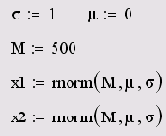Математический редактор MathCAD
14.1.1. Нормальное (Гауссово) распределение
В теории вероятности доказано, что сумма различных независимых случайных слагаемых (независимо от их закона распределения) оказывается случайной величиной, распределенной согласно нормальному закону (т. н. центральная предельная теорема). Поэтому нормальное распределение хорошо моделирует самый широкий круг явлений, для которых известно, что на них влияют несколько независимых случайных факторов.
Перечислим встроенные функции, имеющиеся в Mathcad для описания нормального распределения вероятностей:
- dnorm(x,m,o) — плотность вероятности нормального распределения;
- рпогт(х,m,о) —функция нормального распределения;
- спогт(х) —функция нормального распределения для ц= о,o=i;
- дпогт(P,m,о) — обратная функция нормального распределения;
- гпогт(M,m,o) — вектор м независимых случайных чисел, каждое из которых имеет нормальное распределение;
- х — значение случайной величины;
- Р — значение вероятности;
- m— математическое ожидание;
- о — среднеквадратичное отклонение.
Математическое ожидание и дисперсия являются, по сути, параметрами распределения. Плотность распределения для трех пар значений параметров показана на рис. 14.1. Напомним, что плотность распределения dnorm задает вероятность попадания случайной величины х в малый интервал от х до х+dх. Таким образом, например, для первого графика (сплошная линия) вероятность того, что случайная величина х примет значение в окрестности нуля, приблизительно в три раза больше, чем вероятность того, что она примет значение в окрестности х=2. А значения случайной величины, большие 5 и меньшие -5, и вовсе маловероятны.
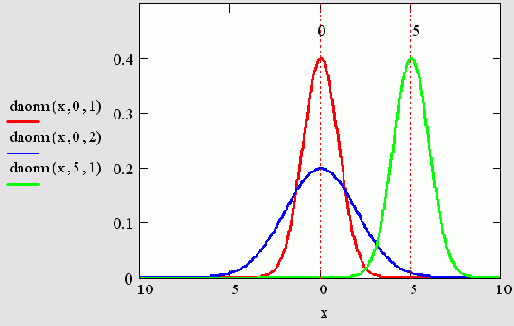
Рис. 14.1. Плотность вероятности нормальных распределений
Функция распределения F(X) (cumulative probability) — это вероятность того, что случайная величина примет значение меньшее или равное х. Как следует из математического смысла, она является интегралом от плотности вероятности в пределах от -x до х. Функции распределения для упомянутых нормальных законов изображены на рис. 14.2. Функция, обратная F(X) (inverse cumulative probability), называемая еще квантилем распределения, позволяет по заданному аргументу р определить значение х, причем случайная величина будет меньше или равна х с вероятностью р.
Здесь и далее графики различных статистических функций, показанные на рисунках, получены с помощью Mathcad без каких-либо дополнительных выражений в рабочей области.
Приведем несколько примеров, позволяющих почувствовать математический смысл рассмотренных функций на примере случайной величины х, распределенной по нормальному закону с m=0 и o=1 (листинги 14.1—14.5).
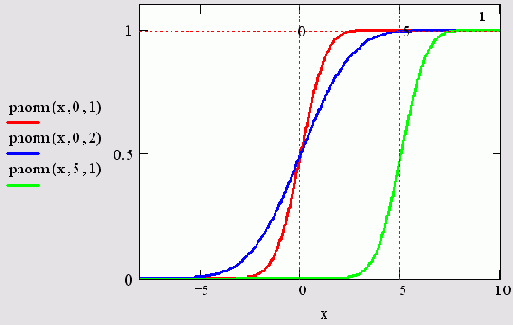
Рис. 14.2. Нормальные функции распределения
Листинг 14.1. Вероятность того, что х будет меньше 1.881
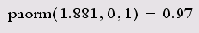
Листинг 14.2. 97%-ный квантиль нормального распределения
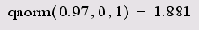
Листинг 14.3. Вероятность того, что х будет больше 2
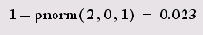
Листинг 14.4. Вероятность того, что ж будет находиться в интервале (2,3)
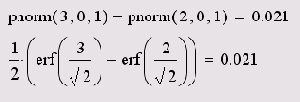
Листинг 14.5. Вероятность того, что | х|<2

Обратите внимание, что задачи двух последних листингов решаются двумя разными способами. Второй из них связан с еще одной встроенной функцией erf, называемой функцией ошибок (или интегралом вероятности, или функцией Крампа).
- erf (x) — функция ошибок;
- erfc(x)=1-erf(x).
Математический смысл функции ошибок ясен из листинга 14.5. Интеграл вероятности имеет всего один аргумент, в отличии от функции нормального распределения. Исторически, последняя пересчитывалась через табулированный интеграл вероятности по формулам, приведенным в листинге 14.6 для произвольных значений параметров m и o (листинг 14.6).
Листинг 14.6. Вероятность того, чтохбудвтвинтврвалв (2,3)
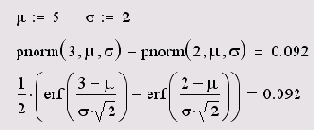
Если Вы имеете дело с моделированием методами Монте-Карло, то в качестве генератора случайных чисел с нормальным законом распределения применяйте встроенную функцию топа. В листинге 14.7 ее действие показано на примере создания двух векторов по M=500 элементов в каждом с независимыми псевдослучайными числами xLi и х2i распределенными согласно нормальному закону. О характере распределения случайных элементов векторов можно судить по рис. 14.3. В дальнейшем мы будем часто сталкиваться с генерацией случайных чисел и расчетом их различных средних характеристик.
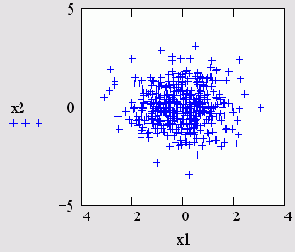
Рис. 14.3. Псевдослучайные числа с нормальным законом распределения (листинг 14.7)
Листинг 14.7. Генерация двух векторов с нормальным законом распределения