному запросу (DREQ);S1, S2, S3, S4 - рабочие состояния;SW - состояние ожидания.
Расширенный программируемый контроллер прерываний (APIC)
Микропроцессоры IA-32, начиная с модели Pentium, содержат встроенный расширенный программируемый контроллер прерываний (APIC). Встроенный APIC предназначен для регистрирования прерываний от источников внутри процессора (например, блок температурного контроля у Pentium 4) или от внешнего контроллера прерываний и передачи их ядру процессора на обработку. Особо важная роль возлагается на встроенный APIC в многопроцессорных системах, где APIC принимает и генерирует сообщения о межпроцессорных прерываниях (IPI - InterProcessor Interrupt). Такие сообщения могут использоваться для распределения обработки прерываний между процессорами или для выполнения системных функций (первоначальная загрузка, диспетчеризация задач и т.п.).
Встроенный APIC различает следующие источники прерываний.
От локальных устройств. Прерывания, генерируемые по фронту или уровню сигнала, который поступает от устройства, непосредственно подключенного к сигналам LINT0 и LINT1 (например, контроллер прерываний типа 8259A).От внешних устройств. Прерывания, генерируемые по фронту или уровню сигнала, который поступает от устройства, подключенного к внешнему контроллеру прерываний. Такое прерывание передается в виде сообщения по шине APIC (или системной шине в Pentium 4).Межпроцессорные (IPI). В многопроцессорных системах один из процессоров может прервать другой при помощи сообщения IPI на шине APIC (или системной шине в Pentium 4).От таймера APIC. Встроенный APIC содержит таймер, который можно запрограммировать на генерацию прерывания по достижении определенного отсчета.От таймера монитора производительности. Процессоры P6 и Pentium 4 содержат блок мониторинга производительности. Этот блок можно запрограммировать таким образом, чтобы связанный с ним таймер при достижении определенного отсчета генерировал прерывание.От термодатчика. Процессоры Pentium 4 содержат встроенный блок температурного контроля, который можно запрограммировать на генерацию прерываний.Внутренние ошибки APIC. Встроенный APIC может генерировать прерывания при возникновении внутренних ошибочных ситуаций (например, при попытке обратиться к несуществующему регистру APIC).
Источники 1, 4, 5, 6, 7 считаются локальными источниками прерываний и обслуживаются специальным набором регистров APIC, называемым таблицей локальных векторов (LVT - local vector table). Два других источника обрабатываются APIC через механизм сообщений. Эти сообщения в Pentium и P6 передаются по выделенной трехпроводной шине APIC (рис. 13.2). В Pentium 4 для передачи APIC-сообщений используется системная шина, поэтому контроллер прерываний может быть подключен непосредственно к обычному системному интерфейсу (например, PCI).

Рис. 13.2. Взаимодействие встроенного APIC и внешнего контроллера прерываний
Структура встроенного APIC является архитектурным подмножеством микросхемы контроллера прерываний Intel 82489DX. Регистры APIC отображаются на 4-Кбайтный блок оперативной памяти по адресу FEE00000h (может быть изменен через MSR регистры процессора).
Наличие встроенного APIC в процессоре обнаруживается при помощи инструкции CPUID(1). После RESET встроенный APIC включен, однако впоследствии он может быть отключен, тогда процессор будет работать с прерываниями как Intel-386/486 (линии LINT0 и LINT1 будут использоваться как NMI# и INTR#, к которым может быть подключен контроллер прерываний типа 8259A).
Таблица локальных векторов (LVT) состоит из шести 32-битных регистров (в P6 - 5, в Pentium - 4):
регистр вектора прерывания от таймера;регистр вектора прерывания от термодатчика (только в Pentium 4);регистр вектора прерывания от монитора производительности (P6 и Pentium 4);регистр вектора прерывания LINT0;регистр вектора прерывания LINT1;регистр вектора прерывания ошибки.
Значения в этих регистрах определяют:
номер вектора прерывания;тип прерывания (fixed - с указанным вектором, SMI - переход в режим системного управления, NMI - немаскируемое, INIT - сброс, ExtINT - внешнее: процессор генерирует цикл INTA и ожидает номер вектора прерывания от внешнего контроллера);активный уровень сигнала (низкий или высокий) или триггерный режим (прерывание по фронту или по уровню);маску прерывания (прерывание может быть замаскировано).
Эти регистры также отражают состояние прерывания (доставляется ли это прерывание ядру процессора в данный момент).
Кроме того, APIC содержит регистры управления таймером APIC, регистр версии, регистр ошибки, регистры, связанные с обслуживанием прерываний (регистр приоритета, регистр запроса IRR, регистр обслуживания ISR), и регистры, связанные с передачей и приемом IPI.
это события, которые указывают на
Прерывания и исключения - это события, которые указывают на возникновение в системе или в выполняемой в данный момент задаче определенных условий, требующих вмешательства процессора. Возникновение таких событий вынуждает процессор прервать выполнение текущей задачи и передать управление специальной процедуре либо задаче, называемой обработчиком прерывания или обработчиком исключения. Различные синхронные и асинхронные события в системе на основе ЦП IA-32 можно классифицировать следующим образом:

увеличить изображение
Рис. 13.1. Классификация событий в системе на основе ЦП IA-32
Прерывания обычно возникают в произвольный момент времени. Прерывания бывают аппаратные (или внешние) и программные.
Внешние прерывания генерируются по аппаратному сигналу, поступающему от периферийного оборудования, когда оно требует обслуживания. Процессор определяет необходимость обработки внешнего прерывания по наличию сигнала на одном из контактов INTR# или NMI#. При появлении сигнала на линии INTR# внешний контроллер прерываний (например, 8259A) должен предоставить процессору вектор (номер) прерывания. С линией NMI# всегда связано прерывание #2.
В процессорах Pentium, P6 и Pentium 4 эти линии могут быть сконфигурированы на использование встроенным контроллером прерываний - APIC (Advanced Programmable Interrupt Controller), тогда они называются LINT0 и LINT1 и их назначение определяется настройками APIC.
Прерывания, которые генерируются при поступлении сигнала на вход INTR#, называют маскируемыми аппаратными прерываниями. Бит IF в регистре флагов позволяет заблокировать (замаскировать) обработку таких прерываний.
Прерывания, генерируемые сигналом NMI#, называют немаскируемыми аппаратными прерываниями. Немаскируемые прерывания не блокируются флагом IF. Пока выполняется обработчик немаскируемого прерывания, процессор блокирует получение немаскируемых прерываний до выполнения инструкции IRET, чтобы исключить одновременную обработку нескольких немаскируемых прерываний.
Прерывания всегда обрабатываются на границе инструкций, т.е. при появлении сигнала на контакте INTR# или NMI# процессор сначала завершит выполняемую в данный момент инструкцию (или итерацию при наличии префикса повторения), а только потом начнет обрабатывать прерывание. Помещаемый в стек обработчика адрес очередной инструкции позволяет корректно возобновить выполнение прерванной программы.
С помощью инструкции INT n (n - номер прерывания) можно сгенерировать прерывание с любым номером 0...255. Такие прерывания называют программными. Состояние бита IF в регистре флагов не влияет на возможность генерации программных прерываний. Программные прерывания могут использоваться для доступа к сервисам операционной системы (например, INT $21 - сервисы DOS, INT $80 - сервисы Linux), функциям драйверов устройств (например, INT $33 - драйвер мыши) или специальным сервисам (INT $10 - видео-сервис BIOS, INT $31 - DPMI-сервис), INT $67 - сервис EMS).
Хотя номер прерывания в этой инструкции может быть любым, следует отметить, что, например, при использовании вектора #2 для вызова обработчика немаскируемого прерывания внутреннее состояние процессора будет отличаться от того, которое бывает при обработке аппаратного немаскируемого прерывания. Аналогично, попытка вызвать обработчик исключения с помощью этой инструкции может оказаться неудачной, т.к. при возникновении большинства исключений в стек включается код ошибки, а при генерации программного прерывания этого не происходит. Обработчик исключения извлекает из стека код ошибки, а в случае программного прерывания из стека будет ошибочно извлечен адрес возврата, что нарушит целостность стека и, в конечном итоге, скорее всего, приведет к исключению #13 или более тяжелому.
Исключения являются для процессора внутренними событиями и сигнализируют о каких-либо ошибочных условиях при выполнении той или иной инструкции. Источниками исключений являются три типа событий:
генерируемые программой исключения, позволяющие программе контролировать определенные условия в заданных точках программы (INTO - проверка на переполнение, INT3 - контрольная точка, BOUND - проверка границ массива);исключения машинного контроля (#18), возникающие в процессе контроля операций внутри чипа и транзакций на шине процессора (Pentium, P6 и Pentium 4);обнаруженные процессором ошибки в программе (деление на ноль, нарушение правил защиты, отсутствие страницы и т.п.)
Исключения процессора, в зависимости от способа генерации и возможности рестарта вызвавшей исключение команды, подразделяются на нарушения, ловушки и аварии.
Нарушение (отказ) - это исключение, которое обнаруживается либо перед исполнением, либо во время исполнения команды. При этом процессор переходит в состояние, позволяющее осуществить рестарт команды. В качестве адреса возврата в стек обработчика заносится адрес вызвавшей исключение команды.
Ловушка возникает на границе команд сразу же после команды, вызвавшей это исключение. Значения регистров CS и EIP, заносимые в стек обработчика, указывают на очередную команду. Например, если ловушка сработала на команде JMP, то в стеке запоминаются значения регистров CS и EIP, указывающие на ссылку команды JMP.
В некоторых случаях для ловушек и нарушений невозможен рестарт команды, например, если один из операндов расположен ниже текущего указателя стека, т.е. по адресу памяти меньшему, чем вершина стека.
Авария не позволяет осуществить рестарт программы, и зачастую нельзя точно локализовать команду, вызвавшую это исключение. Исключения типа "авария" генерируются при обнаружении серьезных ошибок, таких как неразрешенные или несовместимые значения в системных таблицах или аппаратные сбои.
Типичным случаем аварии является исключение #8 "двойная ошибка". Двойная ошибка происходит, когда процессор пытается обработать исключение, а его обработчик генерирует еще одно исключение. Для некоторых исключений процессор не генерирует двойную ошибку, такие исключения называют "легкими". Только ошибки деления (исключение #0) и сегментные исключения (#10, #11, #12, #13), называемые "тяжелыми", могут вызвать двойную ошибку. Таким образом, получение исключения "неприсутствие сегмента" во время обработки исключения отладки не приведет к двойной ошибке, в то время как ошибка сегмента, происходящая во время обработки ошибки деления на нуль, приведет к исключению #8.
Если при попытке вызвать обработчик исключения #8 возникает ошибка, процессор переходит в режим отключения (shutdown mode).
Вывести из этого режима процессор могут только аппаратные сигналы: NMI#, SMI#, RESET# или INIT#. Обычно чипсет, обнаружив на шине процессора цикл отключения, инициирует аппаратный сброс.
Если на границе инструкции обнаруживается, что требуется обработка более одного прерывания или исключения, процессор обрабатывает прерывание или исключение с наивысшим приоритетом. Исключения с низким приоритетом снимаются, а прерывания с низким приоритетом откладываются. Снятые исключения могут быть потом снова сгенерированы при возврате из обработчика.
Архитектура IA-32 предоставляет механизм обработки прерываний и исключений, прозрачный для прикладного и системного программного обеспечения. При возникновении прерывания или исключения текущая выполняемая задача автоматически приостанавливается на время действий обработчика, после чего ее выполнение возобновляется без потери непрерывности, кроме случаев, когда обработка прерывания или исключения вынуждает завершить программу.
Все прерывания и исключения имеют номер (иногда именуемый вектором) в диапазоне от 0 до 255. Номера 0...31 зарезервированы фирмой Intel для исключений.
Какие исключительные ситуации могут возникать
Какие исключительные ситуации могут возникать при работе компьютера?Чем маскируемые прерывания отличаются от немаскируемых?В каком регистре контроллера прерываний сохраняются уровни запросов прерываний, находящиеся на обслуживании?Нарисуйте схему каскадного включения контроллеров прерываний.В каких режимах работы контроллера прерываний подтверждаются лишь запросы с более высоким приоритетом?Нарисуйте схему подсистемы прямого доступа к памяти в архитектуре IBM PC AT.В каких режимах работает контроллер прямого доступа к памяти?Как формируется адрес при передаче слова в режиме DMA?В каких состояниях может находиться подсистема прямого доступа к памяти?
Архитектура системных интерфейсов
По функциональному назначению можно выделить системные интерфейсы (интерфейсы, связывающие отдельные части компьютера как микропроцессорной системы) и интерфейсы периферийных устройств.
Микро-ЭВМ с точки зрения архитектуры можно разделить на 2 основных класса:
использующие внутренний интерфейс МП (унифицированный канал);использующие внешний по отношению к МП системный интерфейс.
Системный интерфейс выполняется обычно в виде стандартизированных системных шин. Однако в последнее время наметились тенденции внедрения концепций сетевого взаимодействия в архитектуру системных интерфейсов.
Различают два класса системных интерфейсов: с общей шиной (сигналы адреса и данных мультиплексируются) и с изолированной шиной (раздельные сигналы данных и адреса). Прародителями современных системных шин являются:
Unibus фирмы DEC (интерфейс с общей шиной),Multibus фирмы Intel (интерфейс с изолированной шиной).
Шинная архитектура Unibus была разработана фирмой DEC для мини-ЭВМ серии PDP-11. Общая шина для периферийных устройств, памяти и процессора состоит из 56 двунаправленных линий. Unibus поддерживает пересылку одного 16-разрядного слова за 750 нс. Все пересылки инициируются ведущим устройством и подтверждаются принимающим (запоминающим) устройством, что позволяет работать с модулями различного быстродействия. Выбор устройства на роль ведущего является динамической процедурой, поэтому в ответ на запрос периферийного устройства процессор может передать ему управление шиной. Благодаря этой особенности, на основе Unibus возможна разработка мультипроцессорных систем. Unibus позволяет подключать к магистрали большое число устройств, хотя необходимо учитывать снижение надежности по мере увеличения длины магистрали. Данные регистров внешних устройств могут обрабатываться теми же командами, что и данные в памяти. Следует, однако, отметить сложность технической реализации интерфейсных модулей, связанных с пересылкой адресов и данных по одним и тем же линиям.
Свое развитие архитектура Unibus получила в системном интерфейсе NuBus.
Интерфейс NuBus (табл. 14.1) был разработан MIT1) совместно с Western Digital в 1979 г. Затем, при участии Texas Instruments, архитектура NuBus была стандартизована IEEE2) (стандарт IEEE 1196-1987) и применялась фирмой Apple в компьютерах Macintosh. В NuBus также используется мультиплексирование адреса и данных. Предусмотрена автоматическая конфигурация. Возможно использование нескольких задатчиков магистрали с децентрализованным арбитражем. Имеется режим блочной передачи данных. К недостаткам NuBus можно отнести слабые возможности режима ПДП, сложный метод обработки прерываний (предусмотрен всего один сигнал запроса прерывания и программный опрос потенциальных источников прерываний).
Альтернативная шинная архитектура Multibus была разработана фирмой Intel. Шина также обеспечивает системную архитектуру с одним или несколькими ведущими узлами и с квитированием установления связи между устройствами, работающими с разной скоростью. Благодаря разделению шины адреса и шины данных, возможны реализации этой архитектуры для процессоров разной разрядности. Существовали 8-разрядный и 16-разрядный варианты архитектуры Multibus для IBM PC. Шина адреса - 20 бит. Multibus подразумевает достаточно простую аппаратную реализацию, однако число устройств, одновременно использующих ресурсы шины, ограничено 16 абонентами. Следует отметить, что скорость обмена на шине Multibus была ниже, чем на шине Unibus.
| Год выпуска | 1979 | 1984 | 1989 | 1987 | 1987 | 1992 |
| Разрядность данных | 32 | 8/16 | 32 | 32/64 | 32 | 32/64 |
| Разрядность адреса | 32 | 20/24 | 32 | 32 | 32 | 32 |
| Тактовая частота, МГц | 10 | 4/8 | 8 | 10 | <33 (Fцп) | 33, 66 |
| Макс. скорость, Мбайт/с | 37 | 8-16 | 33 | 20/40 | 130 | 132/264, 520 |
| Макс. кол-во устройств | 6 | 15 | 16 | 2-3 | 10 | |
| Кол-во сигналов | 96 | 62/98 | 188 | 178 | 112 | 124/188 |
Интерфейс PCI
Доминирующее положение на рынке ПК занимают системы на основе шины PCI (Peripheral Component Interconnect - Взаимодействие периферийных компонентов). Этот интерфейс был предложен фирмой Intel в 1992 году (стандарт PCI 2.0 - в 1993) в качестве альтернативы локальной шине VLB/VLB2. Следует отметить, что разработчики этого интерфейса позиционируют PCI не как локальную, а как промежуточную шину (mezzanine bus), т.к. она не является шиной процессора. Поскольку шина PCI не ориентирована на определенный процессор, ее можно использовать для других процессоров. Шина PCI была адаптирована к таким процессорам, как Alpha, MIPS, PowerPC и SPARC. Именно PCI сменила NuBus на платформе Apple Macintosh.
Шины ISA, EISA или MCA могут управляться шиной PCI с помощью моста сопряжения (рис. 14.3), что позволяет устанавливать в ПК платы устройств ввода-вывода с различными системными интерфейсами. Например, в чипсете Intel Triton использовалась микросхема PIIX1), помимо контроллера IDE предоставляющая мост для шины ISA.
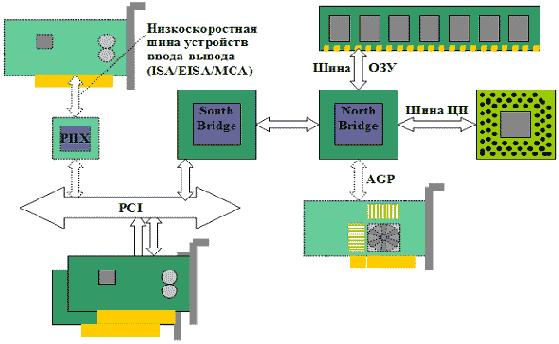
Рис. 14.3. Система на основе PCI
Существуют три варианта плат PCI: с уровнями сигналов 3,3 В, с уровнями сигналов 5 В и универсальные. Ключ в разъеме гарантирует, что платы с одним уровнем сигнала и невзаимозаменяемые не будут по ошибке вставлены в разъем с другим уровнем сигнала. Платы с пониженным напряжением питания в основном используются в мобильных компьютерах.
Существует 32-разрядная и 64-разрядная реализация шины PCI. В 64-разрядной реализации используется разъем с дополнительной секцией. 32-разрядные и 64-разрядные платы можно устанавливать в 64-разрядные и 32-разрядные разъемы и наоборот. Платы и шина определяют тип разъема и работают должным образом. При установке 64-разрядной платы в 32-разрядный разъем остальные выводы не задействуются и просто выступают за пределы разъема.
На шине PCI сигналы адреса и данных мультиплексированы, поэтому для передачи каждых 32 или 64 разрядов требуется два шинных цикла: один - для пересылки адреса, а второй - для пересылки данных.
Однако возможен также пакетный режим, при котором вслед за одним циклом передачи адреса разрешается осуществить до четырех циклов передачи данных (до 16 байт в PCI-32). После этого устройство должно подать новый запрос на обслуживание и снова получить управление над шиной (и выполнить адресный цикл). Поэтому шина PCI-32 с тактовой частотой 33 МГц имеет пиковую скорость обычной передачи около 66 Мбайт/с (два шинных цикла для передачи 4 байт) и пиковую скорость пакетной передачи около 105 Мбайт/с.
PCI поддерживает процедуру прямого доступа к памяти ведущего устройства на шине (bus mastering DMA), хотя некоторые реализации PCI могут и не предоставлять такую возможность для всех разъемов PCI. Процессор может функционировать параллельно с периферийными устройствами, являющимися ведущими на шине.
Кроме того, платы PCI поддерживают:
автоматическую конфигурацию Plug&Play (не требуют назначения адресов расширений BIOS вручную);совместное использование прерываний (когда один и тот же номер прерывания может использоваться разными устройствами);контроль четности сигналов шины данных и адресной шины;конфигурационную память от 64 до 256 байт (код производителя, код устройства, код класса (функции) устройства и др.).
Персональные компьютеры могут иметь две или больше шин PCI. Каждой шиной управляет свой мост PCI, что позволяет устанавливать в компьютер больше плат PCI (вплоть до 16 - ограничение адресации). Если управление второй шиной PCI осуществляется с первой шины, то это называется каскадной или иерархической схемой. В этом случае первая шина будет также нести нагрузку второй шины. Если управление каждой шиной PCI осуществляется непосредственно с шины процессора, это называется равноправной схемой. Обычно мост PCI выполняет также функции контроллера внешней кэш-памяти, контроллера основной памяти и обеспечивает сопряжение с процессором. В системах на основе Pentium II/III эти функции распределены между двумя мостами: "северным" (North Bridge) и "южным" (South Bridge), что связано с наличием дополнительного высокоскоростного системного интерфейса для подключения видеокарты (AGP).
В 1995 году был выпущена улучшенная версия интерфейса - PCI 2.1, которая предоставила следующие возможности:
поддержка тактовой частоты шины 66 МГц;таймер обработки множественных запросов MTT (Multi-Transaction Timer) позволяет устройствам, осуществляющим прямой доступ к памяти, удерживать шину для "прерывистой" передачи пакетов, при этом не требуется повторно добиваться права управления шиной, что особенно полезно при передаче видеоданных;пассивное разъединение (Passive Release) позволяет устройствам, осуществляющим прямой доступ к памяти по шине PCI, передавать данные в то время, когда ведется передача данных по шине ISA (обычно это приводило к блокированию передачи по шине PCI, поскольку она использовалась для подключения центрального процессора к шине ISA);задержанные транзакции PCI позволяют передаваемым данным ведущего устройства на шине PCI получать приоритет над ожидающими в очереди данными для передачи с PCI на ISA (которые будут переданы позже);повышение производительности записи благодаря оснащению PCI-чипсета буферами большего объема, поэтому транзакции могут выстраиваться в очередь, когда шина PCI занята, и происходит сбор байтов, слов и двойных слов, которые могут объединяться в единую 8-байтную операцию записи.
C 2005 года в ПК на основе Pentium 4 вместо PCI используют новый системный интерфейс - PCI Express.
Интерфейсы накопителей
Первоначально для подключения накопителей к IBM PC использовались интерфейсы низкого уровня, классифицируемые как интерфейсы на уровне устройства: ST-506 (Shugart Technology), ESDI (Enhanced Small Device Interface). Для таких интерфейсов характерно, что их сигналы являются функцией генерирующего и использующего их устройства. Это позволяет использовать весьма простую электронику в самом устройстве, а основную нагрузку по обработке данных переложить на контроллер или процессор, что, естественно, негативно отражается на скоростных и прочих характеристиках подобных накопителей.
Например, для ST-506/412: Direction In (направление), Step (шаг), Head Select (выбор головки) и т.п. Более того, сигнал с носителя, включающий в себя данные и биты синхронизации, передавался через интерфейс в аналоговом виде, поскольку разделение этой информации, выполняемое специальным блоком - сепаратором, происходило в контроллере. Появление новых методов кодирования информации (RLL1) вместо MFM2) ) привело к необходимости создания ориентированных на эти методы контроллеров (RLL-контроллер вместо MFM-контроллера), причем не гарантировалась надежная работа MFM-винчестера с RLL-контроллером. В интерфейсе ESDI эта проблема была решена, поскольку сепаратор был перенесен из контроллера в само устройство. Кроме того, в интерфейсе ESDI была выделена последовательная линия Command Data для передачи 16-битных команд, что перевело взаимодействие контроллера и винчестера ESDI на более высокий уровень и позволило повысить скорость передачи данных до 20 Мбит/с.
В настоящее время распространены интерфейсы системного уровня, использующие сигналы в логике центрального процессора, что предполагает реализацию функций контроллера накопителя в самом накопителе, а устройство, сопрягающее интерфейс накопителя с системной шиной ПК, выполняет лишь роль адаптера интерфейса (моста). В IBM PC таким интерфейсом является EIDE/ATA. Он представляет собой "приставку" к 16-битной шине ISA, иначе называемой AT Bus, поэтому стандарт именуется AT Attachment (ATA).
Другое название интерфейса - Enhanced Integrated Drive Electronics (EIDE). Первая спецификация ATA (IDE) определяла возможность подключения двух устройств к одному интерфейсу. Спецификация ATA-2 (EIDE) описывает совместную работу двух интерфейсов, позволяя, таким образом, подключать до четырех устройств. С внедрением стандарта ATA-4 на поддержку пакетных команд (ATAPI - ATA Packet Interface) стало возможным подключение устройств со сменным накопителем (приводы CD-ROM/DVD-ROM, стримеры, приводы флоппи-дисков большого объема). Последующие спецификации добавляли новые скоростные режимы (табл. 14.3) и решали некоторые проблемы (табл. 14.4). После появления интерфейса SerialATA принято ссылаться на EIDE/ATA как Parallel ATA.
| Режим | PIO3) | SW DMA4) | MW DMA5) | Ultra DMA | ||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
| Скорость, Мбайт/с | 3,3 | 5,2 | 8,3 | 11 | 16 | 2,1 | 4,2 | 8,3 | 4,2 | 13 | 16 | 16 | 25 | 33 | 44 | 66 | 100 | 133 |
| Стандарт | 1 | 1 | 1 | 2 | 2 | 1 | 1 | 1 | 1 | 2 | 2 | 4 | 4 | 4 | 5 | 5 | 6 | 7 |
| 1 | ATA, IDE | X3.221-1994 | Накопители размером <528 мегабайт |
| 2 | EIDE, FastATA | X3.279-1996 | Адресация LBA 24 бита (до 8,4 гигабайт) |
| 3 | EIDE | X3.298-1997 | Адресация LBA 28 бит (до 134 гигабайт), SMART |
| 4 | ATAPI | NCITS 317-1998 | Поддержка пакетных команд (ATAPI) - поддержка CD-ROM |
| 5 | UltraATA/66 | NCITS 340-2000 | 80-контактный кабель |
| 6 | UltraATA/100 | NCITS 347-2001 | Адресация LBA 48 бит, автоматическое управление акустикой |
| 7 | UltraATA/133 | NCITS 361-2002 | Потоковое расширение (streaming), "длинные" сектора |
Кроме перечисленных интерфейсов, для подключения накопителей используются универсальные периферийные интерфейсы, речь о которых пойдет в следующей главе - SCSI, USB, FireWire и т.п.
PCI Express
Интерфейс PCI Express (первоначальное название - 3GIO1)) использует концепцию PCI, однако физическая их реализация кардинально отличается. На физическом уровне PCI Express представляет собой не шину, а некое подобие сетевого взаимодействия на основе последовательного протокола. Высокое быстродействие PCI Express позволяет отказаться от других системных интерфейсов (AGP, PCI), что дает возможность также отказаться от деления системного чипсета на северный и южный мосты в пользу единого контроллера PCI Express.
Одна из концептуальных особенностей интерфейса PCI Express, позволяющая существенно повысить производительность системы, - использование топологии "звезда". В топологии "шина" (рис. 14.5а) устройствам приходится разделять пропускную способность PCI между собой. При топологии "звезда" (рис. 14.5б) каждое устройство монопольно использует канал, связывающий его с концентратором (switch) PCI Express, не деля ни с кем пропускную способность этого канала.

Рис. 14.5. Сравнение топологий PCI и PCI Express
Канал (link), связывающий устройство с концентратором PCI Express, представляет собой совокупность дуплексных последовательных (однобитных) линий связи, называемых полосами (lane). Дуплексный характер полос также контрастирует с архитектурой PCI, в которой шина данных - полудуплексная (в один момент времени передача выполняется только в определенном направлении). На электрическом уровне каждая полоса соответствует двум парам проводников с дифференциальным кодированием сигналов. Одна пара используется для приема, другая - для передачи. PCI Express первого поколения декларирует скорость передачи одной полосы 2,5 Гбит/с в каждом направлении. В будущем планируется увеличить скорость до 5 и 10 Гбит/с.
Канал может состоять из нескольких полос: одной (x1 link), двух (x2 link), четырех (x4 link), восьми (x8 link), шестнадцати (x16 link) или тридцати двух (x32 link). Все устройства должны поддерживать работу с однополосным каналом. Аналогично, различают слоты: x1, x2, x4, x8, x16, x32.
Однако слот может быть "шире", чем подведенный к нему канал, т.е. на слот x16 фактически может быть выведен канал x8 link и т.п. Карта PCI Express должна физически подходить и корректно работать в слоте, который по размерам не меньше разъема на карте, т.е. карта x4 будет работать в слотах x4, x8, x16, даже если реально к ним подведен однополосный канал. Процедура согласования канала PCI Express обеспечивает выбор максимального количества полос, поддерживаемого обеими сторонами.
При передаче данных по многополосным каналам используется принцип чередования или "разборки данных" (data stripping): каждый последующий байт передается по другой полосе. В случае канала x2 это означает, что все четные байты передаются по одной полосе, а нечетные - по другой.
Как и большинство других высокоскоростных последовательных протоколов, PCI Express использует схему кодирования данных, встраивающую тактирующий сигнал в закодированные данные, т.е. обеспечивающую самосинхронизацию. Применяемый в PCI Express алгоритм 8B / 10B (8 бит в 10 бит) обеспечивает разбиение длинных последовательностей нулей или единиц так, чтобы приемная сторона не потеряла границы битов. С учетом кодирования 8B/10B пропускную способность однополосного канала PCI Express можно оценить, как 2500 Мбит/с / 10 бит/байт = 250 мегабайт/с (238 Мбайт/с).
PCI Express обеспечивает передачу управляющих сообщений, в том числе прерываний, по тем же линиям данных. Последовательный протокол не предусматривает блокирование, поэтому легко обеспечивается латентность, сопоставимая с PCI, где имеются выделенные линии для прерываний.
Порт AGP
С повсеместным внедрением технологий мультимедиа пропускной способности шины PCI стало не хватать для производительной работы видеокарты. Чтобы не менять сложившийся стандарт на шину PCI, но, в то же время, ускорить ввод-вывод данных в видеокарту и увеличить производительность обработки трехмерных изображений, в 1996 году фирмой Intel был предложен выделенный интерфейс для подключения видеокарты - AGP (Accelerated Graphics Port - высокоскоростной графический порт). Впервые порт AGP был представлен в системах на основе Pentium II. В таких системах чипсет был разделен на два моста (рис. 14.3): "северный" (North Bridge) и "южный" (South Bridge). Северный мост связывал ЦП, память и видеокарту - три устройства в системе, между которыми курсируют наибольшие потоки данных. Таким образом, на северный мост возлагаются функции контроллера основной памяти, моста AGP и устройства сопряжения с фасадной шиной процессора FSB (Front-Side Bus). Собственно мост PCI, обслуживающий остальные устройства ввода-вывода в системе, в том числе контроллер IDE (PIIX), реализован на основе южного моста.
Одной из целей разработчиков AGP было уменьшение стоимости видеокарты, за счет уменьшения количества встроенной видеопамяти. По замыслу Intel, большие объемы видеопамяти для AGP-карт были бы не нужны, поскольку технология предусматривала высокоскоростной доступ к общей памяти.
Интерфейс AGP по топологии не является шиной, т.к. обеспечивает только двухточечное соединение, т.е. один порт AGP поддерживает только одну видеокарту. В то же время, порт AGP построен на основе PCI 2.1 с тактовой частотой 66 МГц, 32-разрядной шиной данных и питанием 3,3 В. Поскольку порт AGP и основная шина PCI независимы и обслуживаются разными мостами, это позволяет существенно разгрузить последнюю, освобождая пропускную способность, например, для потоков данных с каналов IDE. В то же время, поскольку AGP-порт всегда один, в интерфейсе нет возможностей арбитража, что существенно упрощает его и положительно сказывается на быстродействии.
Для повышения пропускной способности AGP предусмотрена возможность передавать данные с помощью специальных сигналов, используемых как стробы, вместо сигнала тактовой частоты 66 МГц (табл. 14.2). Например, в режиме AGP 2x данные передаются как по переднему, так и по заднему фронту тактового сигнала, что позволяет достичь пропускной способности 533 Мбайт/с.
| Режим | AGP 1x | AGP 2x | AGP 4x | AGP 8x |
| Спецификация | AGP 1.0-1997 | AGP 1.0-1997 | AGP 2.0-1998 | AGP 3.0-2000 |
| Уровни напряжений | 3,3 В | 3,3 В | 1,5 В | 0,8 В |
| Макс. скорость | 266 Мбайт/с | 533 Мбайт/с | 1066 Мбайт/с | 2133 Мбайт/с |

Рис. 14.4. Конвейеризация AGP
Главная обработка трехмерных изображений выполняется в основной памяти компьютера как центральным процессором, так и процессором видеокарты. AGP обеспечивает два механизма доступа процессора видеокарты к памяти:
DMA (Direct Memory Access) - обычный прямой доступ к памяти. В этом режиме основной памятью считается встроенная видеопамять на карте, текстуры копируются туда из системной памяти компьютера перед использованием их процессором видеокарты;DIME (Direct In Memory Execute) - непосредственное выполнение в памяти. В этом режиме основная и видеопамять находятся как бы в общем адресном пространстве. Общее пространство эмулируется с помощью таблицы отображения адресов GARP (Graphic Address Remapping Table) блоками по 4 Кбайт. Таким образом, процессор видеокарты способен непосредственно работать с текстурами в основной памяти без необходимости их копирования в видеопамять.
Этот процесс называется AGP-текстурированием.
Чтобы извлечь выгоду из применения порта AGP, помимо требуемой аппаратной поддержки (т.е. графического адаптера AGP и системной платы), необходимую поддержку должны обеспечивать операционная система и драйвер видеоадаптера, а в прикладной программе должны быть использованы новые возможности порта AGP (например, трехмерное проецирование текстур).
Существуют модификации порта AGP:
спецификация AGP Pro для видеокарт с большой потребляемой мощностью (до 110 Вт), включающая дополнительные разъемы питания;64-битный порт AGP, используемый для профессиональных графических адаптеров;интерфейс AGP Express, представляющий собой эмуляцию порта AGP при помощи сдвоенного слота PCI в форм-факторе AGP. Применяется на некоторых материнских платах на основе PCI Express для поддержки AGP-видеокарт.
В настоящее время порт AGP практически исчерпал свои возможности и активно вытесняется системным интерфейсом PCI Express.
Первым стандартным системным интерфейсом для
Первым стандартным системным интерфейсом для ПК на основе ЦП IA-32 следует считать ISA (Industry Standard Architecture - Архитектура промышленного стандарта). ISA представляет собой шину, используемую в IBM PC-совместимых ПК для обеспечения питания и взаимодействия плат расширения с системной платой, в которую они вставляются. Полное описание шины, включая ее временные характеристики, было издано в виде стандарта IEEE P996-1987.
Первый вариант этой архитектуры для ЦП 8086/8088 с тактовой частотой 4,77 МГц представлял собой 62-контактную шину с 8 линиями данных, 20 линиями адреса, сигналами для прерываний и запросов и подтверждения DMA, а также линиями питания и сигналами синхронизации.
У процессора 80286, применявшегося в IBM PC AT, была 16-разрядная шина данных, поэтому системная шина была расширена дополнительным 36-контактным соединителем, который обеспечивал еще восемь линий данных, еще четыре линии адреса, дополнительные линии прерываний и каналов DMA. На эту шину был выведен тактовый сигнал с частотой 8 МГц. Таким образом, теоретическая максимальная скорость передачи данных на шине ISA составляет 16 Мбайт/с, хотя чаще утверждается, что она составляет 8 Мбайт/с, поскольку один цикл шины обычно требуется для передачи адреса, а другой - для передачи 16 разрядов данных. На самом деле, типичная скорость передачи данных на этой шине составляет от 1 до 2,5 Мбайт/с. Это значение обусловлено конфликтами на шине с другими устройствами, главным образом, с памятью, а также задержками буферизации из-за асинхронного характера шины (быстродействие процессора и шины различается).
Появление 32-битных процессоров Intel-386 и Intel-486 показало, что быстродействие магистрали ISA является сдерживающим фактором на пути повышения производительности компьютеров. В 1989 году группой компаний (Compaq, Hewlett Packard, NEC и др.) было предложено эволюционное развитие архитектуры ISA - шина EISA (Extended ISA). С одной стороны, EISA имела все преимущества высокопроизводительной 32-битной шины, а с другой - была полностью совместима с ISA "сверху вниз" и не требовала перехода на новую элементарную базу.
Разработчики магистрали EISA позаботились не только об информационной и электрической, но и о конструктивной совместимости с ISA. Разъем EISA состоит из двух рядов контактов, один из которых (верхний) предназначен для сигналов ISA, а другой (нижний) - для дополнительных сигналов EISA (16 дополнительных разрядов данных, 8 дополнительных разрядов адреса, сигналы управления пакетной передачей данных и сигналы управления арбитражем магистрали). Таким образом, в разъемы EISA можно вставлять также 8- или 16-разрядные платы ISA. Предельная скорость передачи (33 МГц) достигается в пакетном режиме, когда адрес предоставляется только в начале пакета и предполагается, что все последующие данные будут поступать в расположенные по порядку ячейки памяти. На магистрали может находиться несколько задатчиков (ЦП, контроллер DMA, контроллер регенерации динамической памяти и др.). Управление предоставлением магистрали централизованно выполняется специальным арбитром по циклическому принципу. Для арбитража используются особые линии магистрали, индивидуальные для каждого разъема.
Альтернативная системная архитектура MCA (Micro Channel Architecture - Микроканальная архитектура) была предложена IBM в 1987 году в серии ПК PS/2. Основным достоинством MCA по сравнению с ISA было увеличение разрядности шины данных до 32 бит. При мультиплексированном использовании шины адреса (32 бит) допускается расширение шины данных до 64 бит. Как и в EISA, в MCA предусмотрена возможность включения многих задатчиков, но арбитраж при этом является не централизованным, а распределенным, причем приоритеты могут устанавливаться программным путем.
MCA не зависит от типа процессора и является полностью асинхронной. Эта магистраль, кроме ПК IBM PS/2, применялась также в рабочих станциях IBM RS/6000 и в высокопроизводительных компьютерах серии Power Parallel SP2 (например, Deep Blue).
Для магистрали MCA предусмотрена автоматическая конфигурация системы. При этом пользователь может изменять и назначать приоритеты различных устройств.
Для увеличения скорости передачи в режиме DMA используется специальный блочный режим (burst mode).
Однако эта шина не нашла широкого распространения, возможно, потому, что компания IBM (по крайней мере, первоначально) взимала слишком большую лицензионную пошлину за ее применение, а также потому, что существовавшие тогда платы адаптеров ПК невозможно было использовать на этой шине, вследствие чего потребителям приходилось приобретать все новые платы, а производителям -заново их разрабатывать.
В типичной системе на основе Intel-386/486 (рис. 14.1) использовались раздельные шины для памяти и устройств ввода-вывода, что позволяло максимально задействовать возможности оперативной памяти и обеспечивало максимальную скорость работы с ней. Однако в таком случае устройства, подключенные через описанные системные интерфейсы, не могут достичь скорости обмена, сравнимой с процессором. В основном это требуется для видеоадаптеров и контроллеров накопителей. Для решения проблемы была предложена архитектура на основе локальных шин (рис. 14.2), которые непосредственно связывали процессор с контроллерами периферийных устройств.

Рис. 14.1. Типичная система с низкоскоростной шиной устройств ввода-вывода

Рис. 14.2. Система с архитектурой локальной шины (VLB)
Наиболее распространенными локальными шинами считались VLB и PCI. VLB (VESA1) Local Bus) представляет собой расширение шины процессора без промежуточных буферов, что резко ограничивает ее нагрузочную способность (2-3 устройства). VLB имеет 32-разрядную шину данных и 32-разрядную шину адреса. Арбитр магистрали не предусмотрен. Достоинством VLB является простота и низкая стоимость. Позднее была также разработана спецификация VLB2, ориентированная на системы на основе Intel Pentium, (64-разрядная шина данных, тактовая частота до 50 МГц, поддержка Plug&Play), однако широкого применения эта разработка не нашла, т.к. была вытеснена шиной PCI.
Типы и характеристики интерфейсов
Интерфейс - это аппаратное и программное обеспечение (элементы соединения и вспомогательные схемы управления, их физические, электрические и логические параметры), предназначенное для сопряжения систем или частей системы (программ или устройств). Под сопряжением подразумеваются следующие функции:
выдача и прием информации;управление передачей данных;согласование источника и приемника информации.
В связи с понятием интерфейса рассматривают также понятие шина (магистраль) - это среда передачи сигналов, к которой может параллельно подключаться несколько компонентов вычислительной системы и через которую осуществляется обмен данными. Очевидно, для аппаратных составляющих большинства интерфейсов применим термин шина, поэтому зачастую эти два обозначения выступают как синонимы, хотя интерфейс - понятие более широкое.
Для интерфейсов, обеспечивающих соединение "точка-точка" (в отличие от шинных интерфейсов), возможны следующие реализации режимов обмена: дуплексный, полудуплексный и симплексный. К дуплексным относят интерфейсы, обеспечивающие возможность одновременной передачи данных между двумя устройствами в обоих направлениях. В случае, когда канал связи между устройствами поддерживает двунаправленный обмен, но в каждый момент времени передача информации может производиться только в одном направлении, режим обмена называется полудуплексным. Важной характеристикой полудуплексного соединения является время реверсирования режима - то время, за которое производится переход от передачи сообщения к приему и наоборот. Если же интерфейс реализует передачу данных только в одном направлении и движение потока данных в противоположном направлении невозможно, такой интерфейс называют симплексным.
Важное значение имеют также следующие технические характеристики интерфейсов:
вместимость (максимально возможное количество абонентов, одновременно подключаемых к контроллеру интерфейса без расширителей);пропускная способность или скорость передачи (длительность выполнения операций установления и разъединения связи и степень совмещения процессов передачи данных);максимальная длина линии связи;разрядность;топология соединения.
Что такое интерфейс? Назовите основные
Что такое интерфейс? Назовите основные интерфейсные функции.Перечислите основные технические характеристики интерфейсов ввода/вывода.Системные интерфейсы микроЭВМ и их особенности.Назовите интерфейсы на уровне устройств.Сравните шины расширения ввода/вывода.Перечислите основные особенности интерфейса AGP.Какие шины расширения используются в архитектуре ПК в настоящее время?
Инфракрасный интерфейс
В 1994 году Ассоциацией инфракрасной передачи данных (Infra-Red Data Assotiation) была принята первая версия стандарта IrDA. Интерфейс IrDA позволяет соединяться с периферийным оборудованием без кабеля при помощи ИК-излучения с длиной волны 850-900 нм (номинально - 880 нм). Порт IrDA дает возможность устанавливать связь на коротком расстоянии до 1 метра в режиме "точка-точка". Ассоциация намеренно не пыталась создавать локальную сеть на основе ИК-излучения, поскольку сетевые интерфейсы очень сложны и требуют большой мощности, а в цели интерфейса входили низкое ресурсопотребление и экономичность.
Порт IrDA основан на архитектуре коммуникационного порта и использует универсальный асинхронный приемо-передатчик UART (Universal Asynchronous Receiver Transmitter), позволяющий работать со скоростью передачи данных 2400-115200 бит/с. Данные передаются 10-битными символами: 8 бит данных, один стартовый бит в начале и один стоповый бит в конце посылки. Связь в IrDA полудуплексная, т.к. передаваемый ИК-луч неизбежно засвечивает приемный фотодиод. Воздушный промежуток между устройствами позволяет принять ИК-энергию только от одного источника в данный момент. На физическом уровне стандарт IrDA определяет следующий способ кодирования: логический "0" передается одиночным ИК-импульсом длиной от 1,6 мкс до 3/16 периода передачи битовой ячейки, а логическая "1" передается как отсутствие ИК-импульса. Минимальная мощность потребления гарантируется при фиксированной длине импульса 1,6 мкс (рис. 15.2).

Рис. 15.2. Формат пакета IrDA
Описанный способ кодирования (асинхронный) используется на скоростях до 115200 бит/с. В стандарте IrDA 1.1 этот режим определяется как SIR (Standard Infra-Red). Кроме того, стандарт IrDA 1.1 допускает реализацию высокоскоростного ИК-интерфейса до 4 Мбит/с - FIR (Fast Infra-Red). В этом случае ИК-интерфейс реализуется на основе синхронных протоколов HDLC/SDLC (High-level Data Link Control / Synchronous Data Link Control) с использованием на скоростях выше 1 Мбит/с фазоимпульсной модуляции.
В настоящее время существует дополнение к стандарту IrDA - VFIR (Very Fast IR), описывающее обмен данными на скоростях до 16 Мбит/с.
Т.к. ИК-интерфейс предусматривает только полудуплексный обмен, стандарт IrDA описывает архитектуру с одним главным (первичным) и множественными подчиненными (вторичными) устройствами. Схема обращения устройств представляет собой обычный протокол обмена данными, где есть фазы запросов (Request) и ответов (Response). Так, первичное устройство отвечает за организацию соединения и за обработку ошибок, посланные им кадры называются управляющими (Command Frames), а пакеты вторичных устройств именуются ответными (Response Frames). Обмен информацией идет только с первичным устройством, которое всегда выступает инициатором соединения, однако его роль может играть любое из устройств, поддерживающих необходимые для этого функции. По желанию может быть включен протокол транспортного уровня, позволяющий осуществлять контроль передачи между приложениями в случае одновременной работы нескольких приложений на одной физической линии.
Каждое устройство имеет 32-битный адрес, вырабатываемый случайным образом при установлении соединения. Каждому кадру в пределах соединения ведущее устройство при старте присваивает 7-битный адрес соединения. Для возможных, но нежелательных случаев, когда два устройства имеют одинаковый адрес, предусмотрен такой механизм, когда ведущее устройство дает команду всем подчиненным устройствам изменить их адреса.
Кроме протоколов физического уровня, стандарты IrDA определяют стек протоколов программного уровня (табл. 15.5).
| IrLMP-IAS | IrCOMM | OBEX |
| TinyTP | ||
| IrLMP-MUX | ||
| IrLAP | ||
| IrPHY: SIR / FIR | ||
С другой стороны, устройство, участвующее в обмене, должна вести передачу не более 500 мс. Максимальный квант передачи может быть равен 100, 200 или 500 мс. Он представляет собой максимальное время, в течение которого устройство передает данные до того, как перейдет к прослушиванию подтверждения приема, и зависит от скорости передачи и емкости буфера в принимающем устройстве. Доступ к среде передачи регулируется посредством специального бита PF (Poll/Final), который устанавливается в теле кадра и выполняет функции, аналогичные маркеру. IrLAP допускает передачи без установления предварительного соединения. Такая передача является широковещательной и не требует получения подтверждения станции получателя. Процедура открытия канала предусматривает обмен идентификационной информацией (ID). Инициатор широковещательного обмена передает ID предопределенное количество раз и прослушивает канал в интервалах между слотами. Станция-получатель случайным образом выбирает слот и посылает в ответ свой ID. При обнаружении коллизии процедура повторяется и применяется для согласования параметров функционирования станций (скорость обмена, максимальная длина пакета). При установлении соединения обмен данными, объем которых не должен превышать 64 байта, осуществляется со скоростью 9600 бит/с. После того, как соединение установлено, скорость обмена и величина пакета данных могут быть увеличены до максимальных. Кроме пакетов с пользовательскими данными, в обмене участвуют специальные кадры, служащие для управления потоком, коррекции ошибок и передачи маркера.
Протокол управления каналом IrLMP (Link Management Protocol) является обязательным, однако его некоторые особенности могут быть опциональны. Протокол IrLMP содержит два компонента: LM-IAS (Link Management Information Access Service) и LM-MUX (Link Management MUltipleXer).
Каждое устройство IrDA содержит таблицу сервисов и протоколов, доступных в настоящий момент. Эта информация может запрашиваться у других устройств. LM-IAS управляет информационной базой так, что станции могут запросить, какие службы предоставляются.
Эта информация хранится в виде объектов, с каждым из которых связан набор атрибутов.
LM-MUX выполняет мультиплексирование каналов поверх одного соединения, устанавливаемого протоколом IrLAP. С этой целью определяется множество точек доступа канала LSAP (Link Service Access Point) каждая с уникальным идентификатором (селектором). Таким образом, каждое из LSAP-соединений определяет логически различные информационные потоки. LM-MUX функционирует в двух режимах: мультиплексирования и эксклюзивном. Первый режим позволяет разделять одно физическое соединение нескольким задачам. В этом случае управление потоком должно быть обеспечено протоколами верхнего уровня (например, TinyTP) или непосредственно приложением. Второй режим отдает все ресурсы одному единственному приложению. Также IrLMP предусматривает три варианта доступа:
с установлением предварительного соединения,без установления предварительного соединения (Сonnectionless) ирежим сбора информации о возможностях, сервисах и приложениях удаленного устройства (XID_Discovery).
TinyTP (Tiny Transport Protocol) - транспортный протокол, осуществляющий функции управления потоком для любого LSAP-соединения независимо. Каждая точка доступа этого протокола (TTPSAP TinyTP Service Access Point) идентифицируется с единственной точкой доступа IrLMP и использует единый с ней адрес. TinyTP также управляет сегментацией и сборкой кадров. На базе TinyTP чаще всего используются протоколы верхнего уровня IrCOMM и OBEX.
Протокол IrCOMM - это протокол эмуляции последовательного или параллельного портов. IrCOMM предоставляет пять типов сервисов: 3-Wire Raw, IrLPT, 3-Wire, 9-Wire и Centronics. Сервисы 3-Wire Raw и IrLPT работают только через одно эксклюзивное соединение (поверх LM-MUX без использования TinyTP) и применяются, когда необходимо передавать исключительно данные. Сервис 3-Wire эмулирует 3-проводный интерфейс RS-232C (сигналы SG, TxD, RxD), используя возможности TinyTP. Сервис 9-Wire предназначен для более точной эмуляции интерфейса RS-232C и обрабатывает, кроме трех вышеупомянутых, еще шесть сигналов (RTS, CTS, DSR, DTR, CD, RI), что позволяет использовать его для подключения модемов с ИК-интерфейсом.Сервис Centronics - это не что иное, как виртуальный параллельный интерфейс на базе TinyTP.
Протокол OBEX (OBject EXchange) обеспечивает обмен объектами произвольного типа между устройствами (например, объекты vCard, vCalendar, vNotes и т.п.) В настоящее время OBEX используется поверх многих беспроводных интерфейсов (например, BlueTooth).
Стандартный интерфейс параллельного порта получил
Стандартный интерфейс параллельного порта получил свое первоначальное название по имени американской фирмы Centronics - производителя принтеров. Первые версии этого стандарта были ориентированы исключительно на принтеры, подразумевали передачу данных лишь в одну сторону (от компьютера к принтеру) и имели невысокую скорость передачи (150-300 Кбайт/с). Такие скорости неприемлемы для современных печатающих устройств. Кроме того, для работы с некоторыми устройствами необходима двусторонняя передача данных. Поэтому некоторые фирмы (Xircom, Intel, Hewlett Packard, Microsoft) предложили несколько модификаций скоростных параллельных интерфейсов: EPP (Enhanced Parallel Port) - до 2 Мбайт/с, ECP (Extended Capabilities Port) - до 4 Мбайт/с и др. На основе этих разработок в 1994 году Институтом инженеров по электронике и электротехнике был принят стандарт IEEE 1284-1994, ныне повсеместно используемый в персональных компьютерах в качестве стандартного параллельного интерфейса.
| 1 | O | STROBE# | WRITE# | HostClk | |
| 2 | O (I) | DATA0 | AD0 | D0 | |
| 3 | O (I) | DATA1 | AD1 | D1 | |
| 4 | O (I) | DATA2 | AD2 | D2 | |
| 5 | O (I) | DATA3 | AD3 | D3 | |
| 6 | O (I) | DATA4 | AD4 | D4 | |
| 7 | O (I) | DATA5 | AD5 | D5 | |
| 8 | O (I) | DATA6 | AD6 | D6 | |
| 9 | O (I) | DATA7 | AD7 | D7 | |
| 10 | I | ACK# | PtrClk | Intr# | PeriphClk |
| 11 | I | BUSY | D3/D7 | Wait# | PeriphAck |
| 12 | I | PE | D2/D6 | AckDataReq | AckReverse# |
| 13 | I | SELECT | D1/D5 | XFlag | XFlag |
| 14 | O | AUTOFD# | HostBusy | DataStb# | HostAck |
| 15 | I | ERROR# | D0/D4 | DataAvail# | PeriphReq# |
| 16 | O | INIT# | Reset# | ReverseReq# | |
| 17 | O | SLCTIN# | NibbleMode | AddrStb# | 1284Active |
| 18-25 | - | GND | GND | GND | GND |
Режим SPP (Стандартный параллельный порт) используется для совместимости со старыми принтерами, не поддерживающими IEEE 1284. Режиму SPP соответствуют три программно доступных регистра:
порт BASE+0 - SPP Data - регистр данных,порт BASE+1 - SPP Status - регистр состояния,порт BASE+2 - SPP Control - регистр управления.
Для устройства LPT1 базовым адресом (BASE) в пространстве портов ввода-вывода обычно является 378h.
В этом режиме линии DATA[0:7] используются для прямой передачи данных (от компьютера к периферийному устройству). Сигналы STROBE#, ACK# и BUSY используются для квитирования. Сигналом STROBE# компьютер информирует о готовности данных на линиях DATA[0:7]. Если устройство приняло выставленные компьютером данные, то оно выставляет сигнал ACK#. Во время приема данных, во время инициализации, а также при наличии ошибки устройство выставляет сигнал BUSY. О возникновении ошибочной ситуации сигнализирует линия ERROR#, а также PE (кончилась бумага). О том, что принтер включен и готов к работе, сообщается при помощи сигнала SELECT. Для подтверждения выбора принтера компьютер выставляет сигнал SLCTIN#. При необходимости очистить буфер принтера и перевести его в исходное состояние выставляется INIT#. Сигнал AUTOFD# используется при работе с матричными принтерами в текстовом режиме для продвижения бумаги на одну строку.
Для организации обратного канала (передача данных от принтера в компьютер) в режиме SPP возможны два механизма: механизм двунаправленного порта (впервые представленный в IBM PS/2 в 1987 г.) и механизм передачи полубайтами (Nibble Mode). При использовании механизма двунаправленного порта способ квитирования не декларируется.
Особенностью обратного канала в Nibble Mode является то, что за один цикл передается только 4 бита данных. Таким образом, скорость в обратном канале в два раза меньше, чем в прямом канале. Преимуществом использования Nibble Mode является возможность программной реализации этого механизма на любом старом параллельном порту, не поддерживающем IEEE 1284. Сигналом активности этого механизма является высокий уровень на линии NibbleMode (при прямой передаче на этой линии выставляется низкий уровень). Для квитирования используются линии HostBusy (сигнал устанавливается компьютером в низкий уровень, когда он готов к приему) и PtrClk (низкий уровень сигнала подтверждает действительность данных D[0:4]/D[5:7]).
В режиме EPP ( Улучшенный параллельный порт) используется аппаратная реализация сигналов квитирования, благодаря чему возможно увеличение скорости передачи до 2 Мбайт/с. Этот режим поддерживает адресацию устройств, благодаря чему возможно подключение нескольких (до 64) устройств к одному порту. Генерация цикла чтения или записи на шине IEEE 1284 со всеми необходимыми сигналами квитирования происходит при обращении к регистру EPP Address (BASE+3) или EPP Data (BASE+4). При этом адаптер IEEE 1284 устанавливает сигнал Write# в зависимости от направления передачи (низкий уровень - прямая передача, высокий уровень - обратная передача). Для периферийного устройства информацией о том, являются ли биты на линиях AD[0:7] данными или адресом, является сигналы DataStb# (строб данных) или AddrStb# (строб адреса). Периферийное устройство информирует компьютер о своей готовности принять очередной байт при помощи сигнала Wait#. Сигнал Reset#, так же как и в режиме SPP используется для инициализации устройства. Установка периферийным устройством сигнала Intr# вызывает генерацию прерывания. Сигналы AckDataReq и DataAvail# используются по усмотрению разработчика, например, для квитирования в обратном канале.
Режим ECP (Порт расширенных возможностей) также использует аппаратное квитирование и адресацию устройств (до 128). Дополнительно ECP поддерживает распознавание ошибок, согласование скорости и режима передачи, буферизацию данных в очереди FIFO (с использованием DMA) и их компрессию по алгоритму RLE (Run Length Encoding), что позволяет достигать скорость до 4 Мбайт/с.
Признаком активности режима ECP является высокий уровень сигнала 1284Active. При прямой передаче для квитирования используются сигналы HostClk и PeriphAck, а сигнал HostAck указывает на тип передаваемых данных: высокий уровень - обычные данные, низкий уровень - команда или адрес. Для запроса обратного канала компьютер выставляет сигнал ReverseReq#, который устройство подтверждает сигналом AckReverse#. В обратном канале для квитирования применяются сигналы PeriphClk и HostAck, а сигнал PeriphAck используется устройством для указания типа передаваемых данных.
Устройство может запросить обслуживание при помощи сигнала PeriphReq#.
В режиме ECP параллельный порт может эмулировать работу любого другого режима IEEE 1284, что определяется в соответствующих битах расширенного регистра управления (ECR) по адресу BASE+400h:
| 0002 | SPP | Режим стандартного параллельного порта с программным квитированием |
| 0012 | Bi-directional mode | Поддержка обратного канала для режима SPP, как в IBM PS/2 |
| 0102 | Fast Centronics | Режим стандартного параллельного порта с аппаратным квитированием |
| 0112 | ECP | Режим ECP с поддержкой FIFO и RLE |
| 1002 | EPP | Режим EPP |
| 1012 | Reserved | |
| 1102 | Test mode | Режим самотестирования FIFO и прерываний |
| 1112 | Configuration mode | Режим конфигурирования |
Интерфейс IEEE 1394 - FireWire
Группой компаний при активном участии Apple была разработана технология последовательной высокоскоростной шины, предназначенной для обмена цифровой информацией между компьютером и другими электронными устройствами. В 1995 году эта технология была стандартизована IEEE (стандарт IEEE 1394-1995). Компания Apple продвигает этот стандарт под торговой маркой FireWire, а компания Sony - под торговой маркой i-Link.
Интерфейс IEEE 1394 представляет собой дуплексную, последовательную, общую шину для периферийных устройств. Она предназначена для подключения компьютеров к таким бытовым электронным приборам, как записывающая и воспроизводящая видео- и аудиоаппаратура, а также используется в качестве интерфейса дисковых накопителей (таким образом, она соперничает с шиной SCSI).
Первоначальный стандарт (1394a) поддерживает скорости передачи данных 100 Мбит/с, 200 Мбит/с и 400 Мбит/с. Последующие усовершенствования стандарта (1394b) обеспечивают поддержку скорости передачи данных 800 и 1600 Мбит/с (FireWire-800, FireWire-1600).
Устройства, которые передают данные на разных скоростях, могут быть одновременно подключены к кабелю (поскольку пары обменивающихся данными устройств используют для этого одну и ту же скорость). Рекомендуемая максимальная длина кабеля между устройствами составляет 4,5 м. К кабелю общей длиной до 72 м может быть одновременно подключено до 63 устройств, называемых узлами (nodes). Для увеличения числа шин вплоть до максимального значения (1023) могут быть использованы мосты.
Каждое устройство обладает 64-разрядным адресом:
6 бит - идентификационный номер устройства на шине,10 бит - идентификационный номер шины,48 бит - используются для адресации памяти (каждое устройство может адресовать до 256 Тбайт памяти).
Шина предполагает наличие корневого узла, выполняющего некоторые функции управления. Корневой узел может быть выбран автоматически во время инициализации шины, либо его атрибут может быть принудительно присвоен конкретному узлу (скорее всего, ПК). Некорневые узлы являются или ветвями (если они поддерживают более чем одно активное соединение), или листьями (если они поддерживают только одно активное соединение).
Как правило, устройства имеют по 1-3 порта, причем одно устройство может быть включено в любое другое (с учетом ограничений на то, что между любыми двумя устройствами может быть не более 16 пролетов и они не могут быть соединены петлей). Допускается подключение в "горячем" режиме, поэтому устройства могут подключаться и отключаться в любой момент. При подключении устройств адреса назначаются автоматически, поэтому присваивать их вручную не придется.
IEEE 1394 поддерживает два режима передачи данных (каждый из которых использует пакеты переменной длины).
Асинхронная передача используется для пересылки данных по конкретному адресу с подтверждением приема и обнаружением ошибок. Трафик, который не требует очень высоких скоростей передачи данных и не чувствителен ко времени доставки, вполне подходит для данного режима (например, для передачи некоторой управляющей информации).Изохронная передача предполагает пересылку данных через равные промежутки времени, причем подтверждения приема не используются. Этот режим предназначен для пересылки оцифрованной видео- и аудиоинформации.
Пакеты данных пересылаются порциям, которые имеют размер, кратный 32 битам, и называются квадлетами (guadlets). При этом пакеты начинаются, по меньшей мере, с двух квадлетов заголовка, после чего следует переменное число квадлетов полезной информации. Для заголовка и полезных данных контрольные суммы (CRC) указываются отдельно. Длина заголовков асинхронных пакетов составляет, как минимум, 4 квадлета. У изохронных пакетов может быть заголовок длиной 2 квадлета, поскольку единственным необходимым при этом адресом является номер канала.
IEEE 1394 выделяет следующие функции устройств:
Хозяин цикла (cycle master) - выполняется корневым узлом, имеет наивысший приоритет доступа к шине, обеспечивает общую синхронизацию остальных устройств на шине, а также изохронных сеансов передачи данных.Диспетчер шины (bus manager) управляет питанием шины и выполняет некоторые функции оптимизации.Диспетчер изохронных ресурсов (isochronous resource manager) распределяет временные интервалы среди узлов, собирающихся стать передатчиками (talkers).
Все функции диспетчеризации могут выполняться одним и тем же либо различными устройствами. Хозяин цикла посылает синхронизирующее сообщение о начале цикла через каждые 125 мкс (как правило). Теоретически 80% цикла (100 мкс) резервируется для изохронного трафика, а остальная часть становится доступной для асинхронного трафика. Сначала узлы с изохронными данными для пересылки, а также те узлы, которым был назначен номер канала, пытаются получить доступ к шине на время передачи (сразу же после каждого сообщения о начале цикла), и узел, который ближе всего находится к корневому узлу, первым получит разрешение на передачу данных. Каждый последующий узел с назначенным номером канала и изохронным трафиком для пересылки последовательно получает разрешение на передачу данных. Затем пытаются получить доступ к шине и узлы с асинхронным трафиком.
Для подключения к данному интерфейсу применяется 6-контактный соединитель. Используемый при этом кабель имеет круглую форму и содержит:
экранированную витую пару А (ТРА), в которой используется симметричное, разностное напряжение (для обеспечения требуемой помехоустойчивости), а данные передаются в обоих направлениях с помощью схемы кодирования NRZ1). Фактически напряжение составляет 172-265 мВ;экранированную витую пару В (ТРВ), пересылающую стробирующий сигнал, который изменяет состояние всякий раз, когда два последовательных разряда данных (на другой паре) одинаковы (т.н. кодирование данных со стробированием - data-strobe encoding), и гарантирует изменение состояния в паре для передачи данных либо стробирующих сигналов по фронту каждого разряда;провода, обеспечивающие питание небольших устройств. При этом по проводу VP подается напряжение 8-40 В, обеспечивающее нагрузку до 1,5 А, а провод VG заземлен. Впрочем, существуют варианты соединения, в котором провода питания отсутствуют;а также общий экран, который изолирован от экранов пар и прикреплен к корпусам соединителей.
В IEEE 1394b допускается применять также простые UTP-кабели 5-й категории, но только на скоростях до 100 Мбит/с.Для достижения максимальных скоростей на максимальных расстояниях предусмотрено использование оптоволокна (пластмассового - для длины до 50 метров, и стеклянного - для длины до 100 метров).
Интерфейс RS-232C
Стандарт на последовательный интерфейс RS-232C был опубликован в 1969 г. Ассоциацией электронной промышленности (EIA). Первоначально этот интерфейс использовался для подключения ЭВМ и терминалов к системе связи через модемы, а также для непосредственного подключения терминалов к машинам. До недавнего времени последовательный интерфейс использовался для широкого спектра периферийных устройств (плоттеры, принтеры, мыши, модемы и др.), но сейчас активно вытесняется интерфейсом USB.
Стандарт RS-232C определяет:
механические характеристики интерфейса (разд.1) - разъемы и соединители;электрические характеристики сигналов (разд.2) - логические уровни;функциональные описания интерфейсных схем (разд.4) - протоколы передачи;стандартные интерфейсы для выбранных конфигураций систем связи (разд. 5).
В 1975 г. были приняты стандарты RS-422 (электрические характеристики симметричных цепей цифрового интерфейса) и RS-423 (электрические характеристики несимметричных цепей цифрового интерфейса), позволяющие увеличить скорость передачи данных по последовательному интерфейсу.
Обычно ПК имеют в своем составе два интерфейса RS-232C, которые обозначаются COM1 и COM2. Возможна установка дополнительного оборудования, которое обеспечивает функционирование в составе PC четырех, восьми и шестнадцати интерфейсов RS-232C. Для подключения устройств используется 9-контактный (DB9) или 25-контактный (DB25) разъем.
Интерфейс RS-232C содержит сигналы квитирования, обеспечивая асинхронный режим функционирования (табл. 15.2). При этом одно из устройств (обычно компьютер) выступает как DTE (Data Terminal Equipment - оконечное устройство), а другое - как DCE (Data Communication Equipment - устройство передачи данных), например, модем. Соответственно, если для DTE какой-то сигнал является входным, то для DCE этот сигнал будет выходным, и наоборот.
| FG | 1 | - | Fore Ground. Защитное заземление |
| TxD | 2 | 3 | Transmit Data. Данные, передаваемые DTE |
| RxD | 3 | 2 | Receive Data. Данные, принимаемые DTE |
| RTS | 4 | 7 | Request To Send. Запрос передачи, выставляется DTE |
| CTS | 5 | 8 | Clear To Send. Сигнал сброса для передачи, выставляется DCE при готовности к приему |
| DSR | 6 | 6 | Data Set Ready. Готовность данных, выставляется DCE при готовности к передаче |
| SG | 7 | 5 | Signal Ground. Сигнальное заземление, "нулевой" провод |
| DCD | 8 | 1 | Data Carrier Detect. Обнаружение несущей данных, выставляется DCE при детектировании принимаемого сигнала |
| DTR | 20 | 4 | Data Terminal Ready. Готовность DTE |
| RI | 22 | 9 | Ring Indicator. Индикатор вызова, выставляется DCE при приеме вызова по телефонной сети |
В то же время, в простейшем случае для обмена могут использоваться лишь три линии: TxD, RxD и SG - без использования сигналов квитирования.
Основные принципы обмена информацией по интерфейсу RS-232C заключаются в следующем:
Обмен данными обеспечивается по двум цепям, каждая из которых является для одной из сторон передающей, а для другой - приемной.В исходном состоянии по каждой из этих цепей передается двоичная единица, т.е. стоповая посылка. Передача стоповой посылки может выполняться сколь угодно долго.Передаче каждого пакета данных предшествует передача стартовой посылки, т.е. передача двоичного нуля в течение времени, равного времени передачи одного бита данных.После передачи стартовой посылки обеспечивается последовательная передача всех разрядов данных, начиная с младшего разряда. Количество битов может быть 5, 6, 7 или 8.После передачи последнего бита данных возможна передача контрольного разряда, который дополняет сумму по модулю 2 переданных разрядов до четности или нечетности. В некоторых системах передача контрольного бита не выполняется.После передачи контрольного разряда или последнего бита, если формирование контрольного разряда не предусмотрено, обеспечивается передача стоповой посылки. Минимальная длительность посылки может быть равной длительности передачи одного, полутора или двух бит данных.
Обмен данными по описанным выше принципам требует предварительного согласования приемника и передатчика по скорости (длительности бита) (300-115200 бит/с), количеству используемых разрядов в символе (5, 6, 7 или 8), правилам формирования контрольного разряда (контроль по четности, по нечетности или отсутствие контрольного разряда), длительности передачи стоповой посылки (1 бит, 1,5 бит или 2 бит).
Спецификация RS-232C для электрических характеристик сигналов определяет, что высокий уровень напряжения от +3В до +12В (при передаче - до +15В) считается логическим "0", а низкий уровень напряжения от 3В до 12В (при передаче - до 15В) считается логическим "1" (рис. 15.1).Диапазон сигналов 3В:+3В обеспечивает защиту от помех и стабильность передаваемых данных.

Рис. 15.1. Логические уровни интерфейса RS-232C
Интерфейс USB
Спецификация периферийной шины USB была разработана лидерами компьютерной и телекоммуникационной промышленности (Compaq, DEC, IBM, Intel, Microsoft, NEC и Northern Telecom) для подключения компьютерной периферии вне корпуса ПК с автоматическим автоконфигурированием (Plug&Play). Первая версия стандарта появилась в 1996 г. Агрессивная политика Intel по внедрению этого интерфейса стимулирует постепенное исчезновение таких низкоскоростных интерфейсов, как RS 232C, Access.bus и т.п. Однако для высокоскоростных устройств с более строгими требованиями к производительности (например, доступ к удаленному накопителю или передача оцифрованного видео) конкурентом USB является интерфейс IEEE 1394.
Интерфейс USB представляет собой последовательную, полудуплексную, двунаправленную шину со скоростью обмена:
USB 1.1 - 1,5 Мбит/с или 12 Мбит/с;USB 2.0 - 480 Мбит/с.
Шина позволяет подключить к ПК до 127 физических устройств. Каждое физическое устройство может, в свою очередь, состоять из нескольких логических (например, клавиатура со встроенным манипулятором-трекболом).
Кабельная разводка USB начинается с узла (host) (рис. 15.3). Хост обладает интегрированным корневым концентратором (root hub), который предоставляет несколько разъемов USB для подключения внешних устройств. Затем кабели идут к другим устройствам USB, которые также могут быть концентраторами, и функциональным компонентам (например, модем или акустическая система). Концентраторы часто встраиваются в мониторы и клавиатуры (которые являются типичными составными устройствами). Концентраторы могут содержать до семи "исходящих" портов.

Рис. 15.3. Топология подключения устройств к USB
Для передачи сигналов шина USB использует четырехпроводной интерфейс. Одна пара проводников ("+5В" и "общий") предназначена для питания периферийных устройств с нагрузкой до 500 мА. Данные передаются по другой паре ("D+" "D"). Для передачи данных используются дифференциальные напряжения до 3 В (с целью снижения влияния шума) и схема кодирования NRZI1) (что избавляет от необходимости выделять дополнительную пару проводников под тактовый сигнал).
Интерфейс USB 1.1 декларирует два режима:
низкоскоростной подканал (пропускная способность - 1,5 Мбит/с), предназначенный для таких устройств, как мыши и клавиатуры;высокопроизводительный канал, обеспечивающий максимальную пропускную способность 12 Мбит/с, что может использоваться для подключения внешних накопителей или устройств обработки и передачи аудио- и видеоинформации.
Все концентраторы должны поддерживать на своих исходящих портах устройства обоих типов, не позволяя высокоскоростному трафику достигать низкоскоростных устройств. Высокопроизводительные устройства подключаются с помощью экранированного кабеля, длина которого не должна превышать 3 м. Если же устройство не формулирует особых требований к полосе пропускания, его можно подключить и неэкранированным кабелем (который может быть более тонким и гибким). Максимальная длина кабеля для низкоскоростных устройств - 5 м. Требования устройства к питанию (диаметр проводников, потребляемая мощность) могут обусловить необходимость использования кабеля меньшей длины. Из-за особенностей распространения сигнала по кабелю число последовательно соединенных концентраторов ограничено шестью (и семью пятиметровыми отрезками кабеля).
Хост узнает о подключении или отключении устройства из сообщения от концентратора (эта процедура называется опросом шины - bus enumeration). Затем хост присваивает устройству уникальный адрес USB (1:127). После отключения устройства от шины USB его адрес становится доступным для других устройств.
Для индивидуального обращения к конкретным функциональным возможностям составного устройства применяется 4-битное поле конечной точки. В низкоскоростных устройствах за каждой функцией закрепляется не более двух адресов конечных точек: нулевая конечная точка используется для конфигурации и определения состояния USB, а также управления функциональным компонентом; а другая точка - в соответствии с функциональными возможностями компонента. Устройства с максимальной производительностью могут поддерживать до 16 конечных точек, резервируя нулевую точку для задач конфигурации и управления USB.
Хост опрашивает все устройства и выдает им разрешения на передачу данных (рассылая для этого пакет-маркер - Token Packet). Таким образом, устройства лишены возможности непосредственного обмена данными - все данные проходят через хост. Это условие сильно мешало внедрению интерфейса USB на рынок портативных устройств. В результате в конце 2001 года было принято дополнение к стандарту USB 2.0 - спецификация USB OTG (On-The-Go), предназначенная для соединения периферийных USB-устройств друг с другом без необходимости подключения к хосту (например, цифровая камера и фотопринтер). Устройство, поддерживающее USB OTG, способно частично выполнять функции хоста и распознавать, когда оно подключено к полноценному хосту (на основе ПК), а когда - к другому периферийному устройству. Спецификация описывает также протокол согласования выбора роли хоста при соединении двух USB OTG-устройств.
Данные на шине передаются транзакциями, интервал между которыми составляет 1 мс. Предусмотрено четыре типа транзакций.
Управляющие передачи используются для конфигурации вновь подключенных устройств (например, присвоения им адреса USB) и их компонентов. Устройства с максимальной производительностью могут быть настроены на работу с конфигурационными сообщениями длиной 8, 16, 32 или 64 байта (по умолчанию - 8 байт). Устройства с низкой производительностью в состоянии распознавать управляющие сообщения длиной не более 8 байт.
Групповая передача (bulk) используется для адресной пересылки данных большого объема (до 1023 байт). В качестве примера можно привести передачу данных на принтер или от сканера. Устройства с низкой производительностью не поддерживают этот режим.
Передача данных прерывания, например, введенных с клавиатуры данных или сведений о перемещении мыши. Эти данные должны быть переданы достаточно быстро для того чтобы пользователь не заметил никакой задержки. В соответствии со спецификациями время задержки USB составляет несколько миллисекунд.
Изохронные передачи (передачи в реальном масштабе времени).
Пропускная способность и задержка доставки оговариваются до начала передачи данных. К изохронным данным алгоритмы коррекции ошибок неприменимы (поскольку время на повторную их ретрансляцию превышает допустимый интервал задержки). За один сеанс в таком режиме может быть передано до 1023 байт. Устройства с низкой производительностью не поддерживают этот режим.
Следует также отметить, что разными производителями предлагались спецификации, описывающие интерфейс различных аппаратных реализаций контроллера USB. Фирмой Intel была предложена спецификация UHCI (Universal Host Controller Interface), которая предусматривает чрезвычайно простую аппаратную реализацию контроллера USB. В рамках данной спецификации основные функции контроля и арбитража шины возлагаются на программный драйвер. Альтернативная спецификация была предложена компаниями Compaq, Microsoft и National Semiconductor - OHCI (Open Host Controller Interface). Контроллеры по спецификации OHCI обладают унифицированным абстрактным интерфейсом, предусматривающим аппаратную реализацию большинства управляющих функций, что облегчает их программирование.
Интерфейсы SCSI
Интерфейс SCSI был разработан в конце 1970-х годов и предложен организацией Shugart Associates. Первый стандарт на этот интерфейс был принят в 1986 г. SCSI определяет только логический и физический уровень. Устройства, подключенные к шине SCSI, могут играть две роли: Initiator (ведущий) и Target (ведомый), причем одно и то же устройство может быть как ведущим, так и ведомым. К шине может быть подключено до восьми устройств. Каждое устройство на магистрали имеет свой адрес (SCSI ID) в диапазоне от 0 до 7. Одно из этих устройств - хост-адаптер SCSI. Ему обычно назначают SCSI ID = 7. Хост-адаптер предназначен для осуществления обмена с процессором. Хост-адаптер, как правило, имеет разъемы для подключения как встраиваемых, так и внешних SCSI-устройств.
Стандарт SCSI определяет два способа передачи сигналов - синфазный и дифференциальный. В первом случае сигналы на линиях имеют ТТЛ-уровни, при этом длина кабеля ограничена 6 м. Версии шины SCSI с дифференциальной передачей сигнала ("токовой петлей") дают возможность увеличить длину шины до 25 м.
Чтобы гарантировать качество сигналов на магистрали SCSI, линии шины должны быть с обеих сторон согласованы при помощи набора согласующих резисторов, или терминаторов. Терминаторы должны быть установлены на хост-адаптере и на последнем устройстве магистрали. Обычно используют один из трех методов согласования:
пассивное согласование при помощи резисторов;FPT (Force Perfect Termination) - улучшенное согласование с исключением перегрузок при помощи ограничительных диодов;активное согласование при помощи регуляторов напряжения.
Обмен данными между устройствами на шине SCSI происходит в соответствии с протоколом высокого уровня на основе стандартного списка команд - CCS (Common Command Set). Этот универсальный набор команд обеспечивает доступ к данным с помощью адресации логических, а не физических блоков. С внедрением в спецификацию CSS команд, поддерживающих приводы CD-ROM, коммуникационные устройства, сканеры и др. (стандарт SCSI-2), стала осуществимой работа практически с любыми блочными устройствами.
На магистрали SCSI возможны синхронные и асинхронные передачи. В асинхронном режиме передача данных сопровождается сигналом запроса и заканчивается только после получения сигнала подтверждения. При синхронной передаче данных ведущее устройство не дожидается сигналов подтверждения перед выдачей сигнала запроса и приема следующих данных. После выдачи определенной серии импульсов запроса ведущее устройство сравнивает его с числом подтверждений, чтобы удостовериться, что группа данных принята успешно. Т.к. в этом режиме все равно участвуют сигналы квитирования, его еще называют асинхронным с согласованием скорости.
В исходном стандарте шина SCSI имеет восемь линий данных. Для повышения производительности в спецификацию SCSI-2 введен так называемый широкий (Wide) вариант шины данных, предусматривающий наличие дополнительных 24 разрядов. Для повышения пропускной способности шины SCSI было предложено увеличить тактовую частоту обмена примерно в два раза, что послужило основой нового стандарта - Fast SCSI-2. Дальнейшее увеличение пропускной способности шины привело к появлению стандарта UltraSCSI (см. табл. 15.1).
| SCSI | 5 Мбайт/с | 10 Мбайт/с | 20 Мбайт/с | 6 м |
| Fast SCSI | 10 Мбайт/с | 20 Мбайт/с | 40 Мбайт/с | 3 м |
| UltraSCSI | 20 Мбайт/с | 40 Мбайт/с | 80 Мбайт/с | 1,5 м |
Назовите режимы передачи интерфейса SCSI
Назовите режимы передачи интерфейса SCSI и охарактеризуйте каждый режим.Назовите особенности стандартного последовательного интерфейса RS-232C.Как в стандарте RS-232C определены высокий и низкий уровни напряжения?К чему относится понятие Centronics?Перечислите последовательные интерфейсы ввода/вывода.Назовите протоколы, входящие в стек IrDA, и их назначение.Охарактеризуйте топологию интерфейсов USB и FireWire.Сравните технические характеристики интерфейсов USB и FireWire.
Классификация периферийных устройств
Периферийное устройство (ПУ) - устройство, входящее в состав внешнего оборудования микро-ЭВМ, обеспечивающее ввод/вывод данных, организацию промежуточного и длительного хранения данных.
Можно выделить следующие основные функциональные классы периферийных устройств.
ПУ, предназначенные для связи с пользователем. К ним относят различные устройства ввода (клавиатуры, сканеры, а также манипуляторы - мыши, трекболы и джойстики), устройства вывода (мониторы, индикаторы, принтеры, графопостроители и т.п.) и интерактивные устройства (терминалы, ЖК-планшеты с сенсорным вводом и др.)Устройства массовой памяти (винчестеры1), дисководы2), стримеры3) , накопители на оптических дисках, флэш-память4) и др.)Устройства связи с объектом управления (АЦП, ЦАП, датчики, цифровые регуляторы, реле и т.д.)Средства передачи данных на большие расстояния (средства телекоммуникации) (модемы, сетевые адаптеры).
Клавиатура
Основным устройством ввода информации в компьютер является клавиатура, которая представляет собой совокупность механических датчиков, воспринимающих давление на клавиши и замыкающих тем или иным образом определенную электрическую цепь. В настоящее время распространены два типа клавиатур: с механическими или с мембранными переключателями. В первом случае датчик представляет собой традиционный механизм с контактами из специального сплава. Во втором случае переключатель состоит из двух мембран: верхней - активной, нижней - пассивной, разделенных третьей мембраной-прокладкой.
Как правило, внутри корпуса любой клавиатуры, кроме датчиков клавиш, расположены электронные схемы дешифрации и микроконтроллер. Обмен информации между клавиатурой и системной платой осуществляется по специальному последовательному интерфейсу 11-битовыми блоками. Основной принцип работы клавиатуры заключается в сканировании переключателей клавиш. Замыканию и размыканию любого из этих переключателей соответствует уникальный цифровой код - скан-код. В случае, когда клавиша отпускается, клавиатура IBM PC AT предваряет скан-код кодом F016. Когда контроллер клавиатуры фиксирует нажатие или отпускание клавиши, он инициирует аппаратное прерывание IRQ1. Если в клавиатурах компьютеров типа IBM PC XT передача данных может осуществляться только в одном направлении, то в клавиатурах типа IBM PC AT подобная связь возможна уже в двух направлениях, т. е. клавиатура может принимать специальные команды (установки параметров задержки автоповтора и частоты автоповтора). Подключение клавиатуры к системной плате выполняется посредством электрически идентичных разъемов 5 DIN5) или 6 mini-DIN, последний впервые был представлен в IBM PS/2, откуда и унаследовал свое "жаргонное" название. Для обеспечения двунаправленного обмена используется единственная линия данных, требующая, однако, выводов с открытым коллектором.
Монитор
Монитор (дисплей) - устройство визуализации текстовой или графической информации без ее долговременной фиксации. По типу отображаемой информации мониторы делят на алфавитно-цифровые (в настоящее время не используются) и графические. По способу формирования изображения графические дисплеи делят на векторные (не используются в ПК) и растровые. В векторном дисплее изображение строится из элементарных отрезков векторов (в случае ЭЛТ - электронный луч непрерывно "вырисовывает" контур изображения, собирая его из этих векторов). В растровых дисплеях изображение получают с помощью матрицы точек (в случае ЭЛТ - электронные лучи пробегают по строкам экрана, подсвечивая требуемые точки своим цветом). Наиболее широкое распространение получили мониторы на базе электронно-лучевых трубок (ЭЛТ) и на основе жидких кристаллов (ЖК).
Принцип действия ЭЛТ-мониторов заключается в том, что испускаемый электродом (электронной пушкой) пучок электронов, попадая на экран, покрытый люминофором, вызывает его свечение (рис. 16.2). На пути пучка электронов находятся дополнительные электроды: отклоняющая система (определяет направление пучка) и модулятор (регулирует яркость получаемого изображения). В случае цветного монитора имеются три электронных пушки с отдельными схемами управления, а на поверхность экрана нанесен люминофор трех основных цветов: R (red) - красный, G (green) - зеленый, B (blue) - синий. Чтобы каждая пушка попадала только по люминофору своего цвета, используется теневая маска. Электронный луч периодически сканирует весь экран, образуя близкорасположенные строки развертки. По мере движения луча по строкам видеосигнал, подаваемый на модулятор, изменяет яркость определенных пикселей, образуя видимое изображение. В цикле сканирования луч движется по зигзагообразной траектории от левого верхнего угла экрана к нижнему правому. Прямой ход луча по горизонтали осуществляется сигналом строчной (горизонтальной) развертки, а по вертикали - сигналом кадровой (вертикальной) развертки.

Рис. 16.2. Устройство ЭЛТ: 1 - электронные пушки, 2 - отклоняющая система, 3 - теневая маска, 4 - люминофоры
Очевидно, наиболее важными параметрами для монитора являются: частота кадровой развертки, частота строчной развертки и полоса пропускания видеосигнала. Частота кадровой развертки во многом определяет устойчивость изображения (отсутствие мерцаний). Ассоциация VESA1) рекомендует использовать для разрешений 640х480 и 800х600 частоту кадровой развертки не ниже 72 Гц, а для разрешения 1024х768 - не ниже 70 Гц. Современные мониторы поддерживают кадровые развертки в диапазоне 60-160 Гц. Частота строчной развертки определяется произведением частоты вертикальной развертки на количество выводимых строк в одном кадре с учетом обратного хода (разрешение по вертикали), типичное значение - 30-64 кГц (отражает количество строк, которое монитор может воспроизвести за одну секунду). Полоса видеосигнала определяется произведением разрешения по горизонтали с учетом обратного хода на частоту строчной развертки (отражает число точек в строке, которое монитор может воспроизвести за одну секунду). К важным факторам, определяющим четкость изображения, относят также размеры точек люминофора, а точнее - расстояние между ними (dot pitch), типичное значение - 0,25-0,28 мм.
Работа ЖК-мониторов основана на свойстве некоторых веществ проявлять анизотропию в текучем ("жидком") состоянии. Первый ЖК-монитор был продемонстрирован американской фирмой RCA в 1966 году. Для изготовления ЖК-мониторов используют так называемые нематические кристаллы, молекулы которых имеют форму палочек или вытянутых пластинок. В отсутствии электрического поля молекулы этого вещества образуют скрученные спирали (обычно 90?). В результате такой ориентации молекул плоскость поляризации проходящего света поворачивается. Если же к прозрачным электродам приложено напряжение, спираль молекул распрямляется (они ориентируются вдоль поля), при этом поворота плоскости поляризации проходящего света не происходит.
Используя подходящим образом ориентированный пленочный поляризатор, можно добиться, чтобы в первом случае ЖК-элемент пропускал проходящий свет, а во втором - нет.
Таким образом, каждая точка изображения на ЖК-мониторе представляет из себя соответствующий TSTN2) -элемент, а весь экран - матрицу этих элементов. Для адресации ЖК-элементов можно использовать два метода: прямой (пассивный) и косвенный (активный). При прямой адресации элементов каждая выбираемая точка изображения активируется подачей напряжения на соответствующий проводник-электрод для строки (общий для целой строки) и на проводник-электрод для столбца (общий для всего столбца). Матрицы с пассивным управлением ("пассивные матрицы") имеют недостаточный контраст изображения, т.к. электрическое поле возникает не только в точке пересечения адресных проводников, но и на всем пути распространения тока. Эта проблема решается при использовании так называемых активных матриц, когда каждой точкой изображения управляет свой независимый электронный переключатель (как правило, TFT3)).
При применении активных матриц большое значение имеют такие параметры, как малое время отклика (типичное значение - 10-25 мкс) и большой угол зрения (75?-120?).
При подключении мониторов к видеокарте используются в основном два типа разъемов: разъем DB-15 с аналоговым видеосигналом и опционально с цифровым интерфейсом DDC4) и разъем DVI (Digital Visual Interface), позволяющий передавать как аналоговый видеосигнал, так и цифровой.
Мышь
Первую компьютерную мышь создал Дуглас Энджельбарт в 1963 году в Стэндфордском исследовательском центре. Распространение мыши получили благодаря росту популярности программных систем с графическим интерфейсом пользователя. Мышь делает удобным манипулирование такими широко распространенными в графических пакетах объектами, как окна, меню, кнопки, пиктограммы и т.д.
Первая мышь при движении вращала два колеса, которые были связаны с осями переменных резисторов. Перемещение курсора такой мыши вызывалось изменением сопротивления переменных резисторов. Большинство современных мышей имеют оптико-механическую конструкцию (рис. 16.1). С поверхностью, по которой перемещают мышь, соприкасается тяжелый обрезиненный шарик сравнительно большого диаметра. При перемещении мыши этот шарик может вращать прижатые к нему два перпендикулярных ролика. Ось вращения одного из роликов вертикальна, а другого - горизонтальна. На оси роликов установлены датчики, представляющие собой диски с прорезями, по разные стороны которых располагаются оптопары "светодиод-фотодиод". Порядок, в котором освещаются фоточувствительные элементы одной оси, определяет направление перемещения мыши, а частота приходящих от них импульсов - скорость.

Рис. 16.1. Устройство оптико-механической мыши
Другой популярной конструкцией мыши является полностью оптическая конструкция. С помощью светодиода и системы линз, фокусирующих его свет, под мышью подсвечивается участок поверхности. Отраженный от этой поверхности свет, в свою очередь, собирается другой линзой и попадает на приемный сенсор микросхемы процессора обработки изображений. Этот чип делает снимки поверхности под мышью с высокой частотой и обрабатывает их. На основании анализа череды последовательных снимков, представляющих собой квадратную матрицу из пикселей разной яркости, интегрированный DSP-процессор высчитывает результирующие показатели, свидетельствующие о направлении перемещения мыши вдоль осей Х и Y, и передает результаты своей работы на периферийный интерфейс.
Основные характеристики, обеспечивающие надежность работы оптических мышей, определяются техническими параметрами применяемых сенсоров (табл. 16.1).
| Марка сенсора | HDNS-2000 | ADNS-2620 | ADNS-2051 | ADNS-3060 |
| Разрешение, cpi (точек на дюйм) | 400 | 400 | 400/800 | 400/800 |
| Размер "снимков", пикс. | 18x18 | 16x16 | 30x30 | |
| Макс. скорость, см/с | 30 | 30 | 35 | 100 |
| Макс. ускорение (в рывке), м/с2 | 1,5 | 2,5 | 1,5 | 150 |
| Частота снимков, кадр/с | 1500 | 1500/2300 | 500-2300 | 500-6400 |
| 1 | LB | RB | dY7 | dY6 | dX7 | dX6 |
| 0 | dX5 | dX4 | dX3 | dX2 | dX1 | dX0 |
| 0 | dY5 | dY4 | dY3 | dY2 | dY1 | dY0 |
Накопители с магнитным носителем
В настоящее время распространены три типа накопителей с магнитной записью информации: на жестких (несъемных) магнитных дисках (НЖМД или "винчестеры"), на гибких магнитных дисках (НГМД или флоппи-дисководы) и на магнитной ленте (НМЛ или стримеры).
НЖМД содержит один или несколько жестких алюминиевых или стеклянных дисков, покрытых слоем ферромагнитного материала, которые смонтированы на оси-шпинделе. Считывающие головки в рабочем режиме не касаются поверхности пластин благодаря тонкой прослойке воздуха (доли микрон), образуемой при быстром вращении дисков. Скорость вращения современных винчестеров составляет 5400-15000 об/мин. Информация записывается на диск в результате изменения ориентации магнитных доменов на участке поверхности диска под записывающей головкой. Для кодирования информации в первых винчестерах использовался метод MFM1). В этом случае "1" переводится в комбинацию "01", а "0" - в комбинацию "10", если следует за битом "0", или в "00", если следует за битом "1", что обеспечивает не более трех нулей подряд. При записи этой последовательности на диск логическая "1" кодируется сменой намагниченности на соответствующем участке, а логический "0" - отсутствием смены (рис. 16.3). Это означает, что один переход намагниченности соответствует 1-3 битам.

Рис. 16.3. Схема кодирования MFM
Впоследствии стала использоваться схема кодирования RLL2). Алгоритмы RLL обеспечивают такую закодированную последовательность, что длина поля записи (количество бит между переходами от "0" к "1" или от "1" к "0") ограничена определенным диапазоном [d+1; k+1]. Параметры d и k задаются модификацией алгоритма (обозначается RLL d,k). Для винчестеров использовался RLL 2,7: 8 бит данных перекодируются в 16 так, чтобы в последовательности встречалось не менее двух и не более семи нулей. Затем был внедрен RLL 3,9 (Advanced RLL) и т.п. Большинство современных накопителей используют ту или иную модификацию RLL.
Поверхность магнитного носителя в ее первозданном виде - это всего лишь магнитное покрытие, которое не готово к работе. Структура диска, включающая в себя дорожки (концентрические полоски, но которые разделена каждая сторона пластины), цилиндры (дорожки на обеих сторонах пластины, расположенные на окружностях с одинаковым радиусом) и сектора (участки дорожки, представляющие собой наименьший размер порции данных, которая может быть изменена в результате перезаписи), формируется при физическом (низкоуровневом) форматировании. В ходе этой операции контроллер накопителя записывает на носитель служебную информацию: байты синхронизации, указывающие на начало каждого сектора, идентификационные заголовки, состоящие из номеров головки, сектора и цилиндра, байты контрольной суммы CRC (Cyclic Redundancy Check) и коды обнаружения ошибок ECC (Error Correction Code); при этом происходит также маркировка дефектных секторов для исключения обращения к ним в процессе эксплуатации диска.
Все современные винчестеры поддерживают технологию SMART (Self-Monitoring, Analysis and Reporting Technology), которая предполагает выполнение внутренней диагностики винчестера, определяющей состояние двигателя, магнитных головок, рабочих поверхностей носителя и контроллера.
Определенный интерес представляют также накопители со сменным носителем: НГМД и НМЛ (последние реже используются в настольных системах).
Обычно дискета (floppy disk) представляет собой гибкую пластиковую пластину, покрытую ферромагнитным слоем. Эта пластина помещается в гибкую или жесткую оболочку, защищающую магнитный слой от физических повреждений. Запись и считывание дискет осуществляется с помощью специального устройства - дисковода (флоппи-дисковода). Дискеты обычно имеют функцию защиты от записи, посредством которой можно предоставить доступ к данным только в режиме чтения.
Первая дискета диаметром в 200 мм (8 дюймов) с соответствующим дисководом была представлена фирмой IBM в 1971. В первых моделях IBM PC использовались дискеты диаметром 133 мм (5? дюйма).
В 1982 году фирма Sony представила дискеты диаметром 90 мм (3? дюйма) и дисководы для них. Широкое распространение этот тип дискет получил в 1984 году, когда Apple использовала новый формат для компьютеров Macintosh. Фирма IBM приняла решение использовать 3,5-дюймовые дисководы только в 1987 году в компьютерах серии PS/2. Наиболее популярные форматы дискет представлены в табл. 16.3. При записи на дискету используется кодирование MFM.
Внутренние дисководы подключаются при помощи интерфейса SA-400, разработанного в начале 1970-х годов компанией Shugart Associates. Интерфейс относится к категории интерфейсов на уровне устройства, т.к. содержит сигналы, характерные для функций устройства (Motor On - включить мотор, Index - проход индексной метки, Side 1 Select - выбор головки и т.п.) Интерфейс обеспечивает скорость порядка 300 Кбит/с.
| Тип дискеты3) | 5?" DS/DD | 5?" DS/QD | 3?" DS/DD | 3?" DS/HD | 3?" DS/ED |
| Размер, Кбайт | 360 | 1200 | 720 | 1440 | 2880 |
| Год выпуска | 1978 | 1984 | 1984 | 1987 | 1991 |
| Дорожек/секторов4) | 40/9 | 80/15 | 80/9 | 80/18 | 80/36 |
| DDS (Digital Data Storage), разработан Sony и Hewlett Packard | |||||
| DDS-1 | 1989 | 3,8 | 60/90 | 1,3/2,0 | 0,6 |
| DDS-2/3/4 | 1993/96/99 | 120/125/150 | 4,0/12/20 | 0,6/1,1/2,4 | |
| DAT 72 | 2003 | 170 | 36 | 3,5 | |
| DLT (Digital Linear Tape), разработан Digital Equipment Corporation | |||||
| CT I/II | 1984 | 12,6 | 0,1/0,3 | 0,045 | |
| DLT III/IV | 1989 | 2,6-40 | 0,8-6 | ||
| SDLT I/II | 1998 | 110-300 | 10-36 | ||
| LTO (Linear Tape-Open), разработан Certance, Hewlett Packard и IBM | |||||
| LTO1 | 1999 | 100-200 | 20-40 | ||
| LTO2 | 2002 | 200-400 | 40-80 | ||
| LTO3 | 2005 | 400-800 | 80-160 | ||
| AIT (Advanced Intelligent Tape), разработан Sony | |||||
| AIT-1/2 | 1996/99 | 8,0 | 170/230 | 25/50 | 3/6 |
| AIT-3/4 | 2001/05 | 230/246 | 100/200 | 12/24 | |
| QIC-MC (Quarter Inch Cartridge - MiniCartridge), разработан на основе DataCartridge фирмы 3M | |||||
| QIC-40-MC | 1983-1997 | 6,35/8,00 | 62,5/93,5 | 0,040/0,060 | 0,06 |
| QIC-80-MC | 62,5-305 | 0,080-0,530 | 0,06 | ||
| QIC-30x0-MC | 122-305 | 0,340-2 | 0,06-1 | ||
| QIC-3110-MC | 122 | 2 | |||
| QIC-3210-MC | 122 | 1,8/2,3 | |||
| QIC-3230-MC | 228 | 15,5 | |||
Накопители с оптическим носителем
Под накопителем для оптических носителей чаще всего подразумевают привод для компакт-дисков (CD). Компакт-диск был создан в 1979 году компаниями Philips и Sony. В Philips разработали общий процесс производства, основываясь на своей более ранней технологии лазерных дисков, а Sony выработала методику коррекции ошибок.
Компакт-диски изготавливаются из поликарбоната толщиной 1,2 мм, покрытого тончайшим слоем алюминия с защитным слоем из лака, на котором обычно печатается этикетка. Компакт-диски диаметром 12 см вмещают до 650 Мбайт информации (74 мин. аудио). Используются также CD объемом 700 Мбайт (80 мин. аудио), 800 Мбайт (90 мин. аудио) и более, однако они могут не читаться на некоторых приводах компакт-дисков. Бывают также мини-CD диаметром 8 см, вмещающие 140 Мбайт данных (21 мин. аудио).
Информация на диске хранится в виде спиральной дорожки так называемых питов (углублений), выдавленных на поликарбонатном слое. Каждый пит имеет примерно 125 нм в глубину, 500 нм в ширину и длину от 850 нм до 3,2 мкм. Расстояние между соседними дорожками спирали - 1,5 мкм. Данные с диска читаются при помощи лазерного луча с длиной волны 780 нм, который просвечивает поликарбонатный слой, отражается от алюминиевого и считывается фотодиодом. Луч лазера образует на отражающем слое пятно диаметром примерно 1,5 мкм. Т.к. диск читается с нижней стороны, каждый пит выглядит для лазера как возвышение. Места, где такие возвышения отсутствуют, называются площадками. Свет от лазера, попадающий на площадку, отражается и улавливается фотодиодом. Если же свет попадает на возвышение, он испытывает интерференцию со светом, отраженным от площадки вокруг возвышения, и не отражается. Так происходит потому, что высота каждого возвышения равняется четверти длины волны света лазера, что приводит к разнице в фазах в половину длины волны между светом, отраженным от площадки, и светом, отраженным от возвышения. Таким образом, фиксируются логические "1" и "0" (рис. 16.4), соответствующие исходным данным в коде EFM5) Для коррекции ошибок используется алгоритм CIRC6).

Рис. 16.4. Кодирование информации на CD с использованием EFM
Различают следующие виды компакт-дисков: CD-ROM, CD-R и CD-RW. Обычные компакт-диски (CD-ROM) штампуются на заводах при помощи стеклянной матрицы с вытравленным на ней рисунком дорожек, которой прессуется металлический слой диска.
CD-R - это однократно записываемый компакт-диск. Он состоит из пластиковой основы и записывающего слоя, представляющего собой слой органического красителя (цианин, металлизированный AZO или фталоцианин) и отражающий слой из серебра, его сплава или золота. Отражающий слой покрывается защитным лаком. Чистый CD-R не является полностью пустым, на нем имеется служебная дорожка с сервометками ATIP7). Эта служебная дорожка нужна для системы слежения, которая удерживает луч лазера при записи на дорожке и следит за скоростью записи. Помимо функций синхронизации служебная дорожка также содержит информацию об изготовителе этого диска, сведения о материале записывающего слоя, длине дорожки для записи и т.п. Служебная дорожка не разрушается при записи данных на диск. При записи CD-R данные наносятся на диск лучом лазера повышенной мощности, чтобы физически "прожечь" органический краситель записывающего слоя. Когда краситель нагревается выше определенной температуры, он разрушается и меняет отражательные свойства (темнеет). Управляя мощностью лазера, на записывающем слое можно получить чередование темных и светлых пятен, которые при чтении интерпретируются как питы. При чтении лазер имеет значительно меньшую мощность, чем при записи, и не разрушает краситель записывающего слоя. Отраженный от слоя серебра луч попадает на фотодиод; если же луч падает на темный ("прожженный") участок, то почти не проходит через него до отражающего слоя и фотодиод регистрирует ослабление светового потока. Прожигание записывающего слоя является необратимым химическим процессом, т.е. однократным, поэтому записанную на CD-R информацию нельзя стереть.
CD-RW - это перезаписываемый компакт-диск.
Технология CD-RW была представлена в 1997 году. В CD- RW записывающий слой состоит из материала с фазовым переходом (обычно сплав AgInSbTe). При помощи ИК-лазера кристаллические участки записывающего слоя быстро нагреваются и переходят в аморфное состояние или трансформируются при более низкой температуре и более длительном нагреве обратно в кристаллическое состояние. Различие в коэффициентах отражения аморфных и кристаллических областей интерпретируется как питы и площадки. Однако уровень сигналов в таком случае получается ниже, чем декларируется стандартами CD-ROM и CD-R, поэтому компакт-диски CD-RW могут не читаться в приводах, выпущенных до 1997 г.
Основным стандартом, который определяет логический и файловый форматы записи компакт-дисков, является ISO 9660 (файловая система компакт-дисков). Ряд других стандартов, касающихся компакт-дисков, изложен в документах, называемых "цветными книгами":
"Red Book" ("Красная книга") описывает аудио-CD (CD Digital Audio). В соответствии с этой спецификацией на компакт-диск можно записывать звук в два канала с 16-битной импульсно-кодовой модуляцией (PCM) и частотой дискретизации 44,1 кГц. Спецификация была предложена фирмами Philips и Sony в 1980 г. и позднее была утверждена в качестве стандарта ISO/IEC 60908."Yellow Book" ("Желтая Книга") описывает формат CD-ROM, утверждена в качестве стандартов IEC/ISO 10149 и ECMA8) 130."Orange Book" ("Оранжевая книга") представляет собой серию технических стандартов, связанных с CD-R и CD-RW."White Book" ("Белая книга") была выпущена в 1987 г. фирмами Philips, Matsushita и JVC и описывает формат Video-CD: файловая система, совместимая с ISO 9660, двухканальный (стерео) аудиопоток 224 кбит/с с частотой дискретизации 44,1 кГц в формате MPEG 1 Layer 2, видеопоток 352х240 30 кадр/с (NTSC) или 352x288 25 кадр/с (PAL) в формате MPEG 1 (примерно 1,13 Мбит/с).
В сентябре 1995 г. группой компаний (Philips, Sony, Toshiba и др.), позднее образовавших DVD Forum, была предложена спецификация оптических дисков высокой плотности - DVD9).
DVD представляет собой две склеенных пластины из поликарбоната толщиной по 0,6 мм, покрытых отражающим слоем из алюминия или золота. Один слой способен хранить 4,38 Гбайт информации. Для чтения DVD используется лазер с длиной волны 650 нм и большей, чем у лазеров для CD, апертурой, что позволяет значительно увеличить плотность записи. Кроме того, в DVD используется более эффективные алгоритмы кодирования (EFM-Plus10)) и коррекции ошибок (RS-PC11)).
DVD по структуре данных бывают трех типов: DVD-Video, DVD-Audio и DVD-Data. В отличие от CD, все три типа DVD хранят данные в формате файловой системе UDF.
Различают следующие типы носителей DVD:
DVD-ROM - штампованные на заводе диски;DVD-R/RW (DL) - однократно (RW - многократно) записываемые диски, стандартизованные DVD Forum (Double Layer - двухслойные);DVD-RAM - многократно записываемые диски с произвольным доступом (RAM - Random Access Memory);DVD+R/RW (DL) - однократно (RW - многократно) записываемые диски, предложенные DVD+RW Alliance (Double Layer - двухслойные).
Стандарт записи DVD-R/RW был разработан консорциумом DVD Forum как официальная спецификация (пере)записываемых дисков. Однако цена лицензии на эту технологию была слишком высока, и поэтому несколько производителей пишущих приводов и носителей для записи объединились в DVD+RW Alliance, который и разработал стандарт DVD+R/RW. Стоимость лицензии на эту спецификацию ниже. Стандарты записи DVD+R/RW и DVDR/RW частично совместимы. Все приводы для DVD могут читать оба формата дисков, и большинство пишущих приводов также могут записывать диски обеих технологий.
DVD-RAM по технологии ближе к винчестерам, чем к компакт-дискам, т.к. вместо одной спиральной дорожки содержит множество концентрических дорожек. Технология произвольного доступа обеспечивает работу с DVD-RAM как с обычным сменным накопителем (возможна произвольная запись, как на дискету или винчестер, без использования специального ПО).
По объему выделяют следующие категории DVD-дисков:
DVD-5 - однослойные односторонние 4,7 гигабайт (4,38 Гбайт);DVD-9 - двухслойные односторонние 8,5 гигабайт (7,92 Гбайт);DVD-10 - однослойные двухсторонние 9,4 гигабайт (8,75 Гбайт);DVD-18 - двухслойные двухсторонние 17,1 гигабайт (15,9 Гбайт).
Скорость CD-приводов указывается в единицах, кратных 150 Кбайт/с (1х), а DVD-приводов - в единицах, кратных 1352 Кбайт/с (что соответствует 9х для CD-привода). Обычно внутренние CD- и DVD-приводы подключаются через интерфейс EIDE/ATA или SCSI, а внешние - через SCSI, USB или FireWire.
Принтеры
Под принтером обычно подразумевают устройство вывода данных, преобразующее информацию в удобную для чтения форму на бумаге. Принтеры классифицируют по следующим критериям:
По способу печати: последовательные - печатный документ формируется символ за символом;строчные - при печати устройство формирует сразу всю строку целиком;страничные - на бумагу наносится изображение сразу всей страницы. По технологии печати: ударные (для переноса красящего вещества используется механический удар);безударные.
К ударным принтерам относят матричные принтеры. В них печатающая головка из 9, 18 или 24 игл, приводимых в движение электромагнитами, крепится к каретке и перемещается вместе с ней по направляющим параллельно бумаге вдоль печатаемой строки. Часть игл матрицы приводится в движение, и они "ударяют" по красящей ленте, находящейся между головкой и бумагой, формируя, таким образом, след из маленьких точек. К недостаткам этих принтеров относят низкую скорость печати и высокий уровень шума при работе. Достоинством же является то, что они оставляют оттиски букв на бумаге, а это важно при составлении финансовых или официальных документов. Следует отметить, что у этой технологии печати в общем случае нежесткие требования к качеству бумаги.
К безударным относят струйные чернильные принтеры. У них, так же как и у матричных, головка движется в горизонтальной плоскости над бумагой. Печатающая головка содержит сопла, через которые подаются чернила. У разных моделей количество сопел может варьироваться от 12 до 64. Различные технологии струйных принтеров отличаются способом выбрасывания чернильной капельки из сопла. В принтерах Cannon и Hewlett Packard используется технология bubble-jet (или thermal ink jet). В каждом сопле находится нагревательный элемент (тонкопленочный резистор). При резком нагревании образуется чернильный паровой пузырь, который выталкивает из сопла очередную порцию чернил. В принтерах Epson используется технология piezo ink jet. Выбросом капли из сопла управляет диафрагма из пьезоэлемента.
Под действием электрического поля пьезоэлемент деформируется и выталкивает каплю из сопла. Скорость работы струйных принтеров примерно такая же, как и у матричных. Несомненным преимуществом перед матричными принтерами является низкий уровень шума при работе. Однако следует иметь в виду, что струйные принтеры требуют высококачественной бумаги. В целом, необходимо отметить, что расходные материалы для данной технологии являются самыми дорогими, по сравнению с принтерами других технологий печати.
Другой популярной безударной технологией является технология электрографической печати, которая используется в так называемых лазерных принтерах. Луч микромощного полупроводникового лазера формирует электронное изображение на фотоприемном барабане. Барабану предварительно сообщается некий статический заряд. Таким образом, освещаемые и неосвещаемые лазером участки барабана имеют разный заряд. К заряженным участкам прилипают частицы порошкообразного тонера. При соприкосновении бумаги с барабаном на ней остается отпечаток, который фиксируется за счет нагрева частиц тонера до температуры плавления. Лазерные принтеры имеют высокую скорость печати и высокую разрешающую способность. Недостатком является высокая цена принтеров и необходимость использования качественной бумаги.
Для управления принтером используются специальные языки. Для матричных и струйных принтеров наибольшее распространение получил язык ESC/P5). Для лазерных и некоторых струйных принтеров основными языками управления являются PCL6) фирмы Hewlett Packard и PostScript фирмы Adobe.
Для подключения принтеров используют RS-232C, IEEE 1284 или USB.
Прочие устройства ввода - манипуляторы
Трекбол представляет собой "перевернутую" оптико-механическую мышь - в движение приводится не сам корпус устройства, а только его шар. Это позволяет существенно повысить точность управления курсором и, кроме того, экономить место, поэтому трекболы часто используют в ноутбуках.
Сенсорная панель (touchpad или trackpad) - это устройство ввода, применяемое в ноутбуках, служит для перемещения курсора в зависимости от движений пальца пользователя. Используется в качестве замены компьютерной мыши. Сенсорные панели различаются по размерам, но обычно их площадь не превосходит 50 см2. Работа сенсорной панели основана на измерении емкости пальца или измерении емкости между сенсорами. Емкостные сенсоры расположены вдоль вертикальной и горизонтальной осей панели, что позволяет определять положение пальца с нужной точностью. Поскольку работа устройства основана на измерении емкости, оно не будет работать, если водить по нему каким-либо непроводящим предметом, например, основанием карандаша. В случае использования проводящих предметов сенсорная панель будет работать только при достаточной площади соприкосновения, поэтому, например, работа с влажными пальцами весьма затруднена. Преимуществами сенсорных панелей являются:
отсутствует необходимость в ровной поверхности, как для мыши;расположение сенсорной панели, как правило, фиксировано относительно клавиатуры;для перемещения курсора на весь экран достаточно лишь небольшого перемещения пальца;работа с ними не требует особого привыкания, как, например, в случае с трекболом.
Недостатком же сенсорных панелей является низкое разрешение, что затрудняет работу в графических редакторах и 3D-играх.
Джойстик является аналоговым координатным устройством ввода информации, выполняемым обычно в виде двух реостатных датчиков с питанием +5 В. Рукоятка джойстика связана с двумя переменными резисторами, изменяющими свое сопротивление при ее перемещении. Один резистор определяет перемещение по координате Х, другой - по Y. Джойстик обычно подключается к адаптеру игрового порта, расположенному на многофункциональной плате ввода-вывода (Multi I/O Card) или звуковой карте (в последнем случае разъем игрового порта совмещается с интерфейсом MIDI). Очевидно, что основным элементом игрового адаптера является АЦП. Адаптер принимает до четырех цифровых сигналов типа "включено-выключено" (кнопки) и до четырех аналоговых сигналов, что позволяет подключать два 2-кнопочных джойстика.
Световое перо работает с помощью небольшого оптического детектора, находящегося на его кончике. По ходу сканирования экрана электронным лучом инициируется импульс оптического детектора, когда пучок достигает точки экрана, над которой находится перо. Время возникновения этого импульса относительно сигналов горизонтальной и вертикальной синхронизации позволяет определить позицию светового пера. По своей сути световое перо является расширением видеосистемы. Разъем для подключения светового пера был обязательным для видеоадаптеров CGA, встречался время от времени у видеоадаптеров EGA, но практически исчез с распространением VGA.
Сканер
Сканером называется устройство, которое позволяет вводить в компьютер образы изображений, представленных в виде текста, рисунков, слайдов, фотографий или другой графической информации. Сканеры можно классифицировать по следующим критериям:
По степени прозрачности вводимого оригинала изображения: непрозрачные оригиналы (фотографии, рисунки, страницы книг и журналов), при этом изображение снимается в отраженном свете;прозрачные оригиналы (слайды, негативы, пленки), при этом обрабатывается свет, прошедший через оригинал.По кинематическому механизму сканера: ручные сканеры - проблема ровного и равномерного перемещения сканирующей головки по соответствующему изображению (от чего зависит качество сканированного изображения) возлагается на пользователя;планшетные сканеры - сканирующая головка перемещается относительно бумаги с помощью шагового двигателя;рулонные сканеры - отдельные листы документов протягиваются через устройство так, что сканирующая головка остается на месте (неприменимы для сканирования книг и журналов);проекционные сканеры - вводимый документ кладется на поверхность сканирования изображением вверх, при этом блок сканирования также находится сверху, а перемещается только сканирующее устройство (возможно сканирование проекций трехмерных предметов).По типу вводимого изображения: черно-белые (штриховые или полутоновые);цветные.
В черно-белом сканере изображение освещается белым светом, получаемым, как правило, от флуоресцентной лампы. Отраженный свет через редуцирующую линзу попадает на фоточувствительный элемент (ПЗС-линейка или ПЗС-матрица). Каждая строка сканирования изображения соответствует определенным значениям напряжения на ПЗС. Эти значения напряжения преобразуются в цифровую форму через АЦП (для полутоновых сканеров) или через компаратор (для двухуровневых "штриховых" сканеров).
Для сканирования цветных изображений существует несколько технологий. Например, в сканерах фирмы Microtek сканируемое изображение поочередно освещается красным, зеленым и синим цветом, так что страница сканируется за три прохода. Похожий подход используется в сканерах Epson и Sharp, однако там смена цвета происходит для каждой строки, что позволяет избежать проблем с "выравниванием" пикселей при разных проходах. В сканерах Hewlett Packard и Ricoh сканируемое изображение освещается источником белого света, а отраженный свет через редуцирующую линзу попадает на трехполосную ПЗС-линейку через систему специальных фильтров, разделяющих свет на три компоненты: красный, синий, зеленый.
Для связи с компьютером сканеры, как правило, используют один из универсальных периферийных интерфейсов: SCSI, IEEE 1284 или USB.
Для унифицирования прикладного программного интерфейса драйвера сканера (а также цифровых камер) в 1992 г. компаниями Aldus, Caere, Eastman Kodak, Hewlett Packard и Logitech была разработана спецификация TWAIN6).
Сформулируйте основные принципы работы устройств
Дайте классификацию периферийных устройств. Сформулируйте основные принципы работы устройств ввода.Перечислите классы сканеров.Назовите типы дисплеев, физические принципы формирования изображения.Сравните принтеры различных технологий.Назовите виды внешней памяти ПК.Какие существуют способы записи информации на магнитные носители?Объясните, в чем преимущества RLL 2,7 перед MFM.Охарактеризуйте разновидности оптических дисков.Опишите оптические способы записи информации.
Фотоника
Фотоника - это технология излучения, передачи, регистрации света при помощи волоконной оптики и оптоэлектроники.
Довольно давно уже известна оптимальная среда для передачи огромных массивов данных - это свет, бегущий по волоконно-оптическим кабелям. А все компьютерные транзисторы работают с электрическим током, текущим по медным проводам. Исследователям лабораторий Intel удалось органически совместить кремний со светом - так родилась кремниевая фотоника.
16.февраля 2004 г. впервые было продемонстрировано устройство, передающее информацию по волоконно-оптическому кабелю со скоростью 1 Гбит в секунду!
Луч света, идущий по оптическому волокну, расщепляется на два луча, затем один из лучей проходит через специальное устройство, в котором световые колебания могут сдвигаться по фазе. После сложения лучей наблюдается интерференция. Наличие света считают "1", а его отсутствие - "0".
До сих пор существовали быстрые модуляторы (устройства, преобразующие свет в последовательность битов информации), но они были очень дорогими, сложными в производстве и делались с использованием экзотических материалов (таких как арсенид галлия или фосфид индия). Самые быстрые кремниевые модуляторы работали на скоростях около 20 МГц. Кремниевый модулятор Intel работает со скоростью более 1 ГГц, исследователи надеются повысить эту скорость еще раз в 10!
У кремниевой фотоники есть масса преимуществ. Прежде всего, это то, что по оптическому волокну можно передавать тысячи потоков сигналов на разных длинах световых волн, тогда как по медному проводу может идти лишь один ток. Теоретический предел для такой передачи близок к 100 триллионам бит в секунду - этого достаточно, чтобы передать по одному волокну (в 30 раз тоньше человеческого волоса) телефонные переговоры всех жителей Земли одновременно.
Микропроцессорная технология потенциально имеет много назначений: создание персональных электронных партнеров, интеллектуализация (в известном смысле "оживление") всей техносферы, усиление и защита функций организма с помощью персональных медико-кибернетических устройств, в том числе вживляемых в организм
В результате эволюции электронной технологии от "микро" к "нано" и ее слияния с "генной", вероятно, будет достигнуто состояние, при котором станет возможным синтез в массовых количествах любых технических устройств. Однако основная цель будущей нанотехнологии, по всей вероятности, - создание структур, способных к эволюции и саморазвитию.
Нанотехнологии
Нанотехнологии - это технологии, оперирующие величинами порядка нанометра. Это технологии манипуляции отдельными атомами и молекулами, в результате которых создаются структуры сложных спецификаций. Слово "нано" (в древнегреческом языке "nano" - "карлик") означает миллиардную часть единицы измерения и является синонимом бесконечно малой величины, в сотни раз меньшей длины волны видимого света и сопоставимой с размерами атомов. Поэтому переход от "микро" к "нано" - это уже не количественный, а качественный переход: скачок от манипуляции веществом к манипуляции отдельными атомами. Мир таких бесконечно малых величин намного меньше, чем мир сегодняшних микрокристаллов и микротранзисторов.
Основа нанофизики и нанотехнологии создана именно в нашей стране. Теоретические и первые экспериментальные работы в этой области были сделаны выдающимся российским ученым и изобретателем профессором П.К. Ощепковым (1908-1992). В его работах - обоснование физики ультратонких или, как сейчас говорят, наноструктур.
Российский ученый впервые теоретически обосновал положение о том, что переход на уровень нано означает не только количественный, но и качественный переход в новое состояние материи. Кроме того, Ощепков впервые высказал основные положения современной нанотехнологии об использовании волновых свойств электронов и их способности к туннелированию на наноструктурах для создания принципиально новых энергетических устройств.
Сейчас работы в области нанотехнологий ведутся в четырех основных направлениях:
молекулярная электроника; биохимические и органические решения; квазимеханические решения на основе нанотрубок;квантовые компьютеры.
На долю США ныне приходится примерно треть всех мировых инвестиций в нанотехнологии (Европейский Союз - примерно 15%, Япония - 20%). Исследования в этой сфере активно ведутся также в странах бывшего СССР, Австралии, Канаде, Китае, Южной Корее, Израиле, Сингапуре и Тайване. Если в 2000 году суммарные затраты стран мира на подобные исследования составили примерно 800 млн.долларов, то в 2001 году они увеличились вдвое.
По мнению экспертов, чтобы нанотехнологии стали реальностью, ежегодно необходимо тратить не менее 1 трлн.долларов.
В последнее время резко увеличилось количество публикаций о новых достижениях в области нанотехнологий. Самые свежие новости можно найти, например, на сайте http://www.nanonewsnet.com/. Ниже мы рассмотрим некоторые из них.
Наиболее значимые практические результаты достигнуты в области молекулярной электроники. Она логически близка к традиционной полупроводниковой электронике. Методами молекулярной электроники из углеводородных соединений удается получить аналоги диодов и транзисторов, а следовательно, и основные булевы модули И, ИЛИ и НЕ, из которых затем можно строить схемы любой сложности. Подобный подход позволяет сохранить преемственность архитектурных решений.
В 1999 году сотрудники компании Hewlett-Packard и Калифорнийского университета в Лос-Анджелесе (UCLA) смогли получить действующий молекулярный вентиль. Его толщина составляет всего одну молекулу. Первоначально он умел либо только открываться, либо только закрываться.
Исследователи из Йельского университета смогли продвинуться дальше: их вентиль может принимать любое из двух положений, что позволяет произвольно записывать в него 0 или 1. Обе группы работают над объединением вентилей в регистры.
По мнению аналитиков, предел миниатюризации для традиционной кремниевой электроники наступит через 10-15 лет, а число транзисторов в более сложных устройствах вроде электрических схем неуклонно растет.
Ученые из лаборатории Lucent Technologies Bell Labs сообщили о создании транзистора, который в миллион раз меньше крупицы песка.
Это событие может стать ключевым моментом в создании миниатюрных компьютерных микросхем с малым потреблением энергии. Транзисторы являются "мозгом" компьютеров и любых других электронных устройств. Используя органическую молекулу и химические внутренние процессы, исследователи уменьшили размер транзистора до 1-2 нанометров (миллиардной части метра), чего еще никому не удавалось.
При создании транзисторов использовалась техника "самосборки", когда молекулы фактически сами присоединяются одна к другой с помощью электродов, сделанных из золота. Это позволило уменьшить размер канала до 1-2 нм, причем использованная методика относительно недорога и позволяет увеличить плотность транзисторов на единицу площади. Хотя пока получен только экспериментальный образец, исследователи настроены весьма оптимистично и считают, что вскоре станет возможным строить микропроцессоры и микросхемы памяти из транзисторов размером с молекулу.
Ученые компании Philips разработали нанотранзистор, использующий эффект сверхпроводимости. Новые транзисторы состоят из арсенида индия и алюминиевых сверхпроводящих контактов, а заряд переносится не электронами, а куперовскими парами. Последние представляют собой спаренные электроны с противоположно направленными спинами. Как и в случае с обычными полевыми транзисторами, в новых элементах ток в канале между стоком и истоком регулируется напряжением на затворе. Известно, что эффекта сверхпроводимости можно достичь при очень низких температурах. При какой температуре элементы новых транзисторов проявляют сверхпроводящие свойства, разработчики не сообщают.
Арсенид-индиевые полупроводники размерами от 10 до 100 нм ученые получили с помощью сложного процесса выпаривания. По заявлению Philips, новые транзисторы не только могут стать основой для сверхпроводящих электронных наноцепей нового поколения, но и позволят более основательно изучить явление квантового переноса. Подробно свои исследования ученые собираются представить в одном из выпусков журнала Science.
О крупном достижении, "открытии, представляющем новое мышление в наноэлектронике" сообщили исследователи из двух американских университетов - Калифорнии в
Сан-Диего (UCSD) и Клемсона (Clemson University). Им впервые удалось сделать транзистор полностью из углеродных нанотрубок, разветвленных в форме буквы "Y" (рис. 17.1). Размер нанотранзистора - несколько сотен микрон, что примерно в 100 раз меньше компонентов, используемых в сегодняшних микропроцессорах.

Рис. 17.1. Нанотранзистор на углеродных нанотрубках (Изображение из журнала New Scientist)
В компании Hewlett Packard утверждают, что разработали методику изготовления микросхем, которая позволит продлить действие закона Мура по крайней мере на 50 лет.
По словам ученых, технология теоретически позволит создавать сверхбыстродействующие микросхемы для компьютеров следующего поколения. Другим достоинством методики является относительно низкая себестоимость производства чипов, для изготовления которых предполагается применять систему, напоминающую струйную печать.
Патент на предложенную технологию был получен компанией Hewlett-Packard еще в 2003 году, однако доказать жизнеспособность методики исследователям удалось значительно позже. Планируется, что первые гибридные микросхемы, содержащие и транзисторы, и "нанозащелки", появятся на рынке в первой половине следующего десятилетия. Изготавливаться такие чипы будут, предположительно, по 32-нанометровой технологии. Коммерциализация новой методики намечена на 2020-е гг.
Суть новой технологии состоит в следующем. Вместо транзисторов исследователи НР предлагают использовать так называемые "защелки", состоящие из трех нанопроводников и двух молекулярных переключателей. Два из этих проводников расположены параллельно друг другу и размещены над третьим под прямым углом (рис. 17.2). Молекулярные переключатели служат для соединения нанопроводников друг с другом. Причем переключатели всегда находятся в различных состояниях: один из них открыт, а другой - закрыт, или наоборот. Эти комбинации и соответствуют логическим 0 и 1.

Рис. 17.2. Нанопереключатели для микросхем следующего поколения
Успехи нанотехнологий можно отметить в области хранения данных. Так, фирма IBM создала прототип устройства памяти "многоножка" (Millipede), первое наноустройство хранения данных. Компания ожидает, что эта переломная технология завоюет рынок к 2006 или 2007 году. Новинка состоит из записывающей матрицы манипуляторов, которая включает в себя 4096 кантилеверов, выполненных как устройства чтения-записи (подобные кантилеверы используются сейчас в электронных и атомно-силовых микроскопах).
Правда, у прототипа пока вчетверо меньше кантилеверов, но это не мешает сделать вывод о благоприятных рыночных перспективах продукта.
Теоретически квадратный чип с длиной стороны 2,4 см может хранить до 125 Гб данных, что эквивалентно емкости 25 дисков формата DVD.
Разрабатывается магнитная flash-память на основе углеродных нанотрубок. Ее архитектура довольно проста: каждая ячейка памяти состоит из двух пересекающихся нанотрубок, содержащихся внутри примеси железа или помещенных в ферромагнитное окружение (рис. 17.3). В нанопамяти роль слоев будут играть пересекающиеся нанотрубки, магнитную ориентацию которых можно менять с помощью электрических импульсов различной полярности. А считывать логическое состояние "1" или "0" будут более слабые электрические сигналы определенной полярности. Таким образом, если магнитная ориентация нанотрубок установлена противоположно посылаемому импульсу считывания, то по низкой величине тока импульса будет определяться значение "0". И наоборот - если магнитная ориентация нанотрубок совпадает с направлением электронов в импульсе, то амплитуда тока импульса будет соответствовать логической "1". Полученная память будет энергонезависимой.

Рис. 17.3. Матрица ячеек памяти из нанотрубок
Фирма Motorola продемонстрировала действующий прототип нового цветного дисплея, в котором используется множество микроскопических нитей, называемых углеродными нанотрубками (рис. 17.4). Прототип дисплея имеет размер 4,7 дюйма по диагонали и дает оптическое разрешение в 128х96 пикселей. Он должен стать элементом 42-дюймо-вого телевизионного экрана высокой четкости изображения с разрешением 1280х720 пикселей. В качестве источника электронов используются углеродные нанотрубки.

Рис. 17.4. Принцип действия дисплея NCD
Тенденции развития микропроцессоров
По прогнозам аналитиков, к 2012 году число транзисторов в микропроцессоре достигнет 1 млрд., тактовая частота возрастет до 10 ГГц, а производительность достигнет 100 млрд.оп/с.
Рассмотрим основные направления развитие микропроцессоров.
1. Повышение тактовой частоты.
Для повышения тактовой частоты при выбранных материалах используются: более совершенный технологический процесс с меньшими проектными нормами; увеличение числа слоев металлизации; более совершенная схемотехника меньшей каскадности и с более совершенными транзисторами, а также более плотная компоновка функциональных блоков кристалла.
Так, все производители микропроцессоров перешли на технологию КМОП, хотя Intel, например, использовала БиКМОП для первых представителей семейства Pentium. Известно, что биполярные схемы и КМОП на высоких частотах имеют примерно одинаковые показатели тепловыделения, но КМОП-схемы более технологичны, что и определило их преобладание в микропроцессорах.
Уменьшение размеров транзисторов, сопровождаемое снижением напряжения питания с 5 В до 2,5-3 В и ниже, увеличивает быстродействие и уменьшает выделяемую тепловую энергию. Все производители микропроцессоров перешли с проектных норм 0,35-0,25 мкм на 0,18 мкм и 0,12 мкм и стремятся использовать уникальную 0,07 мкм технологию (табл.17.1).
| Год производства | 2005 | 2006 | 2007 | 2010 | 2013 | 2016 |
| DRAM, нм | 80 | 70 | 65 | 45 | 32 | 32 |
| МП, нм | 80 | 70 | 65 | 45 | 32 | 32 |
| Uпит, В | 0,9 | 0,9 | 0,7 | 0,6 | 0,5 | 0,4 |
| Р, Вт | 170 | 180 | 190 | 218 | 251 | 288 |
При минимальном размере деталей внутренней структуры интегральных схем 0,1-0,2 мкм достигается оптимум, ниже которого все характеристики транзистора быстро ухудшаются. Практически все свойства твердого тела, включая его электропроводность, резко изменяются и "сопротивляются" дальнейшей миниатюризации, возрастание сопротивления связей происходит экспоненциально. Потери даже на кратчайших линиях внутренних соединений такого размера "съедают" до 90% сигнала по уровню и мощности.
При этом начинают проявляться эффекты квантовой связи, в результате чего твердотельное устройство становится системой, действие которой основано на коллективных электронных процессах.
Проектная норма 0,05-0,1 мкм (50-100 нм) - это нижний предел твердотельной микроэлектроники, основанной на классических принципах синтеза схем.
Уменьшение длины межсоединений актуально для повышения тактовой частоты работы, так как существенную долю длительности такта занимает время прохождения сигналов по проводникам внутри кристалла. Например, в Alpha 21264 предприняты специальные меры по кластеризации обработки, призванные локализовать взаимодействующие элементы микропроцессора.
Проблема уменьшения длины межсоединений на кристалле при использовании традиционных технологий решается путем увеличения числа слоев металлизации. Так, Cyrix при сохранении 0,6 мкм КМОП технологии за счет увеличения с 3 до 5 слоев металлизации сократила размер кристалла на 40% и уменьшила выделяемую мощность, исключив существовавший ранее перегрев кристаллов.
Одним из шагов в направлении уменьшения числа слоев металлизации и уменьшения длины межсоединений стала технология, использующая медные проводники для межсоединений внутри кристалла, разработанная фирмой IBM и используемая в настоящее время и другими фирмами-изготовителями СБИС.
Впервые рубеж тактовой частоты в 500 МГц перешагнули микропроцессоры фирмы DEC, которая уже в конце 1996 г. поставляла Alpha 21164 с тактовой частотой 500 МГц, в 1997 г. - Alpha 21264 с тактовой частотой 600 МГц, а в 1998 г. - Alpha 21264 с тактовой частотой 750 МГц и выше. В настоящее время ряд фирм выпускает процессоры для персональных компьютеров с тактовой частотой свыше 4 ГГц.
2. Увеличение объема и пропускной способности подсистемы памяти.
Возможные решения по увеличению пропускной способности подсистемы памяти включают создание кэш-памяти одного или нескольких уровней, а также увеличение пропускной способности интерфейсов между процессором и кэш-памятью и конфликтующей с этим увеличением пропускной способности между процессором и основной памятью. Совершенствование интерфейсов реализуется как увеличением пропускной способности шин (путем увеличения частоты работы шины и/или ее ширины), так и введением дополнительных шин, расшивающих конфликты между процессором, кэш-памятью и основной памятью.
В последнем случае одна шина работает на частоте процессора с кэш-памятью, а вторая - на частоте работы основной памяти. При этом частоты работы второй шины, например, равны 66, 66, 166 МГц для микропроцессоров Pentium Pro-200, Power PC 604E-225, Alpha 21164-500, работающих на тактовых частотах 300, 225, 500 МГц, соответственно. При ширине шин 64, 64, 128 разрядов это обеспечивает пропускную способность интерфейса с основной памятью 512, 512, 2560 Мбайт/с, соответственно.
Общая тенденция увеличения размеров кэш-памяти реализуется по-разному:
внешние кэш-памяти данных и команд с двухтактовым временем доступа объемом от 256 Кбайт до 2 Мбайт со временем доступа 2 такта в HP PA-8000;отдельный кристалл кэш-памяти второго уровня, размещенный в одном корпусе в Pentium Pro;размещение отдельных кэш-памяти команд и кэш-памяти данных первого уровня объемом по 8 Кбайт и общей для команд и данных кэш-памяти второго уровня объемом 96 Кбайт в Alpha 21164.
Наиболее используемое решение состоит в размещении на кристалле отдельных кэш-памятей первого уровня для данных и команд с возможным созданием внекристальной кэш-памяти второго уровня. Например, в Pentium II использованы внутрикристальные кэш-памяти первого уровня для команд и данных по 16 Кбайт каждая, работающие на тактовой частоте процессора, и внекристальный кэш второго уровня, работающий на половинной тактовой частоте.
3. Увеличение количества параллельно работающих исполнительных устройств.
Каждое семейство микропроцессоров демонстрирует в следующем поколении увеличение числа функциональных исполнительных устройств и улучшение их характеристик, как временных (сокращение числа ступеней конвейера и уменьшение длительности каждой ступени), так и функциональных (введение ММХ-расширений системы команд и т.д.).
В настоящее время процессоры могут выполнять до 6 операций за такт. Однако число операций с плавающей точкой в такте ограничено двумя для R10000 и Alpha 21164, а 4 операции за такт делает HP PA-8500.
Для того чтобы загрузить функциональные исполнительные устройства, используются переименование регистров и предсказание переходов, устраняющие зависимости между командами по данным и управлению, буферы динамической переадресации.
Широко используются архитектуры с длинным командным словом - VLIW. Так, архитектура IA-64, развиваемая Intel и HP, использует объединение нескольких инструкций в одной команде (EPIC). Это позволяет упростить процессор и ускорить выполнение команд. Процессоры с архитектурой IA-64 могут адресоваться к 4 Гбайтам памяти и работать с 64-разрядными данными. Архитектура IA-64 используется в микропроцессоре Merced, обеспечивая производительность до 6 Гфлоп при операциях с одинарной точностью и до 3 Гфлоп - с повышенной точностью на частоте 1ГГц.
4. Системы на одном кристалле и новые технологии.
В настоящее время получили широкое развитие системы, выполненные на одном кристалле - SOC (System On Chip). Сфера применения SOC - от игровых приставок до телекоммуникаций. Такие кристаллы требуют применения новейших технологий.
Основной технологический прорыв в области SOC удалось сделать корпорации IBM, которая в 1999 году смогла реализовать сравнительно недорогой процесс объединения на одном кристалле логической части микропроцессора и оперативной памяти. В новой технологии, в частности, используется так называемая конструкция памяти с врезанными ячейками (trench cell). В этом случае конденсатор, хранящий заряд, помещается в некое углубление в кремниевом кристалле. Это позволяет разместить на нем свыше 24 тыс. элементов, что почти в 8 раз больше, чем на обычном микропроцессоре, и в 2-4 раза больше, чем в микросхемах памяти для ПК. Следует отметить, что хотя кристаллы, объединяющие логические схемы и память на одном кристалле, выпускались и ранее, например, такими фирмами, как Toshiba, Siemens AG и Mitsubishi, подход, предложенный IBM, выгодно отличается по стоимости. Причем ее снижение никоим образом не сказывается на производительности.
Использование новой технологии открывает широкую перспективу для создания более мощных и миниатюрных микропроцессоров и помогает создавать компактные, быстродействующие и недорогие электронные устройства: маршрутизаторы, компьютеры, контроллеры жестких дисков, сотовые телефоны, игровые и Интернет-приставки.
Для создания SOC IBM использует самые современные технологические решения, одним из которых являются медные межсоединения (copper interconnect). Первым микропроцессором IBM с медными межсоединениями в 1998 г. стал PowerPC 750. По сравнению с технологией, где межсоединения выполнены на основе алюминия, медь позволяет сделать кристалл меньшим по размеру и более быстродействующим. Медная металлизация уменьшает общее сопротивление, что позволяет увеличить скорость работы кристалла на 15-20%. Обычно эта технология дополняется еще одной новинкой: технологией кремний на изоляторе - КНИ (SOI, Silicon On Insulator). Она уменьшает паразитные емкости, возникающие между элементами микросхемы и подложкой. Благодаря этому тактовую частоту работы транзисторов также можно увеличить. Возрастание скорости от использования КНИ приближается к 20-30%. Таким образом, общий рост производительности в идеальном случае может достигнуть 50%.
За счет каких факторов достигают
Сформулируйте основные тенденции развития микропроцессоров. За счет каких факторов достигают повышения тактовой частоты МП?Какие архитектурные особенности приводят к улучшению характеристик МП?Что такое нанотехнологии? В каких направлениях они развиваются?Приведите примеры использования нанотехнологий.Что такое фотоника? Расскажите о ее достижениях.