Алгоритмическое (модульное) программирование
Алгоритм — это формальное описание способа решения задачи путем разбиения ее на конечную по времени последовательность действий (элементарных операций). Под словом «формальное» подразумевается, что описание должно быть абсолютно полным и учитывать все возможные ситуации, которые могут встретиться по ходу решения. Под элементарной операцией понимается действие, которое по заранее определенным критериям (например, очевидности) не имеет смысла детализировать.
Основная идея алгоритмического программирования — разбиение программы на последовательность модулей, каждый из которых выполняет одно или несколько действий. Единственное требование к модулю — чтобы его выполнение всегда начиналось с первой команды и всегда заканчивалось на самой последней (то есть, чтобы нельзя было попасть на команды модуля извне и передать управление из модуля на другие команды в обход заключительной).
Алгоритм на выбранном языке программирования записывается с помощью команд описания данных, вычисления значений и управления последовательностью выполнения программы.
Переменные и константы
Реальные данные, с которыми работает программа, — это числа, строки и логические величины (аналоги 1 и 0, «да» и «нет», «истина» и «ложь»). Эти типы данных называют базовыми.
Каждая единица информации хранится в ячейках памяти компьютера, имеющих свои адреса. На практике заранее неизвестно, в каких конкретно ячейках памяти во время работы программы будут записаны ее данные, поэтому в языках программирования введено понятие переменной, позволяющее отвлечься от конкретных адресов и обращаться к содержимому памяти с помощью идентификатора или имени — как правило, последовательности, содержащей английские буквы, цифры, символы подчеркивания и начинающейся не с цифры. Например:
Hello
_SumOfReal
xl
H8_G7_F6
Это имя будет указывать на значение, о реальном адресе и способе хранения которого можно забыть. В процессе работы программы содержимое соответствующих ячеек можно менять, обращаясь к переменной по имени.
Лучше выбирать такие названия, которые отражают назначение данной переменной.
Кроме имени и значения, переменная обычно имеет тип, определяющий, какая информация хранится в данной переменной (число, строка и т. д.). В зависимости от объема памяти, отведенного для хранения значения переменной, оно должно укладываться в допустимый диапазон. Например, значение типа «байт» имеет диапазон от 0 до 255.
Переменные с указанием их типа можно вводить в программу с помощью специальных команд описания {объявления, декларации). Это позволяет компилятору организовать эффективное хранение и обработку данных и повышает ясность исходных тестов. Каждый тип описывается своим ключевым словом.
Значения переменных разных типов допускается преобразовывать друг в друга в соответствии с соглашениями языка программирования. Такой процесс называется приведением типов.
Переменные могут существовать на всем протяжении работы программы — тогда они называются статическими, а могут создаваться и уничтожаться на разных этапах ее функционирования — такие переменные называются динамическими.
Все остальные данные в программе, значение которых не меняется на протяжении ее работы, называются константами или постоянными. Константы, как и переменные, обычно имеют тип. Данные можно указывать явно:
123
2.87
"это строка"
или для удобства обозначать их идентификаторами. Например, число я, равное 3,1416, можно обозначить как pi и везде вместо числа применять идентификатор. Только изменять значение pi нельзя, так как это не переменная, а константа.
Числовые данные
Числа обычно бывают двух видов: целые и дробные. Если число отрицательное, перед ним ставится знак «-», если положительное, то знак «+» можно ставить, а можно и опускать. Вычисления над целыми числами выполняются точно, вычисления над дробными числами — приближенно. При записи дробных чисел в качестве десятичного разделителя используется точка:
1.28
3.333321
Очень большие или очень маленькие числа записываются специальным образом.
Для них дополнительно указывается мантисса — число со знаком, являющееся степенью числа 10. Мантисса записывается справа от числа через букву е (или Е). Пробелы в такой записи не допускаются.
Например, число 100 (единица, умноженная на 10 во второй степени) запишется так:
1е+2
число 0,003 (тройка, умноженная на 10 в минус третьей степени) так:
Зе-3
число со 120 нулями — так:
1Е+120
Допускается дробная запись числа с мантиссой:
31.4е-1
|
Тип числа |
Бейсик |
Паскаль |
Си++ |
|
целое |
INTEGER |
integer |
int |
|
дробное |
DOUBLE |
real |
float |
Арифметические операции
Для записи арифметических действий используются арифметические операторы. В некоторых языках программирования они считаются не операторами, а операциями, предназначенными для вычисления значения выражения, но не влияющими на другие значения и не сказывающимися на ходе выполнения программы.
К основным арифметическим операциям относятся:
+ (сложение)
- (вычитание)
* (умножение)
/ (деление)
Такая форма записи отвечает общепринятым соглашениям и принята в большинстве языков программирования.
Каждая арифметическая операция имеет свой приоритет. Операции с более высоким приоритетом (умножение и деление) будут выполняться раньше, чем операции с более низким приоритетом (сложение и вычитание). Изменить порядок вычисления выражения можно с помощью круглых скобок.
b*2 + с/3
b* (2 + с) - 3
Скобки допускается вкладывать друг в друга произвольное число раз. При этом использование квадратных или фигурных скобок, как правило, не допускается.
( (у+2)*3 + 1) / 2
Арифметические выражения
С помощью арифметических операций формируются арифметические выражения, которые состоят из операций и операндов (переменных и констант).
Выражение
i1 + 2
состоит из одной операции «+» и двух операндов — переменной И и числовой константы 2.
Каждое выражение имеет значение, которое определяется в момент выполнения оператора, содержащего это выражение. Если на момент вычисления выражения i1+2 в переменной i1 хранится число 3, то значение этого выражения будет равно 5 (3+2).
Логические выражения
При создании программ не обойтись без логических выражений. Они отличаются тем, что результат их вычислений может принимать только одно из двух допустимых значений — true (истина, да, включено) и false (ложь, нет, выключено). Чаще всего значение false ассоциируется с нулем, а значение true — с числом 1 или просто ненулевым значением.
При записи логических выражений используются операции сравнения и логические операции. Операции сравнения сличают значения правого и левого операндов. Результатом сравнения является true, если оно удачно, и false в противном случае.
В таблице даны примеры записи операций сравнения для разных языков.
|
Операция |
Варианты написания |
|
|
Бейсик, Паскаль |
Си++ |
|
|
Равно |
= |
== |
|
Не равно |
<> |
!= |
|
Меньше |
< |
< |
|
Меньше или равно |
<= |
<= |
|
Больше |
> |
> |
|
Больше или равно |
>= |
>= |
х > 0 al <> b1
В одном выражении может потребоваться проверка нескольких подобных условий. Например, надо определить, больше ли значение переменной X чем 0 и меньше ли чем 10. Условия могут быть связаны с помощью логических операций, наиболее активно используемые из которых — это И и ИЛИ. В компьютерной графике также часто применяется так называемое исключающее ИЛИ и операция отрицания НЕ. Для нее требуется только один операнд, указывающийся справа от знака операции. Эта операция просто меняет значение своего операнда на противоположное.
|
1 операнд |
2 операнд |
И |
ИЛИ |
исключающее ИЛИ |
HE (только первый операнд) |
|
true |
true |
true |
true |
false |
false |
|
true |
false |
false |
true |
true |
false |
|
false |
true |
false |
true |
true |
true |
|
false |
false |
false |
false |
false |
true |
|
Логическая операция |
Бейсик |
Паскаль |
Си++ |
|
И |
AND |
and |
&& |
|
ИЛИ |
OR |
or |
II |
|
НЕ |
NOT |
not |
! |
Приоритеты всех логических операций ниже, чем приоритеты операций сравнения, поэтому сравнения всегда выполняются первыми. А логические операции вычисляются в следующем порядке: сначала НЕ, потом И, потом ИЛИ. При необходимости этот порядок может быть изменен с помощью скобок.
Примеры логических выражений:
x1 >= 1 && x1 <= 10
(R > 3.14) and (R < 3.149)
(Value < Oldvalue) OR (Value <> 0)
Логический тип
|
Бейсик |
Паскаль |
Си++ |
|
Базового типа нет. Используется числовой тип INTEGER |
boolean |
bool |
Строчные выражения
Строки в языках программирования всегда заключаются в кавычки. В Си++ и Бейсике для этого используются двойные кавычки, в Паскале — одинарные.
"это строка Бейсика или Си++"
'это строка Паскаля'
Строка может быть пустой — не содержать ни одного символа. Например:
Как правило, строки можно сравнивать друг с другом на эквивалентность (равно и не равно). В некоторых языках программирования допускаются также сравнения типа «больше» или «меньше» — при этом происходит последовательное сравнение значений символов (каждый символ представляется в компьютере конкретным числом).
Кроме того, часто допускается также операция сцепления строк, записываемая с помощью символа «+». Например:
"123" + "4567" -получится "1234567"
"абв " + "abc " + " эюя" —получится "абв abc эюя"
Тип «строка»
|
Бейсик |
Паскаль |
Си++ |
|
STRING |
string |
Базового типа «строка» нет |
Указатели
Некоторые языки программирования допускают в явном виде работу с указателями — адресами физической памяти. При этом в них имеется специальная операция получения адреса конкретной переменной, что позволяет работать с памятью напрямую, примерно так, как это происходит в языках ассемблера. Такая возможность позволяет добиваться высокой эффективности работы программы, но часто приводит к ошибкам, если указатель вдруг получает неверное значение и при его использовании начинает портиться область памяти, предназначенная совсем для других целей.
Сложные данные
Структуры. До сих пор рассматривались базовые типы данных: числа, строки, логические величины — и операции над базовыми данными. Однако для повышения производительности труда программистов и повышения качества их работы необходимо, чтобы язык программирования имел средства, позволяющие описывать данные в виде, максимально приближенном к их реальным аналогам. Например, чтобы организовать обработку данных по студентам, в программе удобно не просто описать десяток различных переменных, а объединить их в структуру (или запись) «студент», состоящую из полей разного типа «имя», «пол», «год рождения», «группа» и т. д.
Современные языки программирования позволяют применять такие сложные типы данных, составляющиеся из базовых и определенных ранее сложных типов. В результате удается организовывать структуры данных произвольной сложности: списки, деревья и т. п. При этом структура объединяет группу разных данных под одним названием.
Получить доступ к отдельным составляющим (полям) этой структуры можно по их именам. В рассматриваемых языках программирования такой доступ осуществляется указанием имени структуры и имени поля через точку. Если подобным способом происходит обращение к полю, которое само является структурой, то выделение нужного поля продолжается приписыванием справа имени вложенного поля через точку.
Синтаксис описания структуры
|
Бейсик |
Паскаль |
Си++ |
|
TYPE имя-структуры поле AS тип END TYPE |
record поле: тип; end; |
struct имя { тип поле; }; |
Бейсик:
TYPE Student
Name AS STRING
Sex AS INTEGER
BirthYear AS INTEGER
END TYPE
Паскаль:
record
Name: string;
Sex: boolean;
BirthYear: integer;
end;
Си++:
struct Student {
bool Sex; int BirthYear; };
Доступ к содержимому структуры: Student.BirthYear = 1980;
Массивы. Доступ к элементам структуры осуществляется по имени ее составляющих. В одних случаях это значительно повышает наглядность исходных текстов и упрощает процесс программирования, но имеется немало ситуаций, когда надо организовать обработку больших объемов данных одного типа, при этом создавать структуры с сотнями и тысячами полей неразумно.
Поэтому в дополнение к структурам в языки программирования введено понятие массива, сложного типа данных, доступ к элементам которого происходит по их положению, по номеру или индексу. Например, можно описать массив, состоящий из тысячи элементов численного типа, и затем обратиться к десятому или сотому элементу по его номеру.
При описании массива обычно указывается ею размер (число элементов) или верхняя и нижняя границы — диапазон, в рамках которого можно обращаться к элементам массива.
Синтаксис описания массива
|
Бейсик |
DIM имя (число элементов) AS тип |
|
Паскаль |
аггау[ нижняя_граница .. верхняя_граница ] of тип; |
|
Си++ |
тип имя[ число-элементов ]; |
Вот примеры описания массивов.
Бейсик:
DIM IntArray(lOOO) AS INTEGER
Паскаль:
array[1..1000] of integer
Си++:
int IntArray[1000];
Доступ к элементу массива осуществляется по его номеру. Этот номер указывается в круглых (Бейсик) или квадратных (Паскаль, Си++) скобках сразу за именем массива (такое действие называется индексированием):
IntArray( 12 ) IntArray[ i+1 ]
Массивы, границы которых явно заданы в команде описания, называются статическими. Их размер известен заранее и не меняется на всем протяжении работы программы.
В последних версиях компилируемых языков программирования реализуются так называемые динамические массивы, размер которых может меняться во время выполнения программы. В ряде случаев это весьма удобно, так как позволяет экономно расходовать память, захватывая ее по мере необходимости. Недостаток динамических массивов в том, что организовать эффективную работу с ними, используя компиляторы, сложно. Приходится выполнять множество проверок, связанных с расходованием памяти компьютера, что понижает общую эффективность приложения. Динамические массивы в Паскале начали поддерживаться совсем недавно, с активным распространением новых мощных ПК, а в интерпретируемых языках типа Бейсика это было сделано довольно давно.
Во многих языках программирования строки рассматриваются как массивы символов. Их допускается индексировать как обычные массивы.
Правила работы со сложными типами
Отличие базовых типов от сложных в том, что в базовых типах нельзя выделить составные части. При этом поле структуры или элемент массива считаются обычными переменными, и их использование в любых операторах ничем не отличается от использования переменных базовых типов.
В развитых языках программирования допускаются массивы, состоящие из структур, и структуры, состоящие из массивов. При этом возможны достаточно сложные формы записи, например:
а[0].Items.Strings[4].value
Массив а состоит из структур, в описании которых есть поле Items, являющееся тоже структурой, имеющей поле Strings, которое, в свою очередь, представляет собой массив структур, имеющих поле value.
Описание переменных
Чтобы переменную можно было использовать в программе, ее надо предварительно описать, указав ее тип. Пока переменная не описана, обращаться к ней нельзя (хотя в некоторых языках, например в Бейсике и Фортране, считается, что все переменные, не объявленные явно, имеют числовой тип). После того как переменная описана, к ней можно обращаться, но она обычно исходно имеет неопределенное значение, поэтому ее надо предварительно инициализировать — присвоить ей начальное значение.
Синтаксис команд описания данных
|
Бейсик |
Паскаль |
Си++ |
|
DIM имя AS тип |
var имя: тип; |
тип имя; |
Бейсик:
DIM X AS DOUBLE
Паскаль:
var x: real; var Str: record
PI: integer;
S: string;
end;
Си++:
float x; int a[20] ;
При описании переменных одного типа в Паскале и Си++ их можно указывать через запятую.
Паскаль:
var xx, z2: integer; Си++:
int xx, yy[10], z2;
Новые типы данных
При определении нескольких переменных со сложной структурой удобно описывать каждую переменную, многократно используя одну и ту же запись структуры.
Если, например, в нее потребуется внести изменение (добавить новое поле, изменить тип существующего и т. д.), то придется делать это несколько раз, рискуя ошибиться и пропустить одно из описаний, особенно если они сделаны в разных местах программы.
Чтобы избежать этой проблемы и позволить программистам активно применять нужные структуры данных, в современных языках программирования разрешено определять собственные типы данных, которые допускается использовать в командах описания наравне с базовыми типами.
Синтаксис описания нового типа
|
Бейсик |
Паскаль |
Си++ |
|
Аналогичен описанию структуры, которое уже является описанием нового типа |
type имя = описание; |
typedef struct имя-структуры { поля-структуры; } имя; Имя структуры надо указывать только из-за требований синтаксиса. Реально оно нигде не применяется |
Паскаль:
type TMyArray = array[0..99] of integer;
type TMyRecord = record
Iteml: integer;
Item2: string;
end;
var MyArray: TMyArray;
var R: TMyRecord;
Си++:
typedef struct namel
{
int i;
float x;
} TNewStruct;
TNewStruct NewStruct
Разделение операторов
Если записать подряд несколько операторов и не указать, где кончается один и начинается другой, то в процессе компиляции возникнет множество проблем с выделением отдельных операторов. Поэтому операторы в Паскале и Си++ отделяются друг от друга точкой с запятой «;» (каждый оператор в этих языках должен заканчиваться таким символом), а в Бейсике — двоеточием «> или переходом на новую строку.
Блок операторов
Часто в программе возникает необходимость выполнить группу операторов (например, в зависимости от какого-либо условия). Такая группа объединяется в блок с помощью специальных скобок начала и конца блока, называемых логическими скобками.
В Бейсике явного понятия «блок операторов» нет, в Паскале для этого используются ключевые слова begin и end, а в Си++ — фигурные скобки «{» и «}».
Эта проблема становится особенно актуальной, когда группой специалистов разрабатывается объемное приложение, и разобраться в сотнях тысяч строк своего и чужого исходного текста очень сложно.
Языки программирования допускают использование комментариев — частей исходных текстов, выделяемых с помощью специальных обозначений и пропускаемых компилятором при анализе текста программы. Комментарии могут начинаться и заканчиваться особыми символами и охватывать несколько строк кода, а могут записываться только в конце строки — при этом считается, что весь остаток строки является комментарием.
Для обозначения комментариев в одном и том же языке программирования могут использоваться разные символы, поэтому возможно возникновение вложенных комментариев. Допустимость такого вложения задается, как правило, в настройках компилятора.
Синтаксис комментария
|
Бейсик |
Паскаль |
Си++ |
|
|
Однострочный комментарий |
REM или ' |
II |
// |
|
Многострочный комментарий |
нет |
{ } или (* *) |
/**/ |
X : = 5; // комментарий до конца строки
/*
это комментарий
языка Си++
*/
{
это комментарий
языка Паскаль
(* а это вложенный комментарий *)
}
Условный оператор (условные вычисления)
С помощью одного оператора присваивания можно создавать достаточно сложные расчетные программы, однако реализовать абсолютное большинство алгоритмов, просто последовательно выполняя операторы присваивания, невозможно. Постоянно приходится изменять порядок выполнения последовательности вычислений в зависимости от определенных деловым. Эти условия записываются в виде логических выражений и всегда принимают одно из двух значений — true или false (истинно или ложно). При этом происходит разветвление программы — выполнение в дальнейшем может продолжиться с разных операторов.
Синтаксис условного оператора примерно одинаков во всех языках программирования — он представляет собой конструкцию:
если условие истинно
то выполнить оператор-1
иначе выполнить оператор-2
После ключевого слова IF (если) следует условие, и если оно истинно, то выполняется оператор или блок операторов, следующих за ключевым словом THEN (mo), если же оно ложно, то выполняется оператор или блок операторов, следующих за ключевым словом ELSE (иначе).
Синтаксис условного оператора
|
Бейсик |
Паскаль |
Си++ |
|
IF условие THEN оператор- 1 ELSE оператор-2 END IF |
if условие then оператор- 1 else оператор-2; |
if( условие ) оператор- 1 else оператор-2; |
Примеры.
Бейсик:
IF А < > THEN
А = О
ELSE
А = -1
END IF
Паскаль:
if а <> 0 then a := О
else a := -1;
Си++:
if( а <> 0 ) а = 0
else a = -1;
Вторую часть условного оператора, выполняющуюся в случае, если условие ложно, всегда можно опускать.
Бейсик:
IF x < О THEN
у = х / 2
х = 1
END IF
Паскаль:
if х < 0 then
begin
у := х / 2;
х := 1;
end
Си++:
if( х < 0 )
{
у = х / 2;
х = 1;
};
Повторяющиеся вычисления (операторы цикла)
С помощью условных операторов и операторов присваивания теоретически можно реализовать сколь угодно сложный алгоритм. Однако на практике при необходимости организовать обработку тысяч элементов массива (например, присвоить каждому элементу начальное значение) вручную набирать тысячу операторов присваивания крайне тяжело.
Поэтому в языках программирования имеются средства для организации повторных вычислений, называемые операторами цикла. Они бывают двух видов: с фиксированным числом повторений и условные операторы цикла.
Каждый оператор цикла состоит из заголовка цикла, определяющего число повторений, и тела цикла — повторяемого оператора или блока операторов.
Первый вид оператора цикла
При решении задачи примерно в половине случаев заранее известно, сколько раз понадобится выполнить тело цикла. Так бывает, как правило, при обработке массивов, размер которых всегда или известен заранее, или легко определяется.
Заголовок такого оператора состоит из трех частей — инициализации переменной-счетчика или параметра цикла (присваивания ей начального значения), определения конечного значения счетчика, по достижении которого тело цикла надо выполнить в последний раз, и приращения счетчика, определяющего, на сколько будет меняться значение счетчика после каждого выполнения тела цикла.
Синтаксис оператора цикла
|
Бейсик |
FOR счетчик = начальное_значение ТО конечное_значение STEP приращение тело цикла группа операторов NEXT Если приращение не указывать, то считается, что оно равно 1 |
|
Паскаль |
for счетчик := начальное_значение to конечное_значение do оператор или блок операторов; Приращение всегда равно 1 |
|
Си++ |
for( счетчик = начальное_значение; условие_завершения; счетчик = счетчик + приращение) оператор или блок операторов; |
Бейсик:
FOR I = 1 ТО 1000
А(1) = О
NEXT
Паскаль:
for i := 1 to 1000 do
a[i] := 0;
Си++:
for( i = 0; i < 1000; i = i + 1 )
a[i] = 0;
В последнем примере счетчик будет принимать значения от 0 до 999, потому что нумерация элементов массива в Си++ начинается с нуля.
Второй вид оператора цикла
Не менее часто встречаются ситуации, когда число повторений заранее неизвестно — надо выполнять цикл, пока не произойдет некоторое событие (пользователь нажмет на кнопку, точность вычислений уложится в заданный порог и т. д.). В таких ситуациях заголовок цикла упрощается. В нем указывается только условие (логическое выражение) — пока его значение равно true, цикл будет выполняться.
Синтаксис оператора цикла
|
Бейсик |
Паскаль |
Си++ |
|
DO WHILE условие группа операторов LOOP |
while условие do оператор или группа операторов; |
while( условие ) оператор или группа операторов; |
DO WHILE A > В
А = А - 0.01
LOOP
Паскаль:
while a > b do
а := а - 0.01;
Си++:
while( а > b )
а = а - 0.01;
Зацикливание
При использовании условных операторов цикла программиста подстерегает одна опасность. Как показывает практика, достаточно легко сделать ошибку и неверно задать условие окончания цикла, которое всегда будет истинным, — при этом тело цикла станет выполняться бесконечно. Подобная ситуация называется зацикливанием.
Например:
а = 0; b = 1;
while(а < b )
a = a - 0.01;
Так как исходное значение переменной а меньше, чем значение переменной b, и это значение будет только уменьшаться, то подобный цикл никогда не закончится.
В некоторых случаях программисты специально применяют подобный трюк, чтобы организовать бесконечный цикл, в котором будут приниматься и обрабатываться внешние сообщения (события). Тогда использование условного оператора цикла может выглядеть так:
while true do
begin // тело цикла
end;
Контроль за выходом из цикла при наступлении определенного события при этом полностью возлагается на программиста.
В Бейсике есть специальная форма оператора цикла, позволяющая явно описывать такие бесконечные циклы:
DO
' тело цикла
LOOP
Исключения
Управление порядком выполнения программы может происходить не только с помощью условных операторов и операторов цикла, но и при возникновении исключений — ситуаций в программе или операционной системе, требующих немедленного реагирования. Например, при выполнении оператора присваивания и вычислении выражения произошло деление на ноль. Программа остановилась, так как не знает, что ей делать дальше, — ведь получено ошибочное значение. Чаще всего выполнение программы просто прекращается по ошибке, но современные системы разработки позволяют программисту явно контролировать возникновение самых разных исключений (они еще называются исключительными ситуациями, требующими немедленного вмешательства) и указывать, какие операторы следует выполнять при их возникновении.
Параллельные вычисления
Еще одна область программирования, в которой возможно изменение явно указанного порядка выполнения операторов, — это область параллельных вычислений.
С появлением недорогих ПК с несколькими процессорами возникла возможность распараллеливания программы — одновременного выполнения ее независимых частей на разных процессорах, что теоретически позволяет получить выигрыш в быстродействии, линейно зависящий от числа процессоров. Однако на практике это очень сложная задача, которая требует правильного выделения независимых модулей кода (так называемых процессов), выполнение которых не скажется на результатах работы других процессов. Так как момент окончания работы того или иного процесса заранее неизвестен, то в программе надо предусмотреть действия, связанные с синхронизацией обработки получаемых результатов. Их выполнение может потребоваться в самые неожиданные моменты, поэтому изменение линейной последовательности работы операторов неизбежно.
Ввод и вывод
Чтобы получать от человека информацию для обработки и показывать результаты своей работы, программа должна иметь средства для организации интерактивного общения с пользователем (общения в реальном масштабе времени — человек щелкнул мышкой на кнопке и сразу получил ответ) и средства для ввода данных из файлов и сохранения данных в файлах. Интерактивное общение реализуется с помощью /МО-систем, позволяющих быстро спроектировать пользовательский интерфейс. Ввод и вывод информации осуществляется в разных языках по-разному. В Паскале и Бейсике есть операторы для такой работы, в Си++ они выделены в специальные библиотеки. Введен также специальный тип данных «файл» (FILE).
Работа с файлами всегда происходит в три этапа.
1. Файл открывается в одном из выбранных режимов (он рассматривается как последовательность строк или двоичных чисел, разрешается только считывать из него данные или только записывать и т. д.). Файл может состоять из последовательности одинаковых блоков, каждый из которых будет представлять собой копию структуры данных определенного типа, описанного в программе. Каждый такой блок называется записью.
2. Выполняется считывание, обновление или удаление записей в файле.
3. Файл закрывается. Если этого не сделать, то он останется открытым, и в дальнейшем к нему нельзя будет обратиться из других программ.
Каждый из этих пунктов реализуется в каждом из языков программирования по-своему. Некоторые пункты требуют для своей реализации нескольких операторов.
Вопросы для самоконтроля
1. Какие типы данных считаются базовыми?
2. Приведите примеры арифметических и логических выражений.
3. Напишите формулу для вычисления среднего арифметического и среднего геометрического значений двух переменных.
4. В чем различие структуры и массива?
5. Зачем нужны комментарии?
6. С помощью условных операторов выполните проверку неравенства х < у < z.
7. Из каких частей состоит оператор цикла?
8. Назовите достоинства и недостатки параллельных вычислений.
9. Как организуется работа с файлами?
Автоматизированный перевод документов
К средствам автоматизации перевода можно отнести два вида программ: электронные словари и программы перевода. Электронные словари представляют собой средства для перевода отдельных слов, отображаемых на экране или имеющихся в документе. Удобство их использования состоит в возможности немедленно получить перевод неизвестного слова без поиска его в отдельном толстом томе. Программы перевода получают на входе текст, выполненный на одном языке, и выдают текст на другом языке, то есть автоматизируют перевод текста.
Электронные словари удобны для профессиональных переводчиков, которые выполняют большую часть работы по переводу вручную. Их также могут использовать лица, в целом знающие иностранный язык, если надо не обеспечить перевод документа, а просто ознакомиться с его содержанием.
Надежный и качественный автоматический перевод документов с одного языка на другой (мы будем говорить в основном о переводе с английского на русский) пока остается недостижимым идеалом. Причин для этого множество, и главная из них состоит в том, что перевод текста не сводится к переводу отдельных лексических единиц. Преодолеть этот барьер современные программы автоматического перевода пока не могут.
Тем не менее, современные средства автоматизации перевода достигли того уровня, который позволяет эффективно использовать их на практике. Дело в том, что технический текст, в отличие от художественного, использует ограниченное число языковых конструкций и более ориентирован на однозначную интерпретацию. Среди используемых лексических единиц встречается большое число технических терминов, имеющих совершенно определенный смысл в рамках данной научной или технической дисциплины. Это значительно упрощает процесс перевода и позволяет в отдельных случаях автоматически получать текст, близкий к результату ручного подстрочного перевода.
Программы автоматического перевода имеет смысл использовать для перевода технических текстов в следующих случаях:
• при абсолютном незнании иностранного языка;
• при необходимости получить перевод быстро, даже ценой снижения его качества (например, это относится к переводу Web-документов);
• для перевода на иностранный язык (умения читать иноязычные тексты недоста точно, чтобы научиться объясняться на иностранном языке);
• для быстрого создания первоначального черновика («подстрочника»), используемого в ходе подготовки полноценного перевода.
Работа с программой Promt 98
Для автоматизированного перевода технических текстов можно, например, использовать программу Promt 98. Она позволяет переводить документы с английского языка на русский и с русского на английский. Чтобы обеспечить правильный перевод терминов, относящихся к определенной научной дисциплине, используют специализированные словари, в которых для слов, используемых как термины, предлагается в качестве перевода не «обиходное», а специальное значение.
Если программа Promt 98 установлена на компьютере, для ее запуска можно использовать Главное меню (Пуск > Программы > Главное меню > PROMT 98 > PROMT 98), значок PROMT 98 на Рабочем столе или значок программы на панели индикации (команда PROMT 98 в контекстном меню этого значка).
Одновременно для обработки может быть открыто несколько документов. Окна документов имеют необычный вид (рис. 17.4). Они разбиваются на три отдельные области: две из них предназначены для отображения оригинала текста и сформированного перевода, а третья представляет собой информационную панель, предназначенную для вывода информации о переводимом документе и специальных настройках.

Рис. 17.4. Рабочее окно системы автоматизированного перевода Promt 98
Чтобы произвести перевод имеющегося документа с использованием заданных по умолчанию настроек, применяют следующий порядок действий.
1. Сначала необходимо открыть документ на языке оригинала (кнопка Открыть на панели инструментов Основная). Нужный документ выбирают в диалоговом окне Выберите документ. Формат открываемого файла выбирают в раскрывающемся списке Тип файлов.
2. После выбора файла появляется диалоговое окно Конвертировать файл. В нем можно уточнить реальный формат документа, хранящегося в файле, если он не соответствует типу файла или когда тип файла может соответствовать нескольким разным форматам документа.
3. Документ загружается и отображается в области исходного текста. При вертикальном разбиении окна документа эта область располагается слева. Если
предполагается длительная работа над переводом текста, его сохраняют как
документ программы Promt 98 (файл с расширением .STD).
4. Определение языков оригинала и перевода рассматривается как направление перевода. Чтобы выбрать направление перевода, используют кнопку Изменить направление на панели инструментов Перевод.
5. Чтобы перевести весь текст целиком, используют кнопку Весь текст на панели инструментов Перевод. В ходе выполнения перевода на экране отображается диалоговое окно Перевод текста с индикатором хода работы. Перевод текста помещается (при вертикальном разбиении окна) в правую область. Для удобства последующего редактирования перевод снабжается цветовой разметкой: неизвестные программе слова выделяются красным цветом, а зарезервированные слова, которые не надо переводить, — зеленым.
Текст, помещенный в областях окна программы Promt 98, можно редактировать (и оригинал, и перевод). Чтобы заново перевести отредактированный абзац, используют кнопку Текущий абзац на панели инструментов Перевод. Текущий абзац — это абзац, в котором располагается текстовый курсор. Он выделяется голубой полосой вдоль левого края.
6. После того как работа с документом в программе Promt 98 завершена, его сохраняют в одном из общепринятых форматов. Для сохранения только оригинала (возможно, отредактированного) служит команда Файл > Сохранить > Исходный текст. Чтобы сохранить переведенный текст, применяют команду Файл > Сохранить > Перевод. В обоих случаях можно сохранять как содержимое документа, так и его элементы форматирования, сохраняющие, по возможности, оформление оригинала.
Чтобы продолжить работу с текстом позднее, удобнее сохранить его двуязычный вариант, так называемую билингву (Файл > Сохранить > Билингву). Информация сохраняется в виде неформатированного текста, причем абзацы оригинала и перевода чередуются.
Контроль качества перевода
Качество перевода определяется полнотой используемых словарей и учетом грамматических правил. При переводе можно как применять стандартные ресурсы программы, так и добавлять собственные.
Работа со словарями. Правила перевода отдельных слов (терминов) определяются использованием словарей. Для каждого переводимого документа задается набор применяемых словарей. Словари просматриваются в определенном порядке, и, как только переводимое слово обнаружено в каком-то из словарей, дальнейший просмотр прекращается. Программа Promt 98 использует при переводе три типа словарей.
• Генеральный словарь содержит общеупотребительную лексику и бытовые значения слов. Он используется всегда и притом самым последним, если слово не найдено ни в одном из других словарей. Изменение этого словаря невозможно.
• Специализированные словари содержат термины из различных областей знаний, причем значение переводимого термина выбирается в соответствии со специализацией словаря. Одни и те же слова могут иметь совершенно разный смысл в разных технических дисциплинах, так что выбор нужного словаря обеспечивает правильное использование специальной терминологии в переводе. Редактирование специализированных словарей не допускается, но их можно подключать или отключать при переводе документа.
• Пользовательский словарь формируется пользователем вручную. В него можно включить слова, отсутствующие в других словарях, или представить более точный перевод каких-то из терминов. Пользовательские словари можно произвольно создавать и редактировать. Применяют пользовательские словари обычно в первую очередь, до специализированных и генерального.
Узнать, какие словари используются при переводе, можно на вкладке Используемые словари на информационной панели.
Порядок перечисленных словарей соответствует порядку их использования. Генеральный словарь в этом списке не указывается. Чтобы задать иной набор словарей или изменить их порядок, следует щелкнуть на соответствующей вкладке информационной панели правой кнопкой мыши и выбрать в контекстном меню пункт Изменить список словарей.
Настройка производится в диалоговом окне Словари. Чтобы отключить словарь, надо выбрать его в списке и щелкнуть на кнопке Отключить. Добавление словарей производится с помощью кнопки Подключить. Для создания нового пользовательского словаря служит кнопка Создать. Чтобы изменить порядок просмотра словарей, надо выбрать перемещаемый словарь и использовать для его передвижения по списку кнопки Вверх и Вниз.
Транслитерация и резервирование. Не все слова требуют перевода. Обычно без изменений оставляют имена собственные. Иногда при этом используют транслитерацию — запись, использующую другой алфавит, но соответствующую написанию или произношению слова на исходном языке. В частности, транслитерация повсеместно используется при передаче иностранных имен и фамилий. Транслитерация не считается переводом.
Иногда необходимо отказаться от перевода целых абзацев. Например, нелепый результат даст попытка перевода исходных текстов программ. То же самое можно сказать и обо всех других случаях, где используются не значения слов, а сами слова как ключевые.
Чтобы зарезервировать слово, его надо выделить и щелкнуть на кнопке Зарезервировать слово на панели инструментов Перевод. В открывшемся диалоговом окне Зарезервировать слово можно уточнить написание, указать смысловую категорию, к которой относится данный термин, а также установить флажок Транслитерировать, если нужна транслитерация. Все зарезервированные слова заносятся в список на вкладке Зарезервированные слова на информационной панели, а в самом документе выделяются зеленым цветом.
Чтобы указать на то, что абзац не требует перевода, надо установить текстовый курсор внутрь данного абзаца и щелкнуть на кнопке Оставить абзац без перевода на панели инструментов Перевод.
Зарезервированный абзац также отображается зеленым цветом. Если резервирование слов или абзацев произведено после выполнения перевода, то для того, чтобы данные настройки вступили в силу, надо произвести перевод соответствующих абзацев заново.
Если приходится работать с тематически связанными документами или документом, разбитым на несколько отдельных файлов, следует использовать общий список зарезервированных слов. Чтобы сохранить список зарезервированных слов в отдельном файле, следует щелкнуть на вкладке Зарезервированные слова информационной панели правой кнопкой мыши и выбрать в контекстном меню пункт Сохранить список. Для загрузки такого автономного списка в документ используется команда Загрузить список из этого же контекстного меню.
Пополнение словаря. При автоматическом переводе реальных документов часто приходится сталкиваться со словами, которые программа перевода не смогла найти ни в одном из допустимых словарей. Эти слова заносятся в список на вкладке Незнакомые слова на информационной панели и выделяются в тексте документа красным цветом.
Слова могут быть неопознаны по разным причинам. В число их могут входить:
• опечатки в оригинале документа;
• для документов, преобразованных в электронную форму, ошибки распознавания;
• собственные имена, требующие резервирования;
• слова, отсутствующие в словарях.
В первых двух случаях необходимо отредактировать исходный текст, в третьем — зарезервировать слово и только в последнем случае необходимо занести слово в пользовательский словарь. При этом кроме собственно значения слова в переводе необходимо задать грамматические правила изменения форм этого слова и его сочетания с другими словами. В самом простом режиме работы (Начинающий) программа автоматически добавляет недостающие формы слова по заданному образцу.
Для того чтобы внести слово в словарь, надо выделить его и щелкнуть на кнопке Словарная статья на панели инструментов Перевод.
В диалоговом окне Открыть словарную статью нужно указать начальную форму слова и выбрать словарь, в который будет внесено это слово. После этого откроется диалоговое окно Словарная статья, используемое для добавления слова (рис. 17.5).
Выберите вкладку, соответствующую нужной части речи, установите переключатели, описывающие свойства данного слова, и щелкните на кнопке Добавить. В диалоговом окне Перевод укажите перевод слова, также в начальной форме. Если откроется диалоговое окно Тип словоизменения, надо щелкнуть на имеющейся в нем кнопке (для глаголов она называется Спряжение) и указать, как выглядят запрашиваемые формы слова. В заключение может быть задан вопрос о том, для каких форм исходного слова применим данный перевод и как они выглядят.
Имеющиеся словари можно также просматривать и редактировать. Для этого надо дважды щелкнуть на названии словаря на вкладке Используемые словари на информационной панели. Словарь открывается, и на экран выводится список включенных в него слов. Дважды щелкнув на любом слове, можно отредактировать соответствующую словарную статью. Результаты такого редактирования всегда заносятся только в пользовательский словарь.

Рис. 17.5. Средство наполнения пользовательского словаря
Дополнительные средства перевода
Кроме основного приложения, в состав программы Promt 98 входят дополнительные средства, предназначенные для быстрого автоматического перевода, выполняемого без активного контроля со стороны пользователя.
Так, средство пакетного перевода файлов (Пуск > Программы > PROMT 98 > File Translator) предназначено для автоматического перевода файлов в фоновом режиме. В левой части окна этого приложения располагается список файлов, ожидающих перевода — очередь перевода. Добавить файл в очередь можно при помощи кнопки Добавить на панели инструментов. В правой части окна располагаются элементы управления, позволяющие задать все настройки правил перевода, используемые в основной программе Promt 98. Теряется лишь диалоговый характер работы.
Когда очередь перевода сформирована, следует выбрать пункт Перевод! в строке меню. При наличии свободных ресурсов начнется последовательный перевод файлов, включенных в очередь. По завершении перевода исходный файл покинет очередь. Непосредственно по ходу работы можно добавлять в очередь новые задания, удалять задания, менять порядок их обработки. Самый быстрый способ добавления файла в очередь на перевод состоит в использовании пункта Отправить > File Translator в контекстном меню значка файла. Чтобы включить эту функцию, надо дать в программе File Translator команду Настройки > Параметры > Разное и установить флажок Добавить пункт в меню «Отправить».
Для быстрого перевода неформатированного текста можно использовать приложение QTrans (Пуск > Программы > PROMT 98 > QTrans). Оно не содержит никаких средств открытия или сохранения документов, так как предполагается, что переводимый текст вводится на верхнюю панель окна программы вручную или переносится туда через буфер обмена (рис. 17.6).

Рис. 17.6. Рабочее окно программы QTrans
Чтобы перевести текст (перевод появится на нижней панели), следует щелкнуть на кнопке Перевести. Перевод начинается автоматически при выборе направления перевода с помощью одноименной кнопки или при вставке данных из буфера обмена. Чтобы сохранить полученный перевод, его следует поместить в буфер обмена при помощи кнопки Копировать перевод, после чего произвести вставку в той программе, в которой этот текст будет использован.
Наибольшую ценность функция оперативного перевода представляет для документов Интернета. Сегодня большинство страниц используют английский язык, поэтому шансы найти нужную информацию именно на англоязычной странице максимальны. Для «синхронного» перевода Web-страниц предназначено приложение WebView (Пуск > Программы > PROMT 98 > WebView).
Приложение WebView представляет собой полноценный броузер, эквивалентный по своим возможностям программе Internet Explorer.
Отличие от обычных броузеров состоит в том, что окно программы разбито на две части. В верхней части страница отображается в том виде, в каком она получена из Интернета. Одновременно с началом загрузки страницы в нижней части окна начинает формироваться ее перевод. При этом переводу подвергается только текст, входящий в состав страницы, а адреса, на которые указывают гиперссылки, а также иллюстрации и другие вставные объекты отображаются без изменений. Переходы по гиперссылкам можно осуществлять как с верхней, так и с нижней части страницы.
Для поиска нужной информации на англоязычных серверах Интернета используют англоязычные поисковые системы. Приложение WebView позволяет производить поиск в Интернете с использованием ключевых слов, переведенных на английский язык.
Чтобы воспользоваться этой функцией, надо щелкнуть на кнопке Поиск в Web на панели инструментов. Диалоговое окно Поиск в Интернет содержит три вкладки, обеспечивающих три разных способа формирования запроса на поиск. После того как указаны ключевые слова и выбрана поисковая система, сформированный запрос, содержащий уже переведенные ключевые слова, отображается в специальном поле, чтобы можно было визуально проверить его правильность.
После щелчка на кнопке ОК запрос направляется в указанную поисковую систему. Web-страница, сформированная этой системой, как обычно, отображается в верхней области окна программы WebView, а в нижней части отображается ее перевод, точно так же, как и для любой другой Web-страницы.
Базовая аппаратная конфигурация
Персональный компьютер — универсальная техническая система. Его конфигурацию (состав оборудования) можно гибко изменять по мере необходимости. Тем не менее, существует понятие базовой конфигурации, которую считают типовой. В таком комплекте компьютер обычно поставляется. Понятие базовой конфигурации может меняться. В настоящее время в базовой конфигурации рассматривают четыре устройства (рис. 3.1):
• системный блок;
• монитор;
• клавиатуру;
• мышь.
Системный блок
Системный блок представляет собой основной узел, внутри которого установлены наиболее важные компоненты. Устройства, находящиеся внутри системного блока, называют внутренними, а устройства, подключаемые к нему снаружи, называют внешними. Внешние дополнительные устройства, предназначенные для ввода, вывода и длительного хранения данных, также называют периферийными.
По внешнему виду системные блоки различаются формой корпуса. Корпуса персональных компьютеров выпускают в горизонтальном (desktop) и вертикальном (tower) исполнении. Корпуса, имеющие вертикальное исполнение, различают по габаритам: полноразмерный (big tower), среднеразмерный (midi tower) и малоразмерный (mini tower). Среди корпусов, имеющих горизонтальное исполнение, выделяют плоские и особо плоские (slim).
Кроме формы, для корпуса важен параметр, называемый форм-фактором. От него зависят требования к размещаемым устройствам. В настоящее время в основном используются корпуса двух форм-факторов: А Ти АТХ. Форм-фактор корпуса должен быть обязательно согласован с форм-фактором главной (системной) платы компьютера, так называемой материнской платы (см. ниже).
Корпуса персональных компьютеров поставляются вместе с блоком питания и, таким образом, мощность блока питания также является одним из параметров корпуса. Для массовых моделей достаточной является мощность блока питания 200-250 Вт.

Рис. 3.1. Базовая конфигурация компьютерной системы
Монитор
Монитор — устройство визуального представления данных. Это не единственно возможное, но главное устройство вывода. Его основными потребительскими параметрами являются: размер и шаг маски экрана, максимальная частота регенерации изображения, класс защиты.
Размер монитора измеряется между противоположными углами трубки кинескопа по диагонали. Единица измерения — дюймы. Стандартные размеры: 14"; 15"; 17"; 19"; 20"; 21". В настоящее время наиболее универсальными являются мониторы размером 15 и 17 дюймов, а для операций с графикой желательны мониторы размером 19-21 дюйм.
Изображение на экране монитора получается в результате облучения люминофорного покрытия остронаправленным пучком электронов, разогнанных в вакуумной колбе. Для получения цветного изображения люминофорное покрытие имеет точки или полоски трех типов, светящиеся красным, зеленым и синим цветом. Чтобы на экране все три луча сходились строго в одну точку и изображение было четким, перед люминофором ставят маску — панель с регулярно расположенными отверстиями или щелями. Часть мониторов оснащена маской из вертикальных проволочек, что усиливает яркость и насыщенность изображения. Чем меньше шаг между отверстиями или щелями (шаг маски), тем четче и точнее полученное изображение. Шаг маски измеряют в долях миллиметра. В настоящее время наиболее распространены мониторы с шагом маски 0,25-0,27 мм. Устаревшие мониторы могут иметь шаг до 0,43 мм, что негативно сказывается на органах зрения при работе с компьютером. Модели повышенной стоимости могут иметь значение менее 0,25 мм.
Частота регенерации (обновления) изображения показывает, сколько раз в течение секунды монитор может полностью сменить изображение (поэтому ее также называют частотой кадров). Этот параметр зависит не только от монитора, но и от свойств и настроек видеоадаптера (см. ниже), хотя предельные возможности определяет все-таки монитор.
Частоту регенерации изображения измеряют в герцах (Гц). Чем она выше, тем четче и устойчивее изображение, тем меньше утомление глаз, тем больше времени можно работать с компьютером непрерывно.
При частоте регенерации порядка 60 Гц мелкое мерцание изображения заметно невооруженным глазом. Сегодня такое значение считается недопустимым. Минимальным считают значение 75 Гц, нормативным — 85 Гц и комфортным — 100 Гц и более.
Класс защиты монитора определяется стандартом, которому соответствует монитор с точки зрения требований техники безопасности. В настоящее время общепризнанными считаются следующие международные стандарты: MPR-II, ТСО-92, ТСО-95, ТСО-99 (приведены в хронологическом порядке). Стандарт МРЛ-Яограничил уровни электромагнитного излучения пределами, безопасными для человека. В стандарте ТСО-92 эти нормы были сохранены, а в стандартах ТСО-95 и ТСО-99 ужесточены. Эргономические и экологические нормы впервые появились в стандарте ТСО-95, а стандарт ТСО-99 установил самые жесткие нормы по параметрам, определяющим качество изображения (яркость, контрастность, мерцание, антибликовые свойства покрытия).
Большинством параметров изображения, полученного на экране монитора, можно управлять программно. Программные средства, предназначенные для этой цели, обычно входят в системный комплект программного обеспечения — мы рассмотрим их при изучении операционной системы компьютера.
Клавиатура
Клавиатура — клавишное устройство управления персональным компьютером. Служит для ввода алфавитно-цифровых (знаковых) данных, а также команд управления. Комбинация монитора и клавиатуры обеспечивает простейший интерфейс пользователя. С помощью клавиатуры управляют компьютерной системой, а с помощью монитора получают от нее отклик.
Принцип действия. Клавиатура относится к стандартным средствам персонального компьютера. Ее основные функции не нуждаются в поддержке специальными системными программами (драйверами). Необходимое программное обеспечение для начала работы с компьютером уже имеется в микросхеме ПЗУ в составе базовой системы ввода-вывода (BIOS), и потому компьютер реагирует на нажатия клавиш сразу после включения.
Принцип действия клавиатуры заключается в следующем.
1.При нажатии на клавишу (или комбинацию клавиш) специальная микросхема,
встроенная в клавиатуру, выдает так называемый скак-код.
2.Скан-код поступает в микросхему, выполняющую функции парта клавиатуры. (Порты — специальные аппаратно-логические устройства, отвечающие за связьпроцессора с другими устройствами.) Данная микросхема находится на основной плате компьютера внутри системного блока.
3.Порт клавиатуры выдает процессору прерывание с фиксированным номером. Для клавиатуры номер прерывания — 9 (Interrupt 9, Int,9).
4.Получив прерывание, процессор откладывает текущую работу и по номеру прерывания обращается в специальную область оперативной памяти, в которой находится так называемый вектор прерываний. Вектор прерываний — это список адресных данных с фиксированной длиной записи. Каждая запись содержит адрес программы, которая должна обслужить прерывание с номером, совпадаю щим с номером записи.
5.Определив адрес начала программы, обрабатывающей возникшее прерывание, процессор переходит к ее исполнению. Простейшая программа обработки клавиатурного прерывания «зашита» в микросхему ПЗУ, но программисты могут «подставить» вместо нее свою программу, если изменят данные в векторе прерываний.
6.Программа-обработчик прерывания направляет процессор к порту клавиатуры, где он находит скан-код, загружает его в свои регистры, потом под управлением обработчика определяет, какой код символа соответствует данному скан-коду.
7.Далее обработчик прерываний отправляет полученный код символа в небольшую область памяти, известную как буфер клавиатуры, и прекращает свою работу, известив об этом процессор.
8.Процессор прекращает обработку прерывания и возвращается к отложенной задаче.
9.Введенный символ хранится в буфере клавиатуры до тех пор, пока его не заберет оттуда та программа, для которой он и предназначался, например текстовый редактор или текстовый процессор. Если символы поступают в буфер чаще, чем забираются оттуда, наступает эффект переполнения буфера. В этом случае ввод новых символов на некоторое время прекращается.
На практике в этот момент при нажатии на клавишу мы слышим предупреждающий звуковой сигнал и не наблюдаем ввода данных.
Состав клавиатуры. Стандартная клавиатура имеет более 100 клавиш, функционально распределенных по нескольким группам (см. рис. 3.2)
Группа алфавитно -цифровых клавиш предназначена для ввода знаковой информации и команд, набираемых по буквам. Каждая клавиша может работать в нескольких режимах (регистрах) и, соответственно, может использоваться для ввода нескольких символов. Переключение между нижним регистром (для ввода строчных символов) и верхним регистром (для ввода прописных символов) выполняют удержанием клавиши SHIFT (нефиксированное переключение). При необходимости жестко переключить регистр используют клавишу CAPS LOCK (фиксированное переключение). Если клавиатура используется для ввода данных, абзац закрывают нажатием клавиши ENTER. При этом автоматически начинается ввод текста с новой строки. Если клавиатуру используют для ввода команд, клавишей ENTER завершают ввод команды и начинают ее исполнение.

Рис. 3.2. Группы клавиш стандартной клавиатуры
Для разных языков существуют различные схемы закрепления символов национальных алфавитов за конкретными алфавитно-цифровыми клавишами. Такие схемы называются раскладками клавиатуры. Переключения между различными раскладками выполняются программным образом — это одна из функций операционной системы. Соответственно, способ переключения зависит от того, в какой операционной системе работает компьютер. Например, в системе Windows 98 для этой цели могут использоваться следующие комбинации: левая клавиша ALT+SHIFT или CTRL+SHIFT. При работе с другой операционной системой способ переключения можно установить по справочной системе той программы, которая выполняет переключение.
Общепринятые раскладки клавиатуры имеют свои корни в раскладках клавиатур пишущих машинок. Для персональных компьютеров IBM PC типовыми считаются раскладки QWERTY (английская) и ЙЦУКЕНГ (русская). Раскладки принято именовать по символам, закрепленным за первыми клавишами верхней строки алфавитной группы.
Группа функциональных клавиш включает двенадцать клавиш (от F1 до F12), размещенных в верхней части клавиатуры. Функции, закрепленные за данными клавишами, зависят от свойств конкретной работающей в данный момент программы, а в некоторых случаях и от свойств операционной системы. Общепринятым для большинства программ является соглашение о том, что клавиша F1 вызывает справочную систему, в которой можно найти справку о действии прочих клавиш.
Служебные клавиши располагаются рядом с клавишами алфавитно-цифровой группы. В связи с тем, что ими приходится пользоваться особенно часто, они имеют увеличенный размер. К ним относятся рассмотренные выше клавиши SHIFT и ENTER, регистровые клавиши ALT и CTRL (их используют в комбинации с другими клавишами для формирования команд), клавиша TAB (для ввода позиций табуляции при наборе текста), клавиша ESC (от английского слова Escape) для отказа от исполнения последней введенной команды и клавиша BACKSPACE для удаления только что введенных знаков (она находится над клавишей ENTER и часто маркируется стрелкой, направленной влево).
Служебные клавиши PRINT SCREEN, SCROLL LOCK и PAUSE/BREAK размещаются справа от группы функциональных клавиш и выполняют специфические функции, зависящие от действующей операционной системы. Общепринятыми являются следующие действия:
PRINT SCREEN — печать текущего состояния экрана на принтере (для MS-DOS) или сохранение его в специальной области оперативной памяти, называемой буфером обмена (для Windows).
SCROLL LOCK — переключение режима работы в некоторых (как правило, устаревших) программах.
PAUSE/BREAK — приостановка/прерывание текущего процесса.
Две группы клавиш управления курсором расположены справа от алфавитно-цифровой панели. Курсором называется экранный элемент, указывающий место ввода знаковой информации. Курсор используется при работе с программами, выполняющими ввод данных и команд с клавиатуры. Клавиши управления курсором позволяют управлять позицией ввода.
Четыре клавиши со стрелками выполняют смещение курсора в направлении, указанном стрелкой.
Действие прочих клавиш описано ниже.
PAGE UP/PAGE DOWN — перевод курсора на одну страницу вверх или вниз. Понятие «страница» обычно относится к фрагменту документа, видимому на экране. В графических операционных системах (например Windows) этими клавишами выполняют «прокрутку» содержимого в текущем окне. Действие этих клавиш во многих программах может быть модифицировано с помощью служебных регистровых клавиш, в первую очередь SHIFT и CTRL. Конкретный результат модификации зависит от конкретной программы и/или операционной системы.
Клавиши НОМЕ и END переводят курсор в начало или конец текущей строки, соответственно. Их действие также модифицируется регистровыми клавишами.
Традиционное назначение клавиши INSERT состоит в переключении режима ввода данных (переключение между режимами вставки и замены). Если текстовый курсор находится внутри существующего текста, то в режиме вставки происходит ввод новых знаков без замены существующих символов (текст как бы раздвигается). В режиме замены новые знаки заменяют текст, имевшийся ранее в позиции ввода.
В современных программах действие клавиши INSERT может быть иным. Конкретную информацию следует получить в справочной системе программы. Возможно, что действие этой клавиши является настраиваемым, — это также зависит от свойств конкретной программы.
Клавиша DELETE предназначена для удаления знаков, находящихся справа от текущего положения курсора. При этом положение позиции ввода остается неизменным.

Группа клавиш дополнительной панели дублирует действие цифровых и некоторых знаковых клавиш основной панели. Во многих случаях для использования этой группы клавиш следует предварительно включать клавишу-переключатель NUM LOCK (о состоянии переключателей NUM LOCK, CAPS LOCK и SCROLL LOCK можно судить по светодиодным индикаторам, обычно расположенным в правом верхнем углу клавиатуры).
Появление дополнительной панели клавиатуры относится к началу 80-х годов. В то время клавиатуры были относительно дорогостоящими устройствами. Первоначальное назначение дополнительной панели состояло в снижении износа основной панели при проведении расчетно-кассовых вычислений, а также при управлении компьютерными играми (при выключенном переключателе NUM LOCK клавиши дополнительной панели могут использоваться в качестве клавиш управления курсором).
В наши дни клавиатуры относят к малоценным быстроизнашивающимся устройствам и приспособлениям, и существенной необходимости оберегать их от износа нет. Тем не менее, за дополнительной клавиатурой сохраняется важная функция ввода символов, для которых известен расширенный код ASCII (см. выше), но неизвестно закрепление за клавишей клавиатуры. Так, например, известно, что символ «§» (параграф) имеет код 0167, а символ «°» (угловой градус) имеет код 0176, но соответствующих им клавиш на клавиатуре нет. В таких случаях для их ввода используют дополнительную панель.
Порядок ввода символов по известному ALT-коду.
1. Нажать и удержать клавишу ALT.
2. Убедиться в том, что включен переключатель NUM LOCK.
3. Не отпуская клавиши ALT, набрать последовательно на дополнительной панелиALT-код вводимого символа, например: 0167.
4. Отпустить клавишу ALT. Символ, имеющий код 0167, появится на экране в позиции ввода.
Настройка клавиатуры. Клавиатуры персональных компьютеров обладают свойством повтора знаков, которое используется для автоматизации процесса ввода. Оно состоит в том, что при длительном удержании клавиши начинается автоматический ввод связанного с ней кода. При этом настраиваемыми параметрами являются:
• интервал времени после нажатия, по истечении которого начнется автоматический повтор кода;
• темп повтора (количество знаков в секунду).
Средства настройки клавиатуры относятся к системным и обычно входят в состав операционной системы.
Кроме параметров режима повтора настройке подлежат также используемые раскладки и органы управления, используемые для переключения раскладок.
Со средствами настройки клавиатуры мы познакомимся при изучении функций операционной системы.
Мышь
Мышь — устройство управления манипуляторного типа. Представляет собой плоскую коробочку с двумя-тремя кнопками. Перемещение мыши по плоской поверхности синхронизировано с перемещением графического объекта (указателя мыши) на экране монитора.
Принцип действия. В отличие от рассмотренной ранее клавиатуры, мышь не является стандартным органом управления, и персональный компьютер не имеет для нее выделенного порта. Для мыши нет и постоянного выделенного прерывания, а базовые средства ввода и вывода (BIOS) компьютера, размещенные в постоянном запоминающем устройстве (ПЗУ), не содержат программных средств для обработки прерываний мыши.
В связи с этим в первый момент после включения компьютера мышь не работает. Она нуждается в поддержке специальной системной программы — драйвера мыши. Драйвер устанавливается либо при первом подключении мыши, либо при установке операционной системы компьютера. Хотя мышь и не имеет выделенного порта на материнской плате, для работы с ней используют один из стандартных портов, средства для работы с которыми имеются в составе BIOS. Драйвер мыши предназначен для интерпретации сигналов, поступающих через порт. Кроме того, он обеспечивает механизм передачи информации о положении и состоянии мыши операционной системе и работающим программам.
Компьютером управляют перемещением мыши по плоскости и кратковременными нажатиями правой и левой кнопок. (Эти нажатия называются щелчками.) В отличие от клавиатуры мышь не может напрямую использоваться для ввода знаковой информации — ее принцип управления является событийным. Перемещения мыши и щелчки ее кнопок являются событиями с точки зрения ее программы-драйвера. Анализируя эти события, драйвер устанавливает, когда произошло событие и в каком месте экрана в этот момент находился указатель.
Эти данные передаются в прикладную программу, с которой работает пользователь в данный момент. По ним программа может определить команду, которую имел в виду пользователь, и приступить к ее исполнению.
Комбинация монитора и мыши обеспечивает наиболее современный тип интерфейса пользователя, который называется графическим. Пользователь наблюдает на экране графические объекты и элементы управления. С помощью мыши он изменяет свойства объектов и приводит в действие элементы управления компьютерной системой, а с помощью монитора получает от нее отклик в графическом виде.
Стандартная мышь имеет только две кнопки, хотя существуют нестандартные мыши с тремя кнопками или с двумя кнопками и одним вращающимся регулятором. Функции нестандартных органов управления определяются тем программным обеспечением, которое поставляется вместе с устройством.
К числу регулируемых параметров мыши относятся: чувствительность (выражает величину перемещения указателя на экране при заданном линейном перемещении мыши), функции левой и правой кнопок, а также чувствительность к двойному нажатию (максимальный интервал времени, при котором два щелчка кнопкой мыши расцениваются как один двойной щелчок). Программные средства, предназначенные для этих регулировок, обычно входят в системный комплект программного обеспечения — мы рассмотрим их при изучении операционной системы.
Данные
Носители данных
Данные — диалектическая составная часть информации. Они представляют собой зарегистрированные сигналы. При этом физический метод регистрации может быть любым: механическое перемещение физических тел, изменение их формы или параметров качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и (или) характера химических связей, изменение состояния электронной системы и многое другое. В соответствии с методом регистрации данные могут храниться и транспортироваться на носителях различных видов.
Самым распространенным носителем данных, хотя и не самым экономичным, по-видимому, является бумага. На бумаге данные регистрируются путем изменения оптических характеристик ее поверхности. Изменение оптических свойств (изменение коэффициента отражения поверхности в определенном диапазоне длин волн) используется также в устройствах, осуществляющих запись лазерным лучом на пластмассовых носителях с отражающим покрытием (CD-ROM). В качестве носителей, использующих изменение магнитных свойств, можно назвать магнитные ленты и диски. Регистрация данных путем изменения химического состава поверхностных веществ носителя широко используется в фотографии. На биохимическом уровне происходит накопление и передача данных в живой природе.
Носители данных интересуют нас не сами по себе, а постольку, поскольку свойства информации весьма тесно связаны со свойствами ее носителей. Любой носитель можно характеризовать параметром разрешающей способности (количеством данных, записанных в принятой для носителя единице измерения) и динамическим диапазоном (логарифмическим отношением интенсивности амплитуд максимального и минимального регистрируемого сигналов). От этих свойств носителя нередко зависят такие свойства информации, как полнота, доступность и достоверность. Так, например, мы можем рассчитывать на то, что в базе данных, размещаемой на компакт-диске, проще обеспечить полноту информации, чем в аналогичной по назначению базе данных, размещенной на гибком магнитном диске, поскольку в первом случае плотность записи данных на единице длины дорожки намного выше.
Для обычного потребителя доступность информации в книге заметно выше, чем той же информации на компакт-диске, поскольку не все потребители обладают необходимым оборудованием. И, наконец, известно, что визуальный эффект от просмотра слайда в проекторе намного больше, чем от просмотра аналогичной иллюстрации, напечатанной на бумаге, поскольку диапазон яркостных сигналов в проходящем свете на два-три порядка больше, чем в отраженном.
Задача преобразования данных с целью смены носителя относится к одной из важнейших задач информатики. В структуре стоимости вычислительных систем устройства для ввода и вывода данных, работающие с носителями информации, составляют до половины стоимости аппаратных средств.
Операции с данными
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе трудозатраты на обработку данных неуклонно возрастают. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов обрабатываемых данных, тоже связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие основные:
• сбор данных—накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация данных — приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация данных — отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
• сортировка данных — упорядочение данных по заданному признаку с целью удобства использования; повышает доступность информации;
архивация данных — организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита данных — комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
• транспортировка данных—прием и передача (доставка и поставка) данных междуудаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя — клиентом;
• преобразование данных — перевод данных из одной формы в другую или изодной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме,но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также приих транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примераможно упомянуть, что для транспортировки цифровых потоков данных по каналамтелефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства — телефонные модемы.
Приведенный здесь список типовых операций с данными далеко не полон. Миллионы людей во всем мире занимаются созданием, обработкой, преобразованием и транспортировкой данных, и на каждом рабочем месте выполняются свои специфические операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный список возможных операций составить невозможно, да и не нужно. Сейчас нам важен другой вывод: работа с информацией может иметь огромную трудоемкость, и ее надо автоматизировать.
Кодирование данных двоичным кодом
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления — для этого обычно используется прием кодирования, то есть выражение данных одного типа через данные другого типа. Естественные человеческие языки — это не что иное, как системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки (системы кодирования компонентов языка с помощью графических символов). История знает интересные, хотя и безуспешные попытки создания «универсальных» языков и азбук. По-видимому, безуспешность попыток их внедрения связана с тем, что национальные и социальные образования естественным образом понимают, что изменение системы кодирования общественных данных непременно приводит к изменению общественных методов (то есть норм права и морали), а это может быть связано с социальными потрясениями.
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры. В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое.
Своя система существует и в вычислительной технике — она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски — binary digit или сокращенно bit (бит).

Рис. 1.2. Примеры различных систем кодирования
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11
Тремя битами можно закодировать восемь различных значений:
000 001 010 011 100 101 ПО 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
N=2m,
где N— количество независимых кодируемых значений;
т — разрядность двоичного кодирования, принятая в данной системе.
Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом достаточно просто — достаточно взять целое число и делить его пополам до тех пор, пока частное не будет равно единице. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного числа.
19:2 = 9+1
9:2 = 4 + 1
4:2=2+0
2:2=1+0
Таким образом, 1910 = 100112.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65 535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926×101
300 000 = 0,3×106
123 456 789 = 0,123456789×1010
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком).
Кодирование текстовых данных
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например символ «§».
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов.
Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI—American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 1.1.

Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица 1.3). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 1.4).

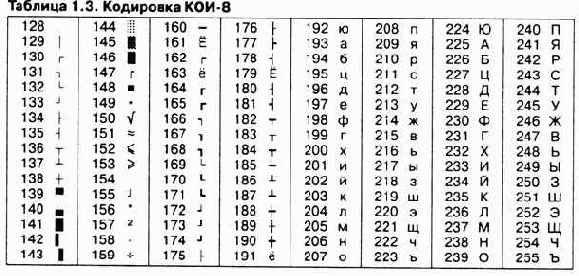

На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 1.5).

В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше.
Такая система, основанная на 16- разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность такого подхода, простой механический переход на данную систему долгое время сдерживался из-за недостаточных ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и сегодня мы наблюдаем постепенный перевод документов и программных средств на универсальную систему кодирования. Для индивидуальных пользователей это еще больше добавило забот по согласованию документов, выполненных в разных системах кодирования, с программными средствами, но это надо понимать как трудности переходного периода.
Кодирование графических данных
 |
издавна принятый в полиграфии
Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром (рис. 1.3).
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие.
В качестве таких составляющих используют три основные цвета: красный (Red, К), зеленый (Green, G) и синий (Blue, В). На практике считается (хотя теоретически это не совсем так), что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов. Такая система кодирования называется системой RGB по первым буквам названий основных цветов.
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Соответственно, дополнительными цветами являются: голубой (Cyan, С), пурпурный (Magenta, M) и желтый (Yellow, У). Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, то есть любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется еще и четвертая краска — черная (Black, К). Поэтому данная система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим тоже называется полноцветным (True Color).
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается.
Кодирование цветной графики 16- разрядными двоичными числами называется режимом High Color.
При кодировании информации о цвете с помощью восьми бит данных можно передать только 256 цветовых оттенков. Такой метод кодирования цвета называется индексным. Смысл названия в том, что, поскольку 256 значений совершенно недостаточно, чтобы передать весь диапазон цветов, доступный человеческому глазу, код каждой точки растра выражает не цвет сам по себе, а только его номер (индекс) в некоей справочной таблице, называемой палитрой. Разумеется, эта палитра должна прикладываться к графическим данным — без нее нельзя воспользоваться методами воспроизведения информации на экране или бумаге (то есть, воспользоваться, конечно, можно, но из-за неполноты данных полученная информация не будет адекватной: листва на деревьях может оказаться красной, а небо — зеленым).
Кодирование звуковой информации
Приемы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ДАЛ).
При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
Метод таблично-волнового ( Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Основные структуры данных
Работа с большими наборами данных автоматизируется проще, когда данные упорядочены, то есть образуют заданную структуру. Существует три основных типа структур данных: линейная, иерархическая и табличная. Их можно рассмотреть на примере обычной книги.
Если разобрать книгу на отдельные листы и перемешать их, книга потеряет свое назначение. Она по-прежнему будет представлять набор данных, но подобрать адекватный метод для получения из нее информации весьма непросто. (Еще хуже дело будет обстоять, если из книги вырезать каждую букву отдельно — в этом случае вряд ли вообще найдется адекватный метод для ее прочтения.)
Если же собрать все листы книги в правильной последовательности, мы получим простейшую структуру данных — линейную. Такую книгу уже можно читать, хотя для поиска нужных данных ее придется прочитать подряд, начиная с самого начала, что не всегда удобно.
Для быстрого поиска данных существует иерархическая структура. Так, например, книги разбивают на части, разделы, главы, параграфы и т. п. Элементы структуры более низкого уровня входят в элементы структуры более высокого уровня: разделы состоят из глав, главы из параграфов и т. д.
Для больших массивов поиск данных в иерархической структуре намного проще, чем в линейной, однако и здесь необходима навигация, связанная с необходимостью просмотра. На практике задачу упрощают тем, что в большинстве книг есть вспомогательная перекрестная таблица, связывающая элементы иерархической структуры с элементами линейной структуры, то есть связывающая разделы, главы и параграфы с номерами страниц. В книгах с простой иерархической структурой, рассчитанных на последовательное чтение, эту таблицу принято называть оглавлением, а в книгах со сложной структурой, допускающей выборочное чтение, ее называют содержанием.
Линейные структуры (списки данных, векторы данных)
Линейные структуры — это хорошо знакомые нам списки. Список — это простейшая структура данных, отличающаяся тем, что каждый элемент данных однозначно определяется своим номером в массиве. Проставляя номера на отдельных страницах рассыпанной книги, мы создаем структуру списка. Обычный журнал посещаемости занятий, например, имеет структуру списка, поскольку все студенты группы зарегистрированы в нем под своими уникальными номерами. Мы называем номера уникальными потому, что в одной группе не могут быть зарегистрированы два студента с одним и тем же номером.
При создании любой структуры данных надо решить два вопроса: как разделять элементы данных между собой и как разыскивать нужные элементы. В журнале посещаемости, например, это решается так: каждый новый элемент списка заносится с новой строки, то есть разделителем является конец строки. Тогда нужный элемент можно разыскать по номеру строки.
N п/п Фамилия, Имя, Отчество
1 Аистов Александр Алексеевич
2 Бобров Борис Борисович
3 Воробьева Валентина Владиславовна
………………………………………………..
27 Сорокин Сергей Семенович
Разделителем может быть и какой- нибудь специальный символ. Нам хорошо известны разделители между словами — это пробелы. В русском и во многих европейских языках общепринятым разделителем предложений является точка. В рассмотренном нами классном журнале в качестве разделителя можно использовать любой символ, который не встречается в самих данных, например символ «*». Тогда наш список выглядел бы так:
Аистов Александр Алексеевич * Бобров Борис Борисович * Воробьева Валентина Владиславовна *... * Сорокин Сергей Семенович
В этом случае для розыска элемента с номером п надо просмотреть список начиная с самого начала и пересчитать встретившиеся разделители. Когда будет отсчитано n-i разделителей, начнется нужный элемент. Он закончится, когда будет встречен следующий разделитель.
Еще проще можно действовать, если все элементы списка имеют равную длину. В этом случае разделители в списке вообще не нужны. Для розыска элемента с номером п надо просмотреть список с самого начала и отсчитать а(и-1) символ, где а — длина одного элемента. Со следующего символа начнется нужный элемент. Его длина тоже равна а, поэтому его конец определить нетрудно. Такие упрощенные списки, состоящие из элементов равной длины, называют векторами данных. Работать с ними особенно удобно.
Таким образом, линейные структуры данных (списки) — это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
Табличные структуры (таблицы данных, матрицы данных)
С таблицами данных мы тоже хорошо знакомы, достаточно вспомнить всем известную таблицу умножения. Табличные структуры отличаются от списочных тем, что элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списках, а из нескольких.
Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужная ячейка находится на их пересечении, а элемент выбирается из ячейки.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, имеющих структуру списка. Например, когда таблицы печатают в книгах, строки и столбцы разделяют графическими элементами — линиями вертикальной и горизонтальной разметки (рис. 1.4).
Если нужно сохранить таблицу в виде длинной символьной строки, используют один символ-разделитель между элементами, принадлежащими одной строке, и другой разделитель для отделения строк, например так:
Меркурий*0,39*0,056*0#Ввнера*0,67*0,88*0#Земля*1,0*1(0*1#Марс*1)б1*0,1*2#...
|
Планета |
Расстояние до Солнца, а.е. |
Относительная масса |
Количество спутников |
|
Меркурий |
0,39 |
0,056 |
0 |
|
Венера |
0,67 |
0,88 |
0 |
|
Земля |
1,0 |
1,0 |
1 |
|
Марс |
1,51 |
0,1 |
2 |
|
Юпитер |
5,2 |
318 |
16 |
два типа разделителей — вертикальные и горизонтальные
Для розыска элемента, имеющего адрес ячейки (т,п), надо просмотреть набор данных с самого начала и пересчитать внешние разделители. Когда будет отсчитан т-1 разделитель, надо пересчитывать внутренние разделители. После того как будет найден и-1 разделитель, начнется нужный элемент. Он закончится, когда будет встречен любой очередной разделитель.
Еще проще можно действовать, если все элементы таблицы имеют равную длину. Такие таблицы называют матрицами. В данном случае разделители не нужны, поскольку все элементы имеют равную длину и количество их известно. Для розыска элемента с адресом (т, п) в матрице, имеющей М строк и N столбцов, надо просмотреть ее с самого начала и отсчитать a [N(m -1) + (п -1)] символ, где а — длина одного элемента. Со следующего символа начнется нужный элемент. Его длина тоже равна а, поэтому его конец определить нетрудно.
Таким образом, табличные структуры данных (матрицы) — это упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент.
Многомерные таблицы. Выше мы рассмотрели пример таблицы, имеющей два измерения (строка и столбец), но в жизни нередко приходится иметь дело с таблицами, у которых количество измерений больше. Вот пример таблицы, с помощью которой может быть организован учет учащихся.
Номер факультета: 3
Номер курса (на факультете): 2
Номер специальности (на курсе): 2
Номер группы в потоке одной специальности: 1
Номер учащегося в группе: 19
Размерность такой таблицы равна пяти, и для однозначного отыскания данных об учащемся в подобной структуре надо знать все пять параметров (координат).
Иерархические структуры данных
Нерегулярные данные, которые трудно представить в виде списка или таблицы, часто представляют в виде иерархических структур. С подобными структурами мы очень хорошо знакомы по обыденной жизни. Иерархическую структуру имеет система почтовых адресов. Подобные структуры также широко применяют в научных систематизациях и всевозможных классификациях (рис. 1.5).

Рис. 1.5. Пример иерархической структуры данных
В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведущим от вершины структуры к данному элементу. Вот, например, как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows 98):
Пуск > Программы > Стандартные > Калькулятор.
Дихотомия данных. Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута оказывается больше, чем длина самих данных, к которым он ведет.
Поэтому в информатике применяют методы для регуляризации иерархических структур с тем, чтобы сделать путь доступа компактным. Один из методов получил название дихотомии. Его суть понятна из примера, представленного на рис. 1.6.
В иерархической структуре, построенной методом дихотомии, путь доступа к любому элементу можно представить как путь через рациональный лабиринт с поворотами налево (0) или направо (1) и, таким образом, выразить путь доступа в виде компактной двоичной записи. В нашем примере путь доступа к текстовому процессору Word 2000 выразится следующим двоичным числом: 1010.
Упорядочение структур данных
Списочные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочения является сортировка. Данные можно сортировать по любому избранному критерию, например: по алфавиту, по возрастанию порядкового номера или по возрастанию какого-либо параметра.

Рис. 1.6. Пример, поясняющий принцип действия метода дихотомии
Несмотря на многочисленные удобства, у простых структур данных есть и недостаток — их трудно обновлять. Если, например, перевести студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним.
Таким образом, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов. В журналах успеваемости это пережить нетрудно, но в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы.
Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных.
Их легко развивать путем создания новых уровней. Даже если в учебном заведении будет создан новый факультет, это никак не отразится на пути доступа к сведениям об учащихся прочих факультетов.
Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения. Часто методы упорядочения в таких структурах основывают на предварительной индексации, которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который можно использовать при поиске, сортировке и т. п. Ранее рассмотренный принцип дихотомии на самом деле является одним из методов индексации данных в иерархических структурах. После такой индексации данные легко разыскиваются по двоичному коду связанного с ними индекса.
Адресные данные. Если данные хранятся не как попало, а в организованной структуре (причем любой), то каждый элемент данных приобретает новое свойство (параметр), который можно назвать адресом. Конечно, работать с упорядоченными данными удобнее, но за это приходится платить их размножением, поскольку адреса элементов данных — это тоже данные, и их тоже надо хранить и обрабатывать.
Файлы и файловая структура
Единицы представления данных
Существует множество систем представления данных. С одной из них, принятой в информатике и вычислительной технике, двоичным кодом, мы познакомились выше. Наименьшей единицей такого представления является бит (двоичный разряд).
Совокупность двоичных разрядов, выражающих числовые или иные данные, образует некий битовый рисунок. Практика показывает, что с битовым представлением удобнее работать, если этот рисунок имеет регулярную форму. В настоящее время в качестве таких форм используются группы из восьми битов, которые называются байтами.
| Десятичное число | Двоичное число | Байт | |||
| 1 | 1 | 0000 0001 | |||
| 2 | 10 | 0000 0010 | |||
| 255 | 11111111 | 1111 1111 |
Понятие о байте, как группе взаимосвязанных битов, появилось вместе с первыми образцами электронной вычислительной техники. Долгое время оно было машинно-зависимым^ то есть для разных вычислительных машин длина байта была разной. Только в конце 60-х годов понятие байта стало универсальным и машиннонезависимым.
Выше мы видели, что во многих случаях целесообразно использовать не восьмиразрядное кодирование, а 16-разрядное, 24-разрядное, 32-разрядное и более. Группа из 16 взаимосвязанных бит (двух взаимосвязанных байтов) в информатике называется словом. Соответственно, группы из четырех взаимосвязанных байтов (32 разряда) называются удвоенным словом, а группы из восьми байтов (64 разряда) — учетверенным словом. Пока, на сегодняшний день, такой системы обозначения достаточно.
Единицы измерения данных
Существует много различных систем и единиц измерения данных. Каждая научная дисциплина и каждая область человеческой деятельности может использовать свои, наиболее удобные или традиционно устоявшиеся единицы. В информатике для измерения данных используют тот факт, что разные типы данных имеют универсальное двоичное представление, и потому вводят свои единицы данных, основанные на нем.
Наименьшей единицей измерения является байт.
Поскольку одним байтом, как правило, кодируется один символ текстовой информации, то для текстовых документов размер в байтах соответствует лексическому объему в символах (пока исключение представляет рассмотренная выше универсальная кодировка UNICODE).
Более крупная единица измерения — килобайт (Кбайт). Условно можно считать, что 1 Кбайт примерно равен 1000 байт. Условность связана с тем, что для вычислительной техники, работающей с двоичными числами, более удобно представление чисел в виде степени двойки, и потому на самом деле 1 Кбайт равен 210 байт (1024 байт). Однако всюду, где это не принципиально, с инженерной погрешностью (до 3 %) «забывают» о «лишних» байтах.
В килобайтах измеряют сравнительно небольшие объемы данных. Условно можно считать, что одна страница неформатированного машинописного текста составляет около 2 Кбайт.
Более крупные единицы измерения данных образуются добавлением префиксов мега-, гига-, тера-; в более крупных единицах пока нет практической надобности.
1 Мбайт = 1024 Кбайт = 220 байт 1 Гбайт = 1024 Мбайт = 230 байт 1 Тбайт = 1024 Гбайт = 240
байт
Особо обратим внимание на то, что при переходе к более крупным единицам «инженерная» погрешность, связанная с округлением, накапливается и становится недопустимой, поэтому на старших единицах измерения округление производится реже.
Единицы хранения данных
При хранении данных решаются две проблемы: как сохранить данные в наиболее компактном виде и как обеспечить к ним удобный и быстрый доступ (если доступ не обеспечен, то это не хранение). Для обеспечения доступа необходимо, чтобы данные имели упорядоченную структуру, а при этом, как мы уже знаем, образуется «паразитная нагрузка» в виде адресных данных. Без них нельзя получить доступ к нужным элементам данных, входящих в структуру.
Поскольку адресные данные тоже имеют размер и тоже подлежат хранению, хранить данные в виде мелких единиц, таких, как байты, неудобно. Их неудобно хранить и в более крупных единицах (килобайтах, мегабайтах и т.
п.), поскольку неполное заполнение одной единицы хранения приводит к неэффективности хранения.
В качестве единицы хранения данных принят объект переменной длины, называемый файлом. Файл — это последовательность произвольного числа байтов, обладающая уникальным собственным именем. Обычно в отдельном файле хранят данные, относящиеся к одному типу. В этом случае тип данных определяет тип файла.
Проще всего представить себе файл в виде безразмерного канцелярского досье, в которое можно по желанию добавлять содержимое или извлекать его оттуда. Поскольку в определении файла нет ограничений на размер, можно представить себе файл, имеющий 0 байтов (пустой файл), и файл, имеющий любое число байтов.
В определении файла особое внимание уделяется имени. Оно фактически несет в себе адресные данные, без которых данные, хранящиеся в файле, не станут информацией из-за отсутствия метода доступа к ним. Кроме функций, связанных с адресацией, имя файла может хранить и сведения о типе данных, заключенных в нем. Для автоматических средств работы с данными это важно, поскольку по имени файла они могут автоматически определить адекватный метод извлечения информации из файла.
Понятие о файловой структуре
Требование уникальности имени файла очевидно — без этого невозможно гарантировать однозначность доступа к данным. В средствах вычислительной техники требование уникальности имени обеспечивается автоматически — создать файл с именем, тождественным уже имеющемуся, не может ни пользователь, ни автоматика.
Хранение файлов организуется в иерархической структуре, которая в данном случае называется файловой структурой. В качестве вершины структуры служит имя носителя, на котором сохраняются файлы. Далее файлы группируются в каталоги (папки), внутри которых могут быть созданы вложенные каталоги (папки). Путь доступа к файлу начинается с имени устройства и включает все имена каталогов (папок), через которые проходит. В качестве разделителя используется символ «\» (обратная косая черта).
Уникальность имени файла обеспечивается тем, что полным именем файла считается собственное имя файла вместе с путем доступа к нему. Понятно, что в этом случае на одном носителе не может быть двух файлов с тождественными полными именами.
Пример записи полного имени файла:
<имя носителя>\<имя каталога-1>\...\<имя каталога-М>\<собственное имя файла>
Вот пример записи двух файлов, имеющих одинаковое собственное имя и размещенных на одном носителе, но отличающихся путем доступа, то есть полным именем. Для наглядности имена каталогов (папок) напечатаны прописными буквами.
С:\АВТОМАТИЧЕСКИЕ АППАРАТЫ\ВЕНЕРА\АТМОСФЕРА\Результаты исследований
С:\РАДИОЛОКАЦИЯ\ВЕНЕРА\РЕЛЬЕФ\Результаты исследований
О том, как на практике реализуются файловые структуры, мы узнаем несколько позже, когда познакомимся со средствами вычислительной техники и с понятием файловой системы.
Файлы и папки Windows
Способ хранения файлов на дисках компьютера называется файловой системой. Иерархическая структура, в виде которой операционная система отображает файлы и папки диска, называется файловой структурой. Как все дисковые операционные системы, Windows 98 предоставляет средства для управления этой структурой.
Просмотр папок Windows
Откройте окно Мой компьютер и найдите в нем значок жесткого диска С:. Щелкните на нем дважды, и на экране откроется новое окно, в котором представлены значки объектов, присутствующих на жестком диске. Обратите внимание на значки, представляющие папки, и значки, представляющие файлы. Двойной щелчок на значке любой папки открывает ее окно и позволяет ознакомиться с содержимым. Так можно погружаться вглубь структуры папок до последнего уровня вложения. В соответствующем окне будут представлены только значки файлов.
Окно папки
Окно папки — это контейнер, содержимое которого графически отображает содержимое папки. Любую папку Windows можно открыть в своем окне. Количество одновременно открытых окон может быть достаточно большим — это зависит от параметров конкретного компьютера. Окна — одни из самых важных объектов Windows. Абсолютно все операции, которые мы делаем, работая с компьютером, происходят либо на Рабочем столе, либо в каком-либо окне.
Окна папок — не единственный тип окон в Windows. По наличию однородных элементов управления и оформления можно выделить и другие типы окон: диалоговые окна, окна справочной системы и рабочие окна приложений, а внутри окон многих приложений могут существовать отдельные окна документов (если приложение позволяет работать с несколькими документами одновременно).
Структура окна
На рис. 5.2 представлено окно папки C:\Windows.
Такая папка имеется на компьютерах, работающих в операционной системе Windows 98. Окно папки содержит следующие обязательные элементы.

Рис. 5.2. Окно папки C:\Windows
Строка заголовка — в ней написано название папки. За эту строку выполняется перетаскивание папки на Рабочем столе с помощью мыши.
Системный значок. Находится в левом верхнем углу любого окна папки. При щелчке на этом значке открывается меню, называемое служебным. Команды, представленные в данном меню, позволяют управлять размером и расположением окна на Рабочем столе — они могут быть полезны, если мышь не работает.
Кнопки управления размером. Эти кнопки дублируют основные команды служебного меню. В операционной системе Windows 98 исключительно много дублирования. Большинство операций можно выполнить многими различными способами. Каждый пользуется теми приемами, которые ему удобны. Кнопок управления размером три: закрывающая, сворачивающая, разворачивающая.
Щелчок на закрывающей кнопке закрывает окно полностью (и прекращает процесс). Щелчок на сворачивающей кнопке приводит к тому, что окно сворачивается до размера кнопки, которая находится на Панели задач (при этом процесс, связанный с окном, не прекращается). В любой момент окно можно восстановить щелчком на кнопке Панели задач.
Щелчок на разворачивающей кнопке разворачивает окно на полный экран. При этом работать с ним удобно, но доступ к прочим окнам затрудняется. В развернутом окне разворачивающая кнопка сменяется восстанавливающей, с помощью которой можно восстановить исходный размер окна.
Строка меню. Для окон папок строка меню имеет стандартный вид. При щелчке на каждом из пунктов этого меню открывается «ниспадающее» меню, пункты которого позволяют проводить операции с содержимым окна или с окном в целом.
Использование команд, доступных через строку меню, в большинстве случаев — не самый эффективный прием работы в Windows (есть и более удобные элементы и средства управления), но зато строка меню гарантированно предоставляет доступ ко всем командам, которые можно выполнить в данном окне.
Это удобно, если неизвестно, где находится нужный элемент управления. Поэтому при изучении работы с новым приложением в первое время принято пользоваться командами строки меню и лишь потом переходить к использованию других средств управления, постепенно повышая эффективность работы.
Панель инструментов. Содержит командные кнопки для выполнения наиболее часто встречающихся операций. В работе удобнее, чем строка меню, но ограничена по количеству команд. В окнах современных приложений панель инструментов часто бывает настраиваемой. Пользователь сам может разместить на ней те командные кнопки, которыми он пользуется наиболее часто.
Адресная строка. В ней указан путь доступа к текущей папке, что удобно для ориентации в файловой структуре. Адресная строка позволяет выполнить быстрый переход к другим разделам файловой структуры с помощью раскрывающей кнопки на правом краю строки.
Рабочая область. В ней отображаются значки объектов, хранящихся в папке, причем способом отображения можно управлять (см. ниже). В окнах приложений в рабочей области размещаются окна документов и рабочие панели.
Полосы прокрутки. Если количество объектов слишком велико (или размер окна слишком мал), по правому и нижнему краям рабочей области могут отображаться полосы прокрутки, с помощью которых можно «прокручивать» содержимое папки в рабочей области.
Полоса прокрутки имеет движок и две концевые кнопки. Прокрутку выполняют тремя способами:
• щелчком на одной из концевых кнопок;
• перетаскиванием движка;
• щелчком на полосе прокрутке выше или ниже движка.
Строка состояния. Здесь выводится дополнительная, часто немаловажная информация. Так, например, если среди объектов, представленных в окне, есть скрытые или системные, они могут не отображаться при просмотре, но в строке состояния об их наличии имеется специальная запись.
Автоматизация обработки документов
Компьютер предназначен для работы с документами, имеющими электронную форму. В то же время, нам часто приходится иметь дело с бумажными изданиями и документами: журналами, книгами, письмами, служебными записками и т. д. Чтобы в работе с информацией такого рода тоже можно было использовать компьютер, необходимы средства преобразования бумажных документов в электронную форму.
Если предполагается, что документ содержит в основном текстовую информацию, то можно выделить следующие основные этапы такого преобразования:
• в ходе сканирования при помощи устройств оцифровки изображения производится создание электронного образа (изображения) документа;
• процесс распознавания позволяет преобразовать электронноеизображение в текстовые данные (с сохранением элементов форматирования оригинала или без них);
• для документов, исполненных на иностранном языке применяют дополнитель ные средства автоматизированного перевода на другой язык.
Функции операционных систем персональных компьютеров
Операционная система представляет комплекс системных и служебных программных средств. С одной стороны, она опирается на базовое программное обеспечение компьютера, входящее в его систему ВIOS (базовая система ввода-вывода), с другой стороны, она сама является опорой для программного обеспечения более высоких уровней — прикладных и большинства служебных приложений. Приложениями операционной системы принято называть программы, предназначенные для работы под управлением данной системы.
Основная функция всех операционных систем — посредническая. Она заключаются в обеспечении нескольких видов интерфейса:
интерфейса между пользователем и программно-аппаратными средствами компьютера (интерфейс пользователя);
интерфейса между программным и аппаратным обеспечением (аппаратно-программный интерфейс);
интерфейса между разными видами программного обеспечения (программный интерфейс).
Даже для одной аппаратной платформы, например такой, как IBM PC, существует несколько операционных систем. Различия между ними рассматривают в двух категориях: внутренние и внешние. Внутренние различия характеризуются методами реализации основных функций. Внешние различия определяются наличием и доступностью приложений данной системы, необходимых для удовлетворения технических требований, предъявляемых к конкретному рабочему месту.
Обработка данных средствами электронных таблиц Excel
Программа Microsoft Excel предназначена для работы с таблицами данных, преимущественно числовых. При формировании таблицы выполняют ввод, редактирование и форматирование текстовых и числовых данных, а также формул. Наличие средств автоматизации облегчает эти операции. Созданная таблица может быть выведена на печать.
Основные понятия электронных таблиц
Документ Excel называется рабочей книгой. Рабочая книга представляет собой набор рабочих листов, каждый из которых имеет табличную структуру и может содержать одну или несколько таблиц. В окне документа в программе Excel отображается только текущий рабочий лист, с которым и ведется работа (рис.12.2). Каждый рабочий лист имеет название, которое отображается на. ярлычке листа, отображаемом в его нижней части. С помощью ярлычков можно переключаться к другим рабочим листам, входящим в ту же самую рабочую книгу. Чтобы переименовать рабочий лист, надо дважды щелкнуть на его ярлычке.
Рабочий лист состоит из строк и столбцов. Столбцы озаглавлены прописными латинскими буквами и, далее, двухбуквенными комбинациями. Всего рабочий лист может содержать до 256 столбцов, пронумерованных от А до IV. Строки последовательно нумеруются цифрами, от 1 до 65 536 (максимально допустимый номер строки).
Ячейки и их адресация. На пересечении столбцов и строк образуются ячейки таблицы. Они являются минимальными элементами для хранения данных. Обозначение отдельной ячейки сочетает в себе номера столбца и строки (в этом порядке), на пересечении которых она расположена, например: А1 или DE234. Обозначение ячейки (ее номер) выполняет функции ее адреса. Адреса ячеек используются при записи формул, определяющих взаимосвязь между значениями, расположенными в разных ячейках.
Одна из ячеек всегда является активной и выделяется рамкой активной ячейки. Эта рамка в программе Excel играет роль курсора. Операции ввода и редактирования всегда производятся в активной ячейке. Переместить рамку активной ячейки можно с помощью курсорных клавиш или указателя мыши.

Рис. 12.2. Рабочий лист электронной таблицы Excel
Диапазон ячеек. На данные, расположенные в соседних ячейках, можно ссылаться в формулах, как на единое целое. Такую группу ячеек называют диапазоном. Наиболее часто используют прямоугольные диапазоны, образующиеся на пересечении группы последовательно идущих строк и группы последовательно идущих столбцов. Диапазон ячеек обозначают, указывая через двоеточие номера ячеек, расположенных в противоположных углах прямоугольника, например: А1; С15.
Если требуется выделить прямоугольный диапазон ячеек, это можно сделать протягиванием указателя от одной угловой ячейки до противоположной по диагонали. Рамка текущей ячейки при этом расширяется, охватывая весь выбранный диапазон. Чтобы выбрать столбец или строку целиком, следует щелкнуть на заголовке столбца (строки). Протягиванием указателя по заголовкам можно выбрать несколько идущих подряд столбцов или строк.
Ввод, редактирование и форматирование данных
Отдельная ячейка может содержать данные, относящиеся к одному из трех типов; текст, число или формула, — а также оставаться пустой. Программа Excel при сохранении рабочей книги записывает в файл только прямоугольную область рабочих листов, примыкающую к левому верхнему углу (ячейка А1) и содержащую все заполненные ячейки.
Тип данных, размещаемых в ячейке, определяется автоматически при вводе. Если эти данные можно интерпретировать как число, программа Excel так и делает. В противном случае данные рассматриваются как текст. Ввод формулы всегда начинается с символа «=» (знака равенства).
Ввод текста и чисел. Ввод данных осуществляют непосредственно в текущую ячейку или в строку формул, располагающуюся в верхней части окна программы непосредственно под панелями инструментов (см. рис. 12.2). Место ввода отмечается текстовым курсором. Если начать ввод нажатием алфавитно-цифровых клавиш, данные из текущей ячейки заменяются вводимым текстом. Если щелкнуть на строке формул или дважды на текущей ячейке, старое содержимое ячейки не удаляется и появляется возможность его редактирования.
Вводимые данные в любом случае отображаются как в ячейке, так и в строке формул.
Чтобы завершить ввод, сохранив введенные данные, используют кнопку Enter в строке формул или клавишу ENTER. Чтобы отменить внесенные изменения и восстановить прежнее значение ячейки, используют кнопку Отмена в строке формул или клавишу ESC. Для очистки текущей ячейки или выделенного диапазона проще всего использовать клавишу DELETE.
Форматирование содержимого ячеек. Текстовые данные по умолчанию выравниваются по левому краю ячейки, а числа — по правому. Чтобы изменить формат отображения данных в текущей ячейке или выбранном диапазоне, используют команду Формат > Ячейки. Вкладки этого диалогового окна позволяют выбирать формат записи данных (количество знаков после запятой, указание денежной единицы, способ записи даты и прочее), задавать направление текста и метод его выравнивания, определять шрифт и начертание символов, управлять отображением и видом рамок, задавать фоновый цвет.
Вычисления в электронных таблицах
Формулы. Вычисления в таблицах программы Excel осуществляются при помощи формул. Формула может содержать числовые константы, ссылки на ячейки и функции Excel, соединенные знаками математических операций. Скобки позволяют изменять стандартный порядок выполнения действий. Если ячейка содержит формулу, то в рабочем листе отображается текущий результат вычисления этой формулы. Если сделать ячейку текущей, то сама формула отображается в строке формул.
Правило использования формул в программе Excel состоит в том, что, если значение ячейки действительно зависит от других ячеек таблицы, всегда следует использовать формулу, даже если операцию легко можно выполнить в «уме». Это гарантирует, что последующее редактирование таблицы не нарушит ее целостности и правильности производимых в ней вычислений.
Ссылки на ячейки. Формула может содержать ссылки, то есть адреса ячеек, содержимое которых используется в вычислениях. Это означает, что результат вычисления формулы зависит от числа, находящегося в другой ячейке.
Ячейка, содержащая формулу, таким образом, является зависимой. Значение, отображаемое в ячейке с формулой, пересчитывается при изменении значения ячейки, на которую указывает ссылка.
Ссылку на ячейку можно задать разными способами. Во-первых, адрес ячейки можно ввести вручную. Другой способ состоит в щелчке на нужной ячейке или выборе диапазона, адрес которого требуется ввести. Ячейка или диапазон при этом выделяются пунктирной рамкой.
Все диалоговые окна программы Excel, которые требуют указания номеров или диапазонов ячеек, содержат кнопки, присоединенные к соответствующим полям. При щелчке на такой кнопке диалоговое окно сворачивается до минимально возможного размера, что облегчает выбор нужной ячейки (диапазона) с помощью щелчка или протягивания (рис. 12.3).
Рис. 12.3. Диалоговое окно в развернутом и свернутом виде
Для редактирования формулы следует дважды щелкнуть на соответствующей ячейке. При этом ячейки (диапазоны), от которых зависит значение формулы, выделяются на рабочем листе цветными рамками, а сами ссылки отображаются в ячейке и в строке формул тем же цветом. Это облегчает редактирование и проверку правильности формул.
Абсолютные и относительные ссылки. По умолчанию, ссылки на ячейки в формулах рассматриваются как относительные. Это означает, что при копировании формулы адреса в ссылках автоматически изменяются в соответствии с относительным расположением исходной ячейки и создаваемой копии.
Пусть, например, в ячейке В2 имеется ссылка на ячейку A3. В относительном представлении можно сказать, что ссылка указывает на ячейку, которая располагается на один столбец левее и на одну строку ниже данной. Если формула будет скопирована в другую ячейку, то такое относительное указание ссылки сохранится. Например, при копировании формулы в ячейку ЕА27 ссылка будет продолжать указывать на ячейку, располагающуюся левее и ниже, в данном случае на ячейку DZ28.
При абсолютной адресации адреса ссылок при копировании не изменяются, так что ячейка, на которую указывает ссылка, рассматривается как нетабличная.
Для изменения способа адресации при редактировании формулы надо выделить ссылку на ячейку и нажать клавишу F4. Элементы номера ячейки, использующие абсолютную адресацию, предваряются символом $. Например, при последовательных нажатиях клавиши F4 номер ячейки А1 будет записываться как А1, $А$ 1, А$ 1 и $А1. В двух последних случаях один из компонентов номера ячейки рассматривается как абсолютный, а другой — как относительный.
Копирование содержимого ячеек
Копирование и перемещение ячеек в программе Excel можно осуществлять методом перетаскивания или через буфер обмена. При работе с небольшим числом ячеек удобно использовать первый метод, при работе с большими диапазонами — второй.
Метод перетаскивания. Чтобы методом перетаскивания скопировать или переместить текущую ячейку (выделенный диапазон) вместе с содержимым, следует навести указатель мыши на рамку текущей ячейки (он примет вид стрелки). Теперь ячейку можно перетащить в любое место рабочего листа (точка вставки помечается всплывающей подсказкой).
Для выбора способа выполнения этой операции, а также для более надежного контроля над ней рекомендуется использовать специальное перетаскивание с помощью правой кнопки мыши. В этом случае при отпускании кнопки мыши появляется специальное меню, в котором можно выбрать конкретную выполняемую операцию.
Применение буфера обмена. Передача информации через буфер обмена имеет в програмее Excel определенные особенности, связанные со сложностью контроля над этой операцией. Вначале необходимо выделить копируемый (вырезаемый) диапазон и дать команду на его помещение в буфер обмена: Правка > Копировать или Правка > Вырезать. Вставка данных в рабочий лист возможна лишь немедленно после их помещения в буфер обмена. Попытка выполнить любую другую операцию приводит к отмене начатого процесса копирования или перемещения. Однако утраты данных не происходит, поскольку «вырезанные» данные удаляются из места их исходного размещения только в момент выполнения вставки.
Место вставки определяется путем указания ячейки, соответствующей верхнему левому углу диапазона, помещенного в буфер обмена, или путем выделения диапазона, который по размерам в точности равен копируемому (перемещаемому).
Вставка выполняется командой Правка > Вставить. Для управления способом вставки можно использовать команду Правка > Специальная вставка. В этом случае правила вставки данных из буфера обмена задаются в открывшемся диалоговом окне.
Автоматизация ввода
Так как таблицы часто содержат повторяющиеся или однотипные данные, программа Excel содержит средства автоматизации ввода. К числу предоставляемых средств относятся: автозавершение, автозаполнение числами и автозаполнение формулами.
Автозавершение. Для автоматизации ввода текстовых данных используется метод автозавершения. Его применяют при вводе в ячейки одного столбца рабочего листа текстовых строк, среди которых есть повторяющиеся. В ходе ввода текстовых данных в очередную ячейку программа Excel проверяет соответствие введенных символов строкам, имеющемся в этом столбце выше. Если обнаружено однозначное совпадение, введенный текст автоматически дополняется. Нажатие клавиши ENTER подтверждает операцию автозавершения, в противном случае ввод можно продолжать, не обращая внимания на предлагаемый вариант.
Можно прервать работу средства автозавершения, оставив в столбце пустую ячейку. И наоборот, чтобы использовать возможности средства автозавершения, заполненные ячейки должны идти подряд, без промежутков между ними.
Автозаполнение числами. При работе с числами используется метод автозаполнения. В правом нижнем углу рамки текущей ячейки имеется черный квадратик — маркер заполнения. При наведении на него указатель мыши (он обычно имеет вид толстого белого креста) приобретает форму тонкого черного крестика. Перетаскивание маркера заполнения рассматривается как операция «размножения» содержимого ячейки в горизонтальном или вертикальном направлении.
Если ячейка содержит число (в том числе дату, денежную сумму), то при перетаскивании маркера происходит копирование ячеек или их заполнение арифметической прогрессией. Для выбора способа автозаполнения следует производить специальное перетаскивание с использованием правой кнопки мыши.
Пусть, например, ячейка А1 содержит число 1. Наведите указатель мыши на маркер заполнения, нажмите правую кнопку мыши, и перетащите маркер заполнения так, чтобы рамка охватила ячейки А1, В1 и С1, и отпустите кнопку мыши. Если теперь выбрать в открывшемся меню пункт Копировать ячейки, все ячейки будут содержать число 1. Если же выбрать пункт Заполнить, то в ячейках окажутся числа 1,2 и 3.
Чтобы точно сформулировать условия заполнения ячеек, следует дать команду Правка > Заполнить > Прогрессия. В открывшемся диалоговом окне Прогрессия выбирается тип прогрессии, величина шага и предельное значение. После щелчка на кнопке ОК программа Excel автоматически заполняет ячейки в соответствии с заданными правилами.
Автозаполнение формулами. Эта операция выполняется так же, как автозаполнение числами. Ее особенность заключается в необходимости копирования ссылок на другие ячейки. В ходе автозаполнения во внимание принимается характер ссылок в формуле: относительные ссылки изменяются в соответствии с относительным расположением копии и оригинала, абсолютные остаются без изменений.
Для примера предположим, что значения в третьем столбце рабочего листа (столбце С) вычисляются как суммы значений в соответствующих ячейках столбцов А и В. Введем в ячейку С1 формулу =А1 +В1. Теперь скопируем эту формулу методом автозаполнения во все ячейки третьего столбца таблицы. Благодаря относительной адресации формула будет правильной для всех ячеек данного столбца.
В таблице 12.1 приведены правила обновления ссылок при автозаполнении вдоль строки или вдоль столбца.
Таблица 12.1.
Правила обновления ссылок при автозаполнении
|
Ссылка в исходной ячейке |
Ссылка в следующей ячейке |
|
|
При заполнении вправо |
При заполнении вниз |
|
|
А1 (относительная) |
В1 |
А2 |
|
$А1 (абсолютная по столбцу) |
$А1 |
$А2 |
|
А$1 (абсолютная по строке) |
В$1 |
А$1 |
|
$А$1 (абсолютная) |
$А$1 |
$А$1 |
Использование стандартных функций
Стандартные функции используются в программе Excel только в формулах. Вызов функции состоит в указании в формуле имени функции, после которого в скобках указывается список параметров. Отдельные параметры разделяются в списке точкой с запятой.
В качестве параметра может использоваться число, адрес ячейки или произвольное выражение, для вычисления которого также могут использоваться функции.
Палитра формул. Если начать ввод формулы щелчком на кнопке Изменить формулу в строке формул, под строкой формул появляется палитра формул, обладающая своствами диалогового окна (рис. 12.4). Она содержит значение, которое получится, если немедленно закончить ввод формулы. В левой части строки формул, где раньше располагался номер текущей ячейки, теперь появляется раскрывающийся список функций. Он содержит десять функций, которые использовались последними, а также пункт Другие функции.
Использование мастера функций. При выборе пункта Другие функции запускается Мастер функций, облегчающий выбор нужной функции. В списке Категория выбирается категория, к которой относится функция (если определить категорию затруднительно, используют пункт Полный алфавитный перечень), а в списке Функция — конкретная функция данной категории. После щелчка на кнопке ОК имя функции заносится в строку формул вместе со скобками, ограничивающими список параметров. Текстовый курсор устанавливается между этими скобками.

Рис. 12.4. Строка формул и палитра формул
Ввод параметров функции. В ходе ввода параметров функции палитра формул изменяет вид. На ней отображаются поля, предназначенные для ввода параметров. Если название параметра указано полужирным шрифтом, параметр является обязательным и соответствующее поле должно быть заполнено. Параметры, названия которых приводятся обычным шрифтом, можно опускать. В нижней части палитры приводится краткое описание функции, а также назначение изменяемого параметра.
Параметры можно вводить непосредственно в строку формул или в поля палитры формул, а если они являются ссылками — выбирать на рабочем листе. Если параметр задан, в палитре формул указывается его значение, а для опущенных параметров — значения, принятые по умолчанию. Здесь можно также увидеть значение функции, вычисленное при заданных значениях параметров (см.
рис.12.4).
Правила вычисления формул, содержащих функции, не отличаются от правил вычисления более простых формул. Ссылки на ячейки, используемые в качестве параметров функции, также могут быть относительными или абсолютными, что учитывается при копировании формул методом автозаполнения.
Печать документов Excel
Экранное представление электронной таблицы в Excel значительно отличается от того, которое получилось бы при выводе данных на печать. Это связано с тем, что единый рабочий лист приходится разбивать на фрагменты, размер которых определяется форматом печатного листа. Кроме того, элементы оформления рабочего окна программы: номера строк и столбцов, условные границы ячеек — обычно не отображаются при печати.
Предварительньй просмотр. Перед печатью рабочего листа следует перейти в режим предварительного просмотра (кнопка Предварительный просмотр на стандартной панели инструментов). Режим предварительного просмотра (рис.12.5) не допускает редактирования документа, но позволяет увидеть его на экране точно в таком виде, в каком он будет напечатан. Кроме того, режим предварительного просмотра позволяет изменить свойства печатной страницы и параметры печати.

Рис. 12.5. Предварительный просмотр документа перед печатью
Управление в режиме предварительного просмотра осуществляется при помощи кнопок, расположенных вдоль верхнего края окна. Кнопка Страница открывает диалоговое окно Параметры страницы, которое служит для задания параметров страницы: ориентации листа, масштаба страницы (изменение масштаба позволяет управлять числом печатных страниц, необходимых для документа), размерами полей документа. Здесь же можно задать верхние и нижние колонтитулы для страницы. На вкладке Лист включается или отключается печать сетки и номеров строк и столбцов, а также выбирается последовательность разбиения на страницы рабочего листа, превосходящего размеры печатной страницы как по длине, так и по ширине.
Изменить величину полей страницы, а также ширину ячеек при печати можно также непосредственно в режиме предварительного просмотра, при помощи кнопки Поля.
При щелчке на этой кнопке на странице появляются маркеры, указывающие границы полей страницы и ячеек. Изменить положение этих границ можно методом перетаскивания.
Завершить работу в режиме предварительного просмотра можно тремя способами, в зависимости от того, что планируется делать дальше. Щелчок на кнопке Закрыть позволяет вернуться к редактированию документа. Щелчок на кнопке Разметка страницы служит для возврата к редактированию документа, но в режиме разметки страницы. В этом режиме документ отображается таким образом, чтобы наиболее удобно показать не содержимое ячеек таблицы, а область печати и границы страниц документа. Переключение между режимом разметки и обычным режимом можно также осуществлять через меню Вид (команды Вид > Обычный и Вид > Разметка страницы). Третий способ — начать печать документа.
Печать документа. Щелчок на кнопке Печать открывает диалоговое окно Печать, используемое для распечатки документа (его можно открыть и без предварительного просмотра — с помощью команды Файл > Печать). Это окно содержит стандартные средства управления, применямые для печати документов в любых приложениях.
Выбор области печати. Область печати — эта часть рабочего листа, которая должна быть выведена на печать. По умолчанию область печати совпадает с заполненной частью рабочего листа и представляет собой прямоугольник, примыкающий к верхнему левому углу рабочего листа и захватывающий все заполненные ячейки. Если часть данных не должна выводиться на бумагу, область печати можно задать вручную. Для этого надо выделить ячейки, которые должны быть включены в область печати, и дать команду Файл > Область печати > Задать. Если текущей является одна-единственная ячейка, то программа предполагает, что область печати просто не выделена, и выдает предупреждающее сообщение.
Если область печати задана, то программа отображает в режиме предварительного просмотра и распечатывает только ее. Границы области печати выделяются на рабочем листе крупным пунктиром (сплошной линией в режиме разметки).Для изменения области печати можно задать новую область или при помощи команды Файл > Область печати > Убрать вернуться к параметрам, используемым по умолчанию.
Границы отдельных печатных страниц отображаются на рабочем листе мелким пунктиром. В некоторых случаях требуется, чтобы определенные ячейки располагались вместе на одной и той же печатной странице или, наоборот, разделение печатных страниц происходило в определенном месте рабочего листа. Такая возможность реализуется путем задания границ печатных страниц вручную. Чтобы вставить разрыв страницы, надо сделать текущей ячейку, которая будет располагаться в левом верхнем углу печатной страницы, и дать команду Вставка > Разрыв страницы. Программа Excel вставит принудительные разрывы страницы перед строкой и столбцом, в которых располагается данная ячейка. Если выбранная ячейка находится в первой строке или столбце А, то разрыв страницы задается только по одному направлению.
Основы программирования
Компьютерные программы создают программисты — люди, обученные процессу их составления (программированию). Мы знаем, что программа — это логически упорядоченная последовательность команд, необходимых для управления компьютером (выполнения им конкретных операций), поэтому программирование сводится к созданию последовательности команд, необходимой для решения определенной задачи.
Основы работы операционной системы WINDOWS
В предыдущей главе мы рассмотрели функции ряда операционных систем и требования к ним. Надо сказать, что многие из этих требований являются противоречивыми. Например, соотношение требований безотказности и совместимости с приложениями иных систем — это вопрос баланса. Соотношение требований безопасности и простоты обеспечения сетевых функций — это тоже вопрос баланса. На каждом конкретном рабочем месте эти вопросы решаются индивидуально.
В этом смысле сегодня особое место занимает операционная система Windows 98. Она обладает наибольшей универсальностью, имеет самое широкое распространение и, соответственно, имеет особую поддержку со стороны производителей аппаратного и программного обеспечения. Для компьютера, работающего в этой системе, наиболее просто подобрать прикладные программы и драйверы устройств.
Почти все, что здесь сказано об операционной системе Windows 98, можно отнести и к операционной системе Windows 95, а многое справедливо и для Windows NT. В том, что касается приемов и методов работы, они в значительной степени совпадают.
Приемы и методы работы со сжатыми жанными
Как хранение, так и передача информации обходятся участникам информационного процесса недешево. Зная стоимость носителя и его емкость (Мбайт, Гбайт), нетрудно подсчитать, во что обходится хранение единицы информации, а зная пропускную способность канала связи (Мбит/с) и стоимость его аренды, можно определить затраты на передачу единицы информации. Полученные результаты обычно составляют вполне значимые величины как для корпоративных пользователей, так и для индивидуальных. В связи с этим, регулярно возникает необходимость сжимать данные перед тем, как размещать их в архивах или передавать по каналам связи. Соответственно, существует и обратная необходимость восстановления данных из предварительно уплотненных архивов.
Публикация WEB-документов
Размещение собственных материалов в Интернете включает два этапа: подготовку материалов и их публикацию. Подготовка материалов состоит в создании документов, имеющих формат, принятый в Интернете, то есть, Web-страниц, написанных на языке HTML Публикация материалов, то есть открытие к ним доступа, осуществляется после решения организационных вопросов, связанных с получением дискового пространства на Web-сервере для их размещения.
Создание комплексных текстовых документов
В предыдущей главе мы рассмотрели приемы создания простых текстовых документов средствами текстового процессора Microsoft Word. К условной категории простых эти документы бьии отнесены только потому, что не содержали объектов, встроенных в текст. Соответственно, нами не были рассмотрены вопросы взаимодействия текста и встроенных объектов.
В этой главе мы рассмотрим приемы создания комплексных текстовых документов, содержащих специальные элементы оформления и встроенные объекты нетекстовой природы (формулы, таблицы, диаграммы, художественные заголовки, растровые и векторные иллюстрации, а также объекты мультимедиа).
Создание простых текстовых документов
В этой и следующей главах рассматриваются понятия, методы и приемы, относящиеся к созданию текстовых документов с помощью персонального компьютера. Условно (из чисто методических соображений) мы выделим две группы создаваемых документов — простые и комплексные. Первые представляют собой форматированный текст, а вторые содержат кроме текста объекты иной природы (чертежи, рисунки, формулы, таблицы, объекты мультимедиа и прочие).
Стандартные приложения Windows
Основное назначение операционных систем — обеспечение взаимодействия человека, оборудования и программ. От операционных систем не требуется наличия средств, предназначенных для исполнения конкретных прикладных задач, — для этого есть прикладное программное обеспечение. Тем не менее, в операционную систему Windows 98 входит ограниченный набор прикладных программ, с помощью которых можно решать некоторые простейшие повседневные задачи, пока на компьютере не установлены более мощные программные средства. Такие программы, входящие в поставку Windows, называют стандартными приложениями. В силу особой простоты их принято также рассматривать в качестве учебных. Знание приемов работы со стандартными приложениями позволяет ускорить освоение специализированных программных средств.
Информация в материальном мире
Сигналы и данные
Мы живем в материальном мире. Все, что нас окружает и с чем мы сталкиваемся ежедневно, относится либо к физическим телам, либо к физическим полям. Из курса физики мы знаем, что состояния абсолютного покоя не существует и физические объекты находятся в состоянии непрерывного движении и изменения, которое сопровождается обменом энергией и ее переходом из одной формы в другую.
Все виды энергообмена сопровождаются появлением сигналов, то есть, все сигналы имеют в своей основе материальную энергетическую природу. При взаимодействии сигналов с физическими телами в последних возникают определенные изменения свойств — это явление называется регистрацией сигналов. Такие изменения можно наблюдать, измерять или фиксировать иными способами — при этом возникают и регистрируются новые сигналы, то есть, образуются данные.
Данные — это зарегистрированные сигналы.
Данные и методы
Обратим внимание на то, что данные несут в себе информацию о событиях, произошедших в материальном мире, поскольку они являются регистрацией сигналов, возникших в результате этих событий. Однако данные не тождественны информации. Наблюдая излучения далеких звезд, человек получает определенный поток данных, но станут ли эти данные информацией, зависит еще от очень многих обстоятельств. Рассмотрим ряд примеров.
Наблюдая за состязаниями бегунов, мы с помощью механического секундомера регистрируем начальное и конечное положение стрелки прибора. В итоге мы замеряем величину ее перемещения за время забега — это регистрация данных. Однако информацию о времени преодоления дистанции мы пока не получаем. Для того чтобы данные о перемещении стрелки дали информацию о времени забега, необходимо наличие метода пересчета одной физической величины в другую. Надо знать цену деления шкалы секундомера (или знать метод ее определения) и надо также знать, как умножается цена деления прибора на величину перемещения, то есть надо еще обладать математическим методом умножения.
Если вместо механического секундомера используется электронный, суть дела не меняется.
Вместо регистрации перемещения стрелки происходит регистрация количества тактов колебаний, произошедших в электронной системе за время измерения. Даже если секундомер непосредственно отображает время в секундах и нам не нужен метод пересчета, то метод преобразования данных все равно присутствует — он реализован специальными электронными компонентами и работает автоматически, без нашего участия.
Прослушивая передачу радиостанции на незнакомом языке, мы получаем данные, но не получаем информацию в связи с тем, что не владеем методом преобразования данных в известные нам понятия. Если эти данные записать на лист бумаги или на магнитную ленту, изменится форма их представления, произойдет новая регистрация и, соответственно, образуются новые данные. Такое преобразование можно использовать, чтобы все-таки извлечь информацию из данных путем подбора метода, адекватного их новой форме. Для обработки данных, записанных на листе бумаги, адекватным может быть метод перевода со словарем, а для обработки данных, записанных на магнитной ленте, можно пригласить переводчика, обладающего своими методами перевода, основанными на знаниях, полученных в результате обучения или предшествующего опыта.
Если в нашем примере заменить радиопередачу телевизионной трансляцией, ведущейся на незнакомом языке, то мы увидим, что наряду с данными мы все-таки получаем определенную (хотя и не полную) информацию. Это связано с тем, что люди, не имеющие дефектов зрения, априорно владеют адекватным методом восприятия данных, передаваемых электромагнитным сигналом в полосе частот видимого спектра с интенсивностью, превышающей порог чувствительности глаза. В таких случаях говорят, что метод известен по контексту, то есть данные, составляющие информацию, имеют свойства, однозначно определяющие адекватный метод получения этой информации. (Для сравнения скажем, что слепому «телезрителю» контекстный метод неизвестен, и он оказывается в положении радиослушателя, пример с которым был рассмотрен выше.)
Понятие об информации
Несмотря на то что с понятием информации мы сталкиваемся ежедневно, строгого и общепризнанного ее определения до сих пор не существует, поэтому вместо определения обычно используют понятие об информации. Понятия, в отличие от определений, не даются однозначно, а вводятся на примерах, причем каждая научная дисциплина делает это по-своему, выделяя в качестве основных компонентов те, которые наилучшим образом соответствуют ее предмету и задачам. При этом типична ситуация, когда понятие об информации, введенное в рамках одной научной дисциплины, может опровергаться конкретными примерами и фактами, полученными в рамках другой науки. Например, представление об информации как о совокупности данных, повышающих уровень знаний об объективной реальности окружающего мира, характерное для естественных наук, может быть опровергнуто в рамках социальных наук. Нередки также случаи, когда исходные компоненты, составляющие понятие информации, подменяют свойствами информационных объектов, например, когда понятие информации вводят как совокупность данных, которые «могут быть усвоены и преобразованы в знания».
Для информатики как технической науки понятие информации не может основываться на таких антропоцентрических понятиях, как знание, и не может опираться только на объективность фактов и свидетельств. Средства вычислительной техники обладают способностью обрабатывать информацию автоматически, без участия человека, и ни о каком знании или незнании здесь речь идти не может. Эти средства могут работать с искусственной, абстрактной и даже с ложной информацией, не имеющей объективного отражения ни в природе, ни в обществе.
В этой работе мы даем новое определение информации, основанное на ранее продемонстрированном факте взаимодействия данных и методов в момент ее образования.
Информация — это продукт взаимодействия данных и адекватных им методов.
Поскольку в такой форме определение информации дается впервые, читатель приглашается для его всесторонней проверки в рамках других известных ему научных дисциплин, а мы рассмотрим пример, в свое время использованный Норбертом Винером для того, чтобы показать, как информация отдельных членов популяции становится информацией общества.
Допустим, я нахожусь в лесах вдвоем со смышленым дикарем, который не может говорить на моем языке и на языке которого я тоже не могу говорить. Даже без какого -либо условного языка знаков, известного нам обоим, я могу многое узнать от него. Мне нужно лишь быть особо внимательным в те моменты, когда он обнаруживает признаки волнения или интереса. Тогда я должен посмотреть вокруг, особенно в направлении его взгляда, и запомнить все, что я увижу и услышу. Не пройдет много времени, как я открою, какие предметы представляются важными для него, — не потому, что он сообщил мне о них словами, но потому, что я сам их заметил. Иначе говоря, сигнал, лишенный внутреннего содержания, может приобрести для моего спутника смысл по тому, что наблюдает он в данный момент, и может приобрести для меня смысл по тому, что наблюдаю я в данный момент. Способность дикаря замечать моменты моего особенно активного внимания сама по себе образует язык, возможности которого столь же разнообразны, как и диапазон впечатлений, доступных нам обоим.
Н. Винер. Кибернетика
Анализируя этот пример, мы видим, что здесь речь идет о данных и методах. Прежде всего, здесь автор прямо говорит о целой группе методов, связанных с наблюдением и анализом, и даже приводит вариант конкретного алгоритма, адекватного рамкам его гипотетического эксперимента (посмотреть, запомнить, открыть...). Автор неоднократно подчеркивает требование адекватности метода (дикарь должен быть смышленным, а наблюдатель должен быть особо внимательным), без которого информация может и не образоваться.

Рис. 1.1. Связь между данными и информацией
Диалектическое единство данных и методов в информационном
процессе
Рассмотрим данное выше определение информации и обратим внимание на следующие обстоятельства.
1.Динамический характер информации. Информация не является статичным объектом — она динамически меняется и существует только в момент взаимодействия данных и методов. Все прочее время она пребывает в состоянии данных.
Таким образом, информация существует только в момент протекания информационного процесса. Все остальное время она содержится в виде данных.
2.Требование адекватности методов. Одни и те же данные могут в момент потребления поставлять разную информацию в зависимости от степени адекватности взаимодействующих с ними методов. Например для человека, не владеющего китайским языком, письмо, полученное из Пекина, дает только ту информацию, которую можно получить методом наблюдения (количество страниц, цвет и сорт бумаги, наличие незнакомых символов и т. п.). Все это информация, ноэто не вся информация, заключенная в письме. Использование более адекватныхметодов даст иную информацию.
3.Диалектический характер взаимодействия данных и методов. Обратим внимание на то, что данные являются объективными, поскольку это результат регистрации объективно существовавших сигналов, вызванных изменениями в материальных телах или полях. В то же время, методы являются субъективными. В основе искусственных методов лежат алгоритмы (упорядоченные последовательности команд), составленные и подготовленные людьми (субъектами). В основе естественных методов лежат биологические свойства субъектов информационного процесса. Таким образом, информация возникает и существует в момент диалектического взаимодействия объективных данных и субъективных методов.
Такой дуализм известен своими проявлениями во многих науках. Так, например, в основе важнейшего вопроса философии о первичности материалистического и идеалистического подходов к теории познания лежит не что иное, как двойственный характер информационного процесса. В обоснованиях обоих подходов нетрудно обнаружить упор либо на объективность данных, либо на субъективность методов. Подход к информации как к объекту особой природы, возникающему в результате диалектического взаимодействия объективных данных с субъективными методами, позволяет во многих случаях снять противоречия, возникающие в философских обоснованиях ряда научных теорий и гипотез.
Свойства информации
Итак, информация является динамическим объектом, образующимся в момент взаимодействия объективных данных и субъективных методов. Как и всякий объект, она обладает свойствами (объекты различимы по своим свойствам). Характерной особенностью информации, отличающей ее от других объектов природы и общества, является отмеченный выше дуализм: на свойства информации влияют как свойства данных, составляющих ее содержательную часть, так и свойства методов, взаимодействующих с данными в ходе информационного процесса. По окончании процесса свойства информации переносятся на свойства новых данных, то есть свойства методов могут переходить на свойства данных.
Можно привести немало разнообразных свойств информации. Каждая научная дисциплина рассматривает те свойства, которые ей наиболее важны. С точки зрения информатики наиболее важными представляются следующие свойства: объективность, полнота, достоверность, адекватность, доступность и актуальность информации.
Объективность и субъективность информации. Понятие объективности информации является относительным. Это понятно, если учесть, что методы являются субъективными. Более объективной принято считать ту информацию, в которую методы вносят меньший субъективный элемент. Так, например, принято считать, что в результате наблюдения фотоснимка природного объекта или явления образуется более объективная информация, чем в результате наблюдения рисунка того же объекта, выполненного человеком. В ходе информационного процесса степень объективности информации всегда понижается. Это свойство учитывают, например, в правовых дисциплинах, где по-разному обрабатываются показания лиц, непосредственно наблюдавших события или получивших информацию косвенным путем (посредством умозаключений или со слов третьих лиц). В не меньшей степени объективность информации учитывают в исторических дисциплинах. Одни и те же события, зафиксированные в исторических документах разных стран и народов, выглядят совершенно по-разному. У историков имеются свои методы для тестирования объективности исторических данных и создания новых, более достоверных данных путем сопоставления, фильтрации и селекции исходных данных.
Обратим внимание на то, что здесь речь идет не о повышении объективности данных, а о повышении их достоверности (это совсем другое свойство).
Полнота информации. Полнота информации во многом характеризует качество информации и определяет достаточность данных для принятия решений или для создания новых данных на основе имеющихся. Чем полнее данные, тем шире диапазон методов, которые можно использовать, тем проще подобрать метод, вносящий минимум погрешностей в ход информационного процесса.
Достоверность информации. Данные возникают в момент регистрации сигналов, но не все сигналы являются «полезными» — всегда присутствует какой-то уровень посторонних сигналов, в результате чего полезные данные сопровождаются определенным уровнем «информационного шума». Если полезный сигнал зарегистрирован более четко, чем посторонние сигналы, достоверность информации может быть более высокой. При увеличении уровня шумов достоверность информации снижается. В этом случае для передачи того же количества информации требуется использовать либо больше данных, либо более сложные методы.
Адекватность информации — это степень соответствия реальному объективному состоянию дела. Неадекватная информация может образовываться при создании новой информации на основе неполных или недостоверных данных. Однако и полные, и достоверные данные могут приводить к созданию неадекватной информации в случае применения к ним неадекватных методов.
Доступность информации — мера возможности получить ту или иную информацию. На степень доступности информации влияют одновременно как доступность данных, так и доступность адекватных методов для их интерпретации. Отсутствие доступа к данным или отсутствие адекватных методов обработки данных приводят к одинаковому результату: информация оказывается недоступной. Отсутствие адекватных методов для работы с данными во многих случаях приводит к применению неадекватных методов, в результате чего образуется неполная, неадекватная или недостоверная информация.
Актуальность информации — это степень соответствия информации текущему моменту времени.Нередко с актуальностью, как и с полнотой, связывают коммерческую ценность информации. Поскольку информационные процессы растянуты во времени, то достоверная и адекватная, но устаревшая информация может приводить к ошибочным решениям. Необходимость поиска (или разработки) адекватного метода для работы с данными может приводить к такой задержке в получении информации, что она становится неактуальной и ненужной. На этом, в частности, основаны многие современные системы шифрования данных с открытым ключом. Лица, не владеющие ключом (методом) для чтения данных, могут заняться поиском ключа, поскольку алгоритм его работы доступен, но продолжительность этого поиска столь велика, что за время работы информация теряет актуальность и, соответственно, связанную с ней практическую ценность.
Информатика
Предмет и задачи информатики
Информатика — это техническая наука, систематизирующая приемы создания, хранения, воспроизведения, обработки и передачи данных средствами вычислительной техники, а также принципы функционирования этих средств и методы управления ими.
Из этого определения видно, что информатика очень близка к технологии, поэтому ее предмет нередко называют информационной технологией.
Предмет информатики составляют следующие понятия: в аппаратное обеспечение средств вычислительной техники; е программное обеспечение средств вычислительной техники; в средства взаимодействия аппаратного и программного обеспечения; средства взаимодействия человека с аппаратными и программными средствами.
Как видно из этого списка, в информатике особое внимание уделяется вопросам взаимодействия. Для этого даже есть специальное понятие — интерфейс. Методы и средства взаимодействия человека с аппаратными и программными средствами называют пользовательским интерфейсом. Соответственно, существуют аппаратные интерфейсы, программные интерфейсы и аппаратно-программные интерфейсы.
Основной задачей информатики является систематизация приемов и методов работы с аппаратными и программными средствами вычислительной техники. Цель систематизации состоит в выделении, внедрении и развитии передовых, наиболее эффективных технологий, в автоматизации этапов работы с данными, а также в методическом обеспечении новых технологических исследований.
Информатика — практическая наука. Ее достижения должны проходить подтверждение практикой и приниматься в тех случаях, когда они соответствуют критерию повышения эффективности. В составе основной задачи информатики сегодня можно выделить следующие направления для практических приложений:
· архитектура вычислительных систем (приемы и методы построения систем, предназначенных для автоматической обработки данных);
• интерфейсы вычислительных систем (приемы и методы управления аппаратным и программным обеспечением);
• программирование (приемы, методы и средства разработки компьютерных программ);
• преобразование данных (приемы и методы преобразования структур данных);
• защита информации (обобщение приемов, разработка методов и средств защиты данных);
• автоматизация (функционирование программно-аппаратных средств без участия человека);
• стандартизация (обеспечение совместимости между аппаратными и программ ными средствами, а также между форматами представления данных, относящихся к различным типам вычислительных систем).
На всех этапах технического обеспечения информационных процессов для информатики ключевым понятием является эффективность. Для аппаратных средств под эффективностью понимают отношение производительности оборудования к его стоимости (с учетом стоимости эксплуатации и обслуживания). Для программного обеспечения под эффективностью понимают производительность лиц, работающих с ними (пользователей). В программировании под эффективностью понимают объем программного кода, создаваемого программистами в единицу времени.
В информатике все жестко ориентировано на эффективность. Вопрос, как сделать ту или иную операцию, для информатики является важным, но не основным. Основным же является вопрос, как сделать данную операцию эффективно.
Истоки и предпосылки информатики
Слово информатика происходит от французского слова Informatique, образованного в результате объединения терминов Information (информация) и Automatique (автоматика), что выражает ее суть как науки об автоматической обработке информации. Кроме Франции термин информатика используется в ряде стран Восточной Европы. В то же время, в большинстве стран Западной Европы и США используется другой термин — Computer Science (наука о средствах вычислительной техники).
В качестве источников информатики обычно называют две науки—документалистику и кибернетику. Документалистика сформировалась в конце XIX века в связи с бурным развитием производственных отношений. Ее расцвет пришелся на 20-30-е годы XX века, а основным предметом стало изучение рациональных средств и методов повышения эффективности документооборота.
Основы близкой к информатике технической науки кибернетики были заложены трудами по математической логике американского математика Норберта Винера, опубликованными в 1948 году, а само название происходит от греческого слова (kyberneticos — искусный в управлении).
Впервые термин кибернетика ввел французский физик Андре Мари Ампер в первой половине XIX веке. Он занимался разработкой единой системы классификации всех наук и обозначил этим термином гипотетическую науку об управлении, которой в то время не существовало, но которая, по его мнению, должна была существовать.
Сегодня предметом кибернетики являются принципы построения и функционирования систем автоматического управления, а основными задачами — методы моделирования процесса принятия решений техническими средствами, связь между психологией человека и математической логикой, связь между информационным процессом отдельного индивидуума и информационными процессами в обществе, разработка принципов и методов искусственного интеллекта. На практике кибернетика во многих случаях опирается на те же программные и аппаратные средства вычислительной техники, что и информатика, а информатика, в свою очередь, заимствует у кибернетики математическую и логическую базу для развития этих средств.
Интернет Основные понятия
В дословном переводе на русский язык интернет — это межсеть, то есть в узком смысле слова интернет — это объединение сетей. Однако в последние годы у этого слова появился и более широкий смысл: Всемирная компьютерная сеть. Интернет можно рассматривать в физическом смысле как несколько миллионов компьютеров, связанных друг с другом всевозможными линиями связи, однако такой «физический» взгляд на Интернет слишком узок. Лучше рассматривать Интернет как некое информационное пространство.

Рис. 8.2. Простейшая модель службы передачи сообщений
Интернет — это не совокупность прямых соединений между компьютерами. Так, например, если два компьютера, находящиеся на разных континентах, обмениваются данными в Интернете, это совсем не значит, что между ними действует одно прямое или виртуальное соединение. Данные, которые они посылают друг другу, разбиваются на пакеты, и даже в одном сеансе связи разные пакеты одного сообщения могут пройти разными маршрутами. Какими бы маршрутами ни двигались пакеты данных, они все равно достигнут пункта назначения и будут собраны вместе в цельный документ. При этом данные, отправленные позже, могут приходить раньше, но это не помешает правильно собрать документ, поскольку каждый пакет имеет свою маркировку.
Таким образом, Интернет представляет собой как бы «пространство», внутри которого осуществляется непрерывная циркуляция данных. В этом смысле его можно сравнить с теле- и радиоэфиром, хотя есть очевидная разница хотя бы в том, что в эфире никакая информация храниться не может, а в Интернете она перемещается между компьютерами, составляющими узлы сети, и какое-то время хранится на их жестких дисках.
Теоретические основы Интернета
Ранние эксперименты по передаче и приему информации с помощью компьютеров начались еще в 50-х годах и имели лабораторный характер. Лишь в конце 60-х годов на средства Агентства Перспективных Разработок министерства обороны США (DARPA — Defense Advanced Research Project Agency) была создана первая сеть национального масштаба.
По имени агентства она получила название ARPANET. Эта сеть связала несколько крупных научных, исследовательских и образовательных центров. Ее основной задачей стала координация групп коллективов, работающих над едиными научно-техническими проектами, а основным назначением стал обмен электронной почтой и файлами с научной и проектно-конструк-торской документацией.
Сеть ARPANET заработала в 1969 году. Немногочисленные узлы, входившие в нее в то время, были связаны выделенными линиями. Прием и передача информации обеспечивались программами, работающими на узловых компьютерах. Сеть постепенно расширялась за счет подключения новых узлов, а к началу 80-х годов на базе наиболее крупных узлов были созданы свои региональные сети, воссоздающие общую архитектуру ARPANET па более низком уровне (в региональном или локальном масштабе).
Всякий раз, когда мы говорим о вычислительной технике, нам надо иметь в виду принцип единства аппаратного и программного обеспечения. Пока глобальное расширение ARPANET происходило за счет механического подключения все новых и новых аппаратных средств (узлов и сетей), до Интернета в современном понимании этого слова было еще очень далеко. По-настоящему рождением Интернета принято считать 1983 год. В этом году произошли революционные изменения в программном обеспечении компьютерной связи. Днем рождения Интернета в современном понимании этого слова стала дата стандартизация протокола связи TCP/IP, лежащего в основе Всемирной сети по нынешний день.
Здесь требуется уточнить, что в современном понимании TCP/IP — это не один сетевой протокол, а два протокола, лежащих на разных уровнях (это так называемый стек протоколов). Протокол TCP — протокол транспортного уровня. Он управляет тем, как происходит передача информации. Протокол IP — адресный. Он принадлежит сетевому уровню и определяет, куда происходит передача.
Протокол TCP. Согласно протоколу TCP, отправляемые данные «нарезаются» на небольшие пакеты, после чего каждый пакет маркируется таким образом, чтобы в нем были данные, необходимые для правильной сборки документа на компьютере получателя.
Для понимания сути протокола TCP можно представить игру в шахматы по переписке, когда двое участников разыгрывают одновременно десяток партий. Каждый ход записывается на отдельной открытке с указанием номера партии и номера хода. В этом случае между двумя партнерами через один и тот же почтовый канал работает как бы десяток соединений (по одному на партию). Два компьютера, связанные между собой одним физическим соединением, могут точно так же поддерживать одновременно несколько ГСР-соединений. Так, например, два промежуточных сетевых сервера могут одновременно по одной линии связи передавать друг другу в обе стороны множество ГСР-пакетов от многочисленных клиентов.
Протокол IP. Теперь рассмотрим адресный протокол - IP (Internet Protocol). Его суть состоит в том, что у каждого участника Всемирной сети должен быть свой уникальный адрес (IP-адрес). Без этого нельзя говорить о точной доставке TСР-пакетов на нужное рабочее место. Этот адрес выражается очень просто — четырьмя байтами, например: 195.38.46.11. Структуру IP-адреса, мы рассматривать в этом пособии не будем, но она организована так, что каждый компьютер, через который проходит какой-либо TСР-пакет, может по этим четырем числам определить, кому из ближайших «соседей» надо переслать пакет, чтобы он оказался «ближе» к получателю. В результате конечного числа перебросок ГСР-пакет достигает адресата. Выше мы не случайно взяли в кавычки слово «ближе». В данном случае оценивается не географическая «близость». В расчет принимаются условия связи и пропускная способность линии. Два компьютера, находящиеся на разных континентах, но связанные высокопроизводительной линией космической связи, считаются более «близкими» друг к другу, чем два компьютера из соседних поселков, связанные простым телефонным проводом. Решением вопросов, что считать «ближе», а что «дальше», занимаются специальные средства — маршрутизаторы. Роль маршрутизатора в сети может выполнять как специализированный компьютер, так и специальная программа, работающая на узловом сервере сети.
Поскольку один байт содержит до 256 различных значений, то теоретически с помощью четырех байтов можно выразить более четырех миллиардов уникальных IP-адресов (2564 за вычетом некоторого количества адресов, используемых в качестве служебных). На практике же из-за особенностей адресации к некоторым типам локальных сетей количество возможных адресов составляет порядка двух миллиардов, но и это по современным меркам достаточно большая величина.
Службы Интернета
Когда говорят о работе в Интернете или об использовании Интернета, то на самом деле речь идет не об Интернете в целом, а только об одной или нескольких из его многочисленных служб. В зависимости от конкретных целей и задач клиенты Сети используют те службы, которые им необходимы.
Разные службы имеют разные протоколы. Они называются прикладными протоколами. Их соблюдение обеспечивается и поддерживается работой специальных программ. Таким образом, чтобы воспользоваться какой-то из служб Интернета, необходимо установить на компьютере программу, способную работать по протоколу данной службы. Такие программы называют клиентскими или просто клиентами.
Так, например, для передачи файлов в Интернете используется специальный прикладной протокол FTP (File Transfer Protocol). Соответственно, чтобы получить из Интернета файл, необходимо:
• иметь на компьютере программу, являющуюся клиентом FTP (FTP-клиент);
• установить связь с сервером, предоставляющим услуги FTP (FTP-сервером).
Другой пример: чтобы воспользоваться электронной почтой, необходимо соблюсти протоколы отправки и получения сообщений. Для этого надо иметь программу (почтовый клиент) и установить связь с почтовым сервером. Так же обстоит дело и с другими службами.
Терминальный режим. Исторически одной из ранних является служба удаленного управления компьютером Telnet. Подключившись к удаленному компьютеру по протоколу этой службы, можно управлять его работой. Такое управление еще называют консольным или терминальным. В прошлом эту службу широко использовали для проведения сложных математических расчетов на удаленных вычислительных центрах.
Так, например, если для очень сложных вычислений на персональном компьютере требовались недели непрерывной работы, а на удаленной супер-ЭВМ всего несколько минут, то персональный компьютер применяли для удаленного ввода данных в ЭВМ и для приема полученных результатов.
В наши дни в связи с быстрым увеличением мощности персональных компьютеров необходимость в подобной услуге сократилась, но, тем не менее, службы Telnet в Интернете продолжают существовать. Часто протоколы Telnet применяют для дистанционного управления техническими объектами, например телескопами, видеокамерами, промышленными роботами.
Мы не указываем названия основных Telnet-клиентов, поскольку каждый сервер, предоставляющий Telnet-услуги, обычно предлагает свое клиентское приложение. Его надо получить по сети (например, по протоколу FTP, см. ниже), установить на своем компьютере, подключиться к серверу и работать с удаленным оборудованием. Простейший клиент Telnet входит в состав операционной системы Windows 98 (файл telnet.exe).
Электронная почта (E-Mail). Эта служба также является одной из наиболее ранних. Ее обеспечением в Интернете занимаются специальные почтовые серверы. Обратите внимание на то, что когда мы говорим о каком-либо сервере, не имеется в виду, что это специальный выделенный компьютер. Здесь и далее под сервером может пониматься программное обеспечение. Таким образом, один узловой компьютер Интернета может выполнять функции нескольких серверов и обеспечивать работу различных служб, оставаясь при этом универсальным компьютером, на котором можно выполнять и другие задачи, характерные для средств вычислительной техники.
Почтовые серверы получают сообщения от клиентов и пересылают их по цепочке к почтовым серверам адресатов, где эти сообщения накапливаются. При установлении соединения между адресатом и его почтовым сервером происходит автоматическая передача поступивших сообщений на компьютер адресата.
Почтовая служба основана на двух прикладных протоколах: SMTP и РОРЗ. По первому происходит отправка корреспонденции с компьютера на сервер, а по второму — прием поступивших сообщений.
Существует большое разнообразие клиентских почтовых программ. К ним относится, например, программа Microsoft Outlook Express, входящая в состав операционной системы Windows 98 как стандартная. Более мощная программа, интегрирующая в себе кроме поддержки электронной почты и другие средства делопроизводства, Microsoft Outlook 2000, входит в состав известного пакета Microsoft Office 2000. Из специализированных почтовых программ хорошую популярность имеют программы The Bat! и Eudora Pro.
Списки рассылки (Mail List). Обычная электронная почта предполагает наличие двух партнеров по переписке. Если же партнеров нет, то достаточно большой поток почтовой информации в свой адрес можно обеспечить, подписавшись на списки рассылки. Это специальные тематические серверы, собирающие информацию по определенным темам и переправляющие ее подписчикам в виде сообщений электронной почты.
Темами списков рассылки может быть что угодно, например вопросы, связанные с изучением иностранных языков, научно-технические обзоры, презентация новых программных и аппаратных средств вычислительной техники (рис. 8.3). Большинство телекомпаний создают списки рассылки на своих узлах, через которые рассылают клиентам аннотированные обзоры телепрограмм. Списки рассылки позволяют эффективно решать вопросы регулярной доставки данных.

Рис. 8.3. Список рассылки, посвященный отечественным
железным дорогам
Служба телеконференций (Usenet). Служба телеконференций похожа на циркулярную рассылку электронной почты, в ходе которой одно сообщение отправляется не одному корреспонденту, а большой группе (такие группы называются телеконференциями или группами новостей).
Обычное сообщение электронной почты пересылается по узкой цепочке серверов от отправителя к получателю. При этом не предполагается его хранение на промежуточных серверах. Сообщения, направленные на сервер группы новостей, отправляются с него на все серверы, с которыми он связан, если на них данного сообщения еще нет.
Далее процесс повторяется. Характер распространения каждого отдельного сообщения напоминает лесной пожар.
На каждом из серверов поступившее сообщение хранится ограниченное время (обычно неделю), и все желающие могут в течение этого времени с ним ознакомиться. Распространяясь во все стороны, менее чем за сутки сообщения охватывают весь земной шар. Далее распространение затухает, поскольку на сервер, который уже имеет данное сообщение, повторная передача производиться не может.
Ежедневно в мире создается порядка миллиона сообщений для групп новостей. Выбрать в этом массиве действительно полезную информацию практически невозможно. Поэтому вся система телеконференций разбита на тематические группы. Сегодня в мире насчитывают порядка 50 000 тематических групп новостей. Они охватывают большинство тем, интересующих массы. Особой популярностью пользуются группы, посвященные вычислительной технике.
Основной прием использования групп новостей состоит в том, чтобы задать вопрос, обращаясь ко всему миру, и получить ответ или совет от тех, кто с этим вопросом уже разобрался. При этом важно следить за тем, чтобы содержание вопроса соответствовало теме данной телеконференции. Многие квалифицированные специалисты мира (конструкторы, инженеры, ученые, врачи, педагоги, юристы, писатели, журналисты, программисты и прочие) регулярно просматривают сообщения телеконференций, проходящие в группах, касающихся их сферы деятельности. Такой просмотр называется мониторингом информации. Регулярный мониторинг позволяет специалистам точно знать, что нового происходит в мире по их специальности, какие проблемы беспокоят большие массы людей и на что надо обратить особое внимание в своей работе.
В современных промышленных и проектно-конструкторских организациях считается хорошим тоном, если специалисты высшего эшелона периодически (один-два раза в месяц) отвечают через систему телеконференций на типовые вопрос» пользователей своей продукции. Так, например, в телеконференциях, посвященных легковым автомобилям, нередко можно найти сообщения от главных конструкторов крупнейших промышленных концернов.
При отправке сообщений в телеконференции принято указывать свой адрес электронной почты для обратной связи. В тех случаях, когда есть угроза переполнения электронного «почтового ящика» корреспонденцией, не относящейся непосредственно к производственной деятельности, вместо основного адреса, используемого для деловой переписки, указывают дополнительный адрес. Как правило, такой адрес арендуют на сервере одной из бесплатных анонимных почтовых служб, например www.hotmail.com.
Огромный объем сообщений в группах новостей значительно затрудняет их целенаправленный мониторинг, поэтому в некоторых группах производится предварительный «отсев» бесполезной информации (в частности, рекламной), не относящейся к теме конференции. Такие конференции называют модерируемыми. В качестве модератора может выступать не только человек, но и программа, фильтрующая сообщения по определенным ключевым словам. В последнем случае говорят об автоматической модерации.
Для работы со службой телеконференций существуют специальные клиентские программы. Так, например, приложение Microsoft Outlook Express, указанное выше как почтовый клиент, позволяет работать также и со службой телеконференций. Для начала работы надо настроить программу на взаимодействие с сервером групп новостей, оформить «подписку» на определенные группы и периодически, как и электронную почту, получать все сообщения, проходящие по теме этой группы. В данном случае слово «подписка» не предполагает со стороны клиента никаких обязательств или платежей — это просто указание серверу о том, что сообщения по указанным темам надо доставлять, а по прочим — нет. Отменить подписку или изменить ее состав можно в любой удобный момент.
Служба World Wide Web (WWW). Безусловно, это самая популярная служба современного Интернета. Ее нередко отождествляют с Интернетом, хотя на самом деле это лишь одна из его многочисленных служб.
World Wide Web — это единое информационное пространство, состоящее из сотен миллионов взаимосвязанных электронных документов, хранящихся на Web-cepвepax. Отдельные документы, составляющие пространство Web, называют Web-страницами. Группы тематически объединенных Web-страниц называют Web-узлами (жаргонный термин — Web-сайт или просто сайт). Один физический Web-сервер может содержать достаточно много Web-узлов, каждому из которых, как правило, отводится отдельный каталог на жестком диске сервера.
От обычных текстовых документов Web- страницы отличаются тем, что они оформлены без привязки к конкретному носителю. Например, оформление документа, напечатанного на бумаге, привязано к параметрам печатного листа, который имеет определенную ширину, высоту и размеры полей. Электронные Web-документы предназначены для просмотра на экране компьютера, причем заранее не известно на каком. Неизвестны ни размеры экрана, ни параметры цветового и графического разрешения, неизвестна даже операционная система, с которой работает компьютер клиента. Поэтому Web-документы не могут иметь «жесткого» форматирования. Оформление выполняется непосредственно во время их воспроизведения на компьютере клиента и происходит оно в соответствии с настройками программы, выполняющей просмотр.
Программы для просмотра Web-страниц называют броузерами. В литературе также можно встретить «неустоявшиеся» термины браузер или обозреватель. Во всех случаях речь идет о некотором средстве просмотра Web-документов.
Броузер выполняет отображение документа на экране, руководствуясь командами, которые автор документа внедрил в его текст (если автор применяет автоматические средства подготовки Web-документов, необходимые команды внедряются автоматически). Такие команды называются тегами. От обычного текста они отличаются тем, что заключены в угловые скобки. Большинство тегов используются парами: открывающий тег и закрывающий. Закрывающий тег начинается с символа «/»•
<CENTER> Этот текст должен выравниваться по центру экрана </CENTER>
<LEFT> Этот текст выравнивается полевой границе экрана </LEFT> <RIGHT> Этот текст выравнивается по правой границе экрана </RIGHT>
Сложные теги имеют кроме ключевого слова дополнительные атрибуты и параметры, детализирующие способ их применения. Правила записи тегов содержатся в спецификации особого языка разметки, близкого к языкам программирования. Он называется языком разметки гипертекста — HTML (HyperText Markup Language). Таким образом, Web-документ представляет собой обычный текстовый документ, размеченный тегами HTML. Такие документы также называют HTML-документами или документами в формате HTML.
При отображении ЯГМ£-документа на экране с помощью броузера теги не показываются, и мы видим только текст, составляющий документ. Однако оформление этого текста (выравнивание, цвет, размер и начертание шрифта и прочее) выполняется в соответствии с тем, какие теги имплантированы в текст документа.
Существуют специальные теги для внедрения графических и мультимедийных объектов (звук, музыка, видеоклипы). Встретив такой тег, обозреватель делает запрос к серверу на доставку файла, связанного с тегом, и воспроизводит его в соответствии с заданными атрибутами и параметрами тега — мы видим иллюстрацию или слышим звук. Более подробно вопросы создания Web-страниц и использования тегов HTML рассмотрены в главе «Подготовка и публикация Web-документов».
В последние годы в Web-документах находят широкое применение так называемые активные компоненты. Это тоже объекты, но они содержат не только текстовые, графические и мультимедийные данные, но и программный код, то есть могут не просто отображаться на компьютере клиента, но и выполнять на нем работу по заложенной в них программе. Для того чтобы активные компоненты не могли выполнить на чужом компьютере разрушительные операции (что характерно для «компьютерных вирусов»), они исполняются только под контролем со стороны броузера. Броузер не должен допустить исполнения команд, несущих потенциальную угрозу, например он пресекает попытки осуществить операции с жестким диском.
Возможность внедрения в текст графических и других объектов, реализуемая с помощью тегов HTML, является одной из самых эффектных с точки зрения оформления Web-страниц, но не самой важной с точки зрения самой идеи World Wide Web. Наиболее важной чертой Web-страниц, реализуемой с помощью тегов HTML, являются гипертекстовые ссылки. С любым фрагментом текста или, например, с рисунком с помощью тегов можно связать иной Web-документ, то есть установить гиперссылку. В этом случае при щелчке левой кнопкой мыши на тексте или рисунке, являющемся гиперссылкой, отправляется запрос на доставку нового документа.
Этот документ, в свою очередь, тоже может иметь гиперссылки на другие документы.
Таким образом, совокупность огромного числа гипертекстовых электронных документов, хранящихся на серверах WWW, образует своеобразное гиперпространство документов, между которыми возможно перемещение. Произвольное перемещение между документами в Web-пространстве называют Web-серфингом (выполняется с целью ознакомительного просмотра). Целенаправленное перемещение между Web-документами называют Web-навигацией (выполняется с целью поиска нужной информации).
Гипертекстовая связь между сотнями миллионов документов, хранящихся на физических серверах Интернета, является основой существования логического пространства World Wide Web. Однако такая связь не могла бы существовать, если бы каждый документ в этом пространстве не обладал своим уникальным адресом. Выше мы говорили, что каждый файл одного локального компьютера обладает уникальным полным именем, в которое входит собственное имя файла (включая расширение имени) и путь доступа к файлу, начиная от имени устройства, на котором он хранится. Теперь мы можем расширить представление об уникальном имени файла и развить его до Всемирной сети. Адрес любого файла во всемирном масштабе определяется унифицированным указателем ресурса — URL.

Рис. 8.4. Web-страница отечественного предприятия
Адрес URL состоит из трех частей.
1.Указание службы, которая осуществляет доступ к данному ресурсу (обычно обозначается именем прикладного протокола, соответствующего данной службе. Так, например, для службы WWW прикладным является протокол HTTP (HyperText Transfer Protocol — протокол передачи гипертекста). После имени протокола ставится двоеточие (:) и два знака «/» (косая черта):
http://...
2. Указание доменного имени компьютера (сервера), на котором хранится данный ресурс:
http://www.abcde.com...
3. Указания полного пути доступа к файлу на данном компьютере. В качестве разделителя используется символ «/» (косая черта):
http://www.abcde.com/Files/New/abcdefg.zip
При записи URL- адреса важно точно соблюдать регистр символов. В отличие от правил работы в MS-DOS и Windows, в Интернете строчные и прописные символы считаются разными.
Именно в форме URL и связывают адрес ресурса с гипертекстовыми ссылками на Web-страницах. При щелчке на гиперссылке броузер посылает запрос для поиска и доставки ресурса, указанного в ссылке. Если по каким-то причинам он не найден, выдается сообщение о том, что ресурс недоступен (возможно, что сервер временно отключен или изменился адрес ресурса).
Служба имен доменов (DNS). Когда мы говорили о протоколах Интернета, то сказали, что адрес любого компьютера или любой локальной сети в Интернете может быть выражен четырьмя байтами, например так:
195.28.132.97
А только что мы заявили, что каждый компьютер имеет уникальное доменное имя, например такое:
www.abcdef.com
Нет ли здесь противоречия?
Противоречия здесь нет, поскольку это просто две разных формы записи адреса одного и того же сетевого компьютера. Человеку неудобно работать с числовым представлением IР-адреса, зато доменное имя запоминается легко, особенно если учесть, что, как правило, это имя имеет содержание. Например, Web-сервер компании Microsoft имеет имя www.microsoft.com, а Web-сервер компании «Космос ТВ» имеет имя www.kosmostv.ru (суффикс .ru в конце имени говорит о том, что сервер компании принадлежит российскому сектору Интернета). Нетрудно «реконструировать» и имена для других компаний.
С другой стороны, автоматическая работа серверов сети организована с использованием четырехзначного числового адреса. Благодаря ему промежуточные серверы могут осуществлять передачу запросов и ответов в нужном направлении, не зная, где конкретно находятся отправитель и получатель. Поэтому необходим перевод доменных имен в связанные с ними /Р-адреса. Этим и занимаются серверы службы имен доменов DNS. Наш запрос на получение одной из страниц сервера www.abcde.com сначала обрабатывается сервером DNS, и далее он направляется по IР-адресу, а не по доменному имени.
Служба передачи файлов (FTP). Прием и передача файлов составляют значительный процент от прочих Интернет-услуг. Необходимость в передаче файлов возникает, например, при приеме файлов программ, при пересылке крупных документов (например, книг), а также при передаче архивных файлов, в которых запакованы большие объемы информации.
Служба FTP имеет свои серверы в мировой сети, на которых хранятся архивы данных. Со стороны клиента для работы с серверами FTP может быть установлено специальное программное обеспечение, хотя в большинстве случаев броузеры WWW обладают встроенными возможностями для работы и по протоколу FTP.
Протокол FTP работает одновременно с двумя ГСР-соединениями между сервером и клиентом. По одному соединению идет передача данных, а второе соединение используется как управляющее. Протокол FTP также предоставляет серверу средства для идентификации обратившегося клиента. Этим часто пользуются коммерческие серверы и серверы ограниченного доступа, поставляющие информацию только зарегистрированным клиентам, — они выдают запрос на ввод имени пользователя и связанного с ним пароля. Однако существуют и десятки тысяч РТР-серверов с анонимным доступом для всех желающих. В этом случае в качестве имени пользователя надо ввести слово: anonymous, а в качестве пароля задать адрес электронной почты. В большинстве случаев программы-клиенты FTP делают это автоматически.
IRC. Служба IRC (Internet Relay Chat) предназначена для прямого общения нескольких человек в режиме реального времени. Иногда службу IRC называют чат-конференциями или просто чатом. В отличие от системы телеконференций, в которой общение между участниками обсуждения темы открыто всему миру, в системе IRC общение происходит только в пределах одного канала, в работе которого принимают участие обычно лишь несколько человек. Каждый пользователь может создать собственный канал и пригласить в него участников «беседы» или присоединиться к одному из открытых в данный момент каналов.
Существует несколько популярных клиентских программ для работы с серверами и сетями, поддерживающими сервис IRC. Одна из наиболее популярных — программа mlRC.exe.
ICQ, Эта служба предназначена для поиска сетевого IP-адреса человека, подключенного в данный момент к Интернету. Необходимость в подобной услуге связана с тем, что большинство пользователей не имеют постоянного IP-адреса. Название службы является акронимом выражения / seek you — я тебя ищу. Для пользования этой службой надо зарегистрироваться на ее центральном сервере (http://www.icq.com) и получить персональный идентификационный номер UIN (Universal Internet Number). Данный номер можно сообщить партнерам по контактам, и тогда служба ICQ приобретает характер Интернет-пейджера. Зная номер UIN партнера, но не зная его текущий IP-адрес, можно через центральный сервер службы отправить ему сообщение с предложением установить соединение.
Как было указано выше, каждый компьютер, подключенный к Интернету, должен иметь четырехзначный IP-адрес. Этот адрес может быть постоянным или динамически временным. Те компьютеры, которые включены в Интернет на постоянной основе, имеют постоянные IP-адреса. Большинство же пользователей подключаются к Интернету лишь на время сеанса. Им выдается динамический IP-адрес, действующий только в течение данного сеанса. Этот адрес выдает тот сервер, через который происходит подключение. В разных сеансах динамический IP-адрес может быть различным, причем заранее неизвестно каким.
При каждом подключении к Интернету программа ICQ, установленная на нашем компьютере, определяет текущий IP-адрес и сообщает его центральной службе, которая, в свою очередь, оповещает наших партнеров по контактам. Далее наши партнеры (если они тоже являются клиентами данной службы) могут установить с нами прямую связь. Программа предоставляет возможность выбора режима связи («готов к контакту»; «прошу не беспокоить, но готов принять срочное сообщение»; «закрыт для контакта» и т. п.). После установления контакта связь происходит в режиме, аналогичном сервису IRC.
Использование Главного меню
Структура Главного меню
Главное меню — один из основных системных элементов управления Windows 98. Оно отличается тем, что независимо от того, насколько Рабочий стол перегружен окнами запущенных процессов, доступ к Главному меню удобен всегда — оно открывается щелчком на кнопке Пуск. С помощью Главного меню можно запустить все программы, установленные под управлением операционной системы или зарегистрированные в ней, открыть последние документы, с которыми выполнялась работа, получить доступ ко всем средствам настройки операционной системы, а также доступ к поисковой и справочной системам Windows 98.
Главное меню — необходимый элемент управления для завершения работы с операционной системой. В нем имеется пункт Завершение работы, использование которого необходимо для корректного завершения работы с системой перед выключением питания.
В структуру Главного меню входят два раздела — обязательный и произвольный. Произвольный раздел расположен выше разделительной черты. Пункты этого раздела пользователь может создавать по собственному желанию. Иногда эти пункты образуются автоматически при установке некоторых приложений. Структура обязательного раздела Главного меню представлена в таблице 5.1.